A platform for building AI, ML, & Computer Vision pipelines using real-time sensing data
INFINIWORKFLOW runs in a browser with the following main UI components

The application menu allows the following functionality
The tool catalog allows you to add new tools as nodes into your flowgraph
The first tab will show all the tools and the remaining tabs show a subset of tools such as related to computer vision or ML etc. You can hover over the tab icon and a tooltip will show you the category name. Once a category tab is selected you can further refine the list of tools shown by entering keywords input, this is useful to quickly find a particular tool you want to insert into your workflow.
Hovering over the tools shows a tooltip description of the tool. To insert a tool into the workflow can be done with the following gestures:
Drag and Drop
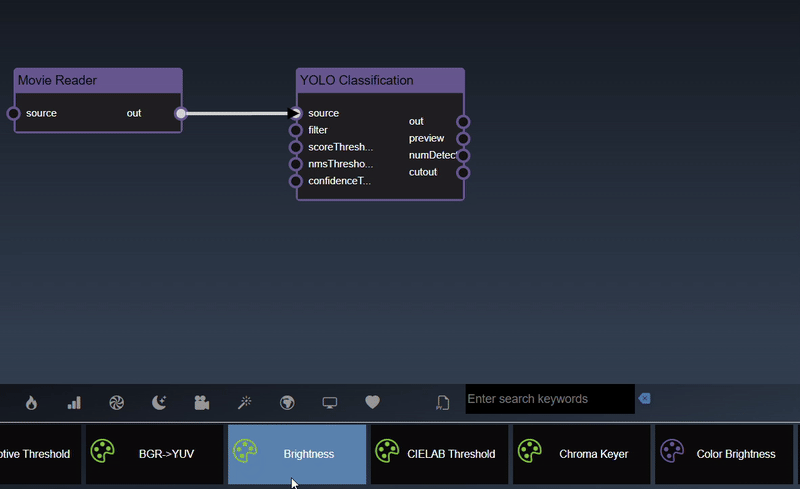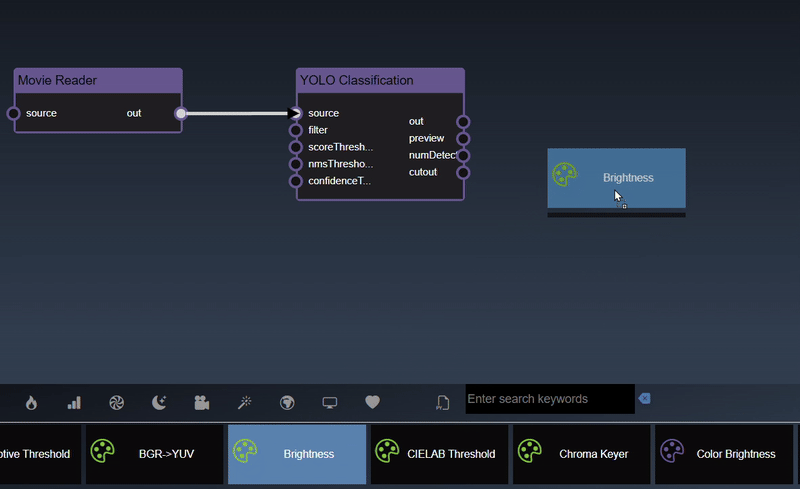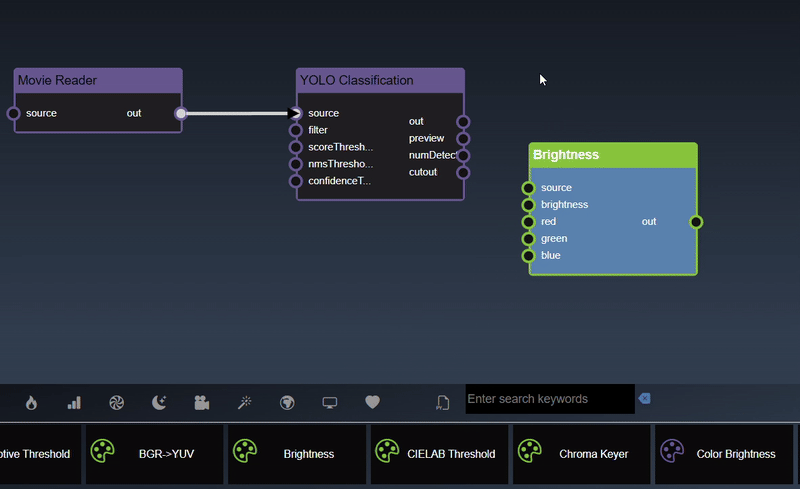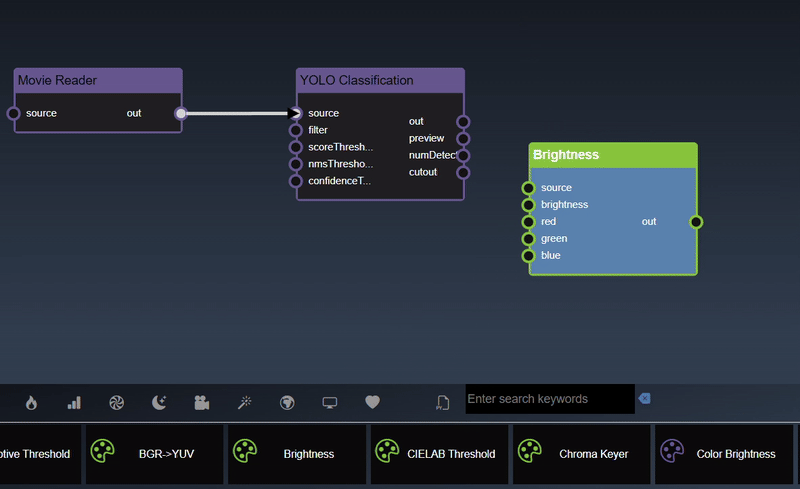
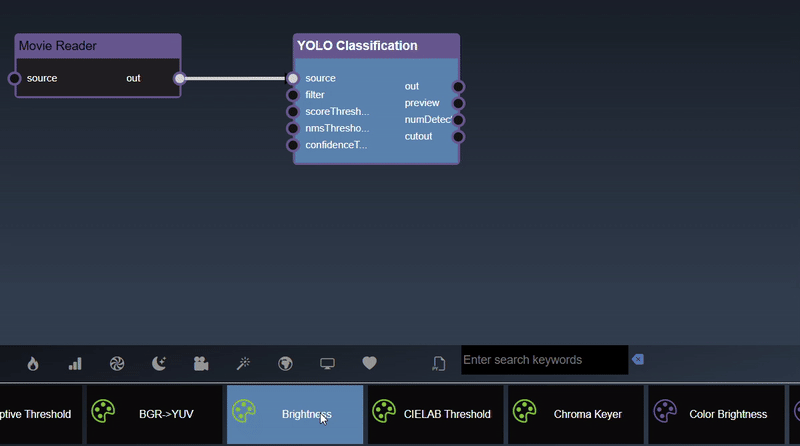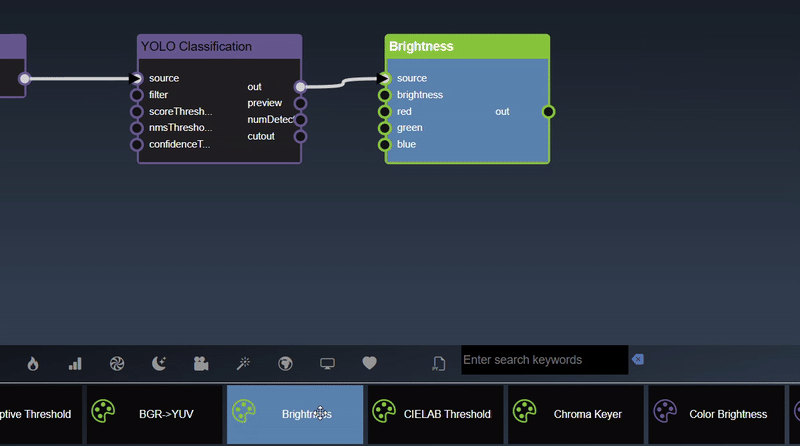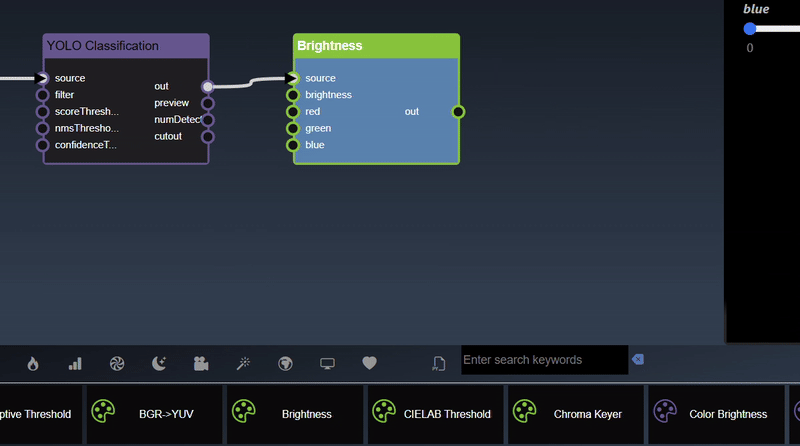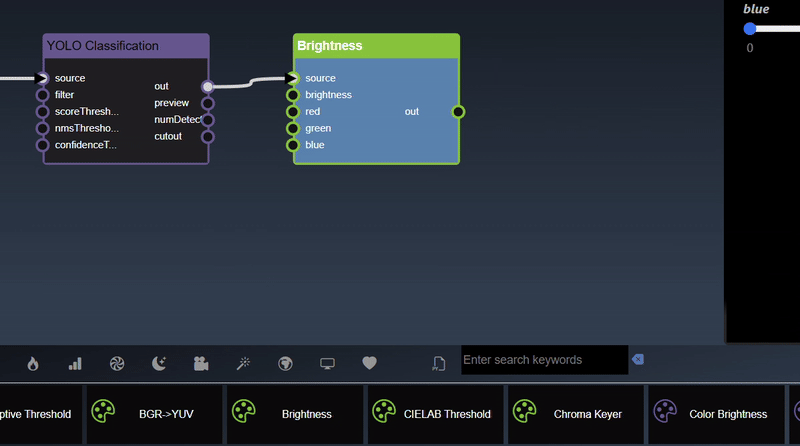
Insert a node with edge automatically can be done by selecting the node you wish to connect it to and then double clicking the tool - a new node will be inserted and a link will automatically be added as well.
Infiniworkflow has several hundred nodes avaialble, which allows for many possibilities but also can be daunting for new users or can stand in the way of users who are only looking to build a specific application (if you are building a Data Science workflow, you probably don't need to see the many Color Correction nodes that are available). As such, Layouts have been added as a feature for controlling which categories and nodes show up in your Tool Catalog. They are straightforward to use, but by no means necessary to learn about if you do not wish to change how your Tool Catalog appears, so you may skip this section and not lose any critical information.
Layout can be defined as a set of categories, and the respective nodes inside them, that will appear within the Tool Bar if the Layout is selected. You can switch between Layouts by clicking on the Layouts button, found in the bottom right corner of the screen (see video below). By default the Layout is "All", as that shows all categories and all nodes inside those categories. However, this is but 1 of a handful of pre-made Layouts that are available. These pre-made Layouts include "Computer Vision", "Data Science", and "Machine Learning"; as can be expected, when we switch to one of those Layouts, only the categories / nodes relevant to the respective topic (Computer Vision, for example) will appear. The video below showcases how the toolbar changes when switching between Layouts.
In addition to the Layouts seen here, users can also choose to add their own custom Layouts. To add a Layout, go to Settings, which can be found in the bottom right side by the Layouts button, and click on the "New Layouts" option within Settings. Enter in your Layout name, and save. If you click on the Layouts button now, you will now see that you new Layout has been added to the list of other Layouts. These steps are showcased below.
To begin changing how the categories / nodes appear within your Layout's Tool Catalog, click on the Layouts button and then click on the Layout you wish to change. Now that you're in, you may begin moving both categories and nodes as you like. The following operations are possible:
I. Moving single Nodes into the Trash (these nodes will no longer show up in the category they were in previously):
II. Moving an entire Category to the Trash (the entire category will no longer be in view, and all nodes within the category will go to the Trash):
III. Moving single Nodes into different Categories (the Node's symbol will be unchanged, but the Node itself will now belong to the new category):
IV. Moving an entire Category into another Category (the second Category will be the only one to appear in the Categories list on the top of the Tools Catalog, but all nodes within both categories can now be found in this Category):
If you are unhappy with your Layout and want to start over, simply go to the Settings button and click on the "Reset Layout" button. Alternatively, you may delete the Layout all together by clicking on the "Delete Layout" button within Settings. NOTE: Make sure that you are IN the Layout that you want to reset / delete, or you may end up resetting / deleting the wrong Layout! Do this by clicking on the desired Layout after clicking the Layouts button before making any changes.
The flowgraph is used to construct your workflow that comprises of Nodes and Edges. Nodes represents functions that have input and generate outputs. These nodes are created by dragging tools into your workflow from the Tools Catalog. A node's input and output have 'ports' which are where edges can be connected. Edges are connections between the output port of an upstream node to the input port of a upstream node. Any inputs ports that are unconnected can also be set to specific values using the Parameter Editor. The color of the node indicates the following:
| C++ Nodes (can be executed on GPU or CPU) | |
| Python Nodes (can be executed on GPU or CPU) | |
| Cuda Kernels (always executed on the GPU) | |
| Widget nodes (executed on the CPU) |
The flowgraph has the following components:
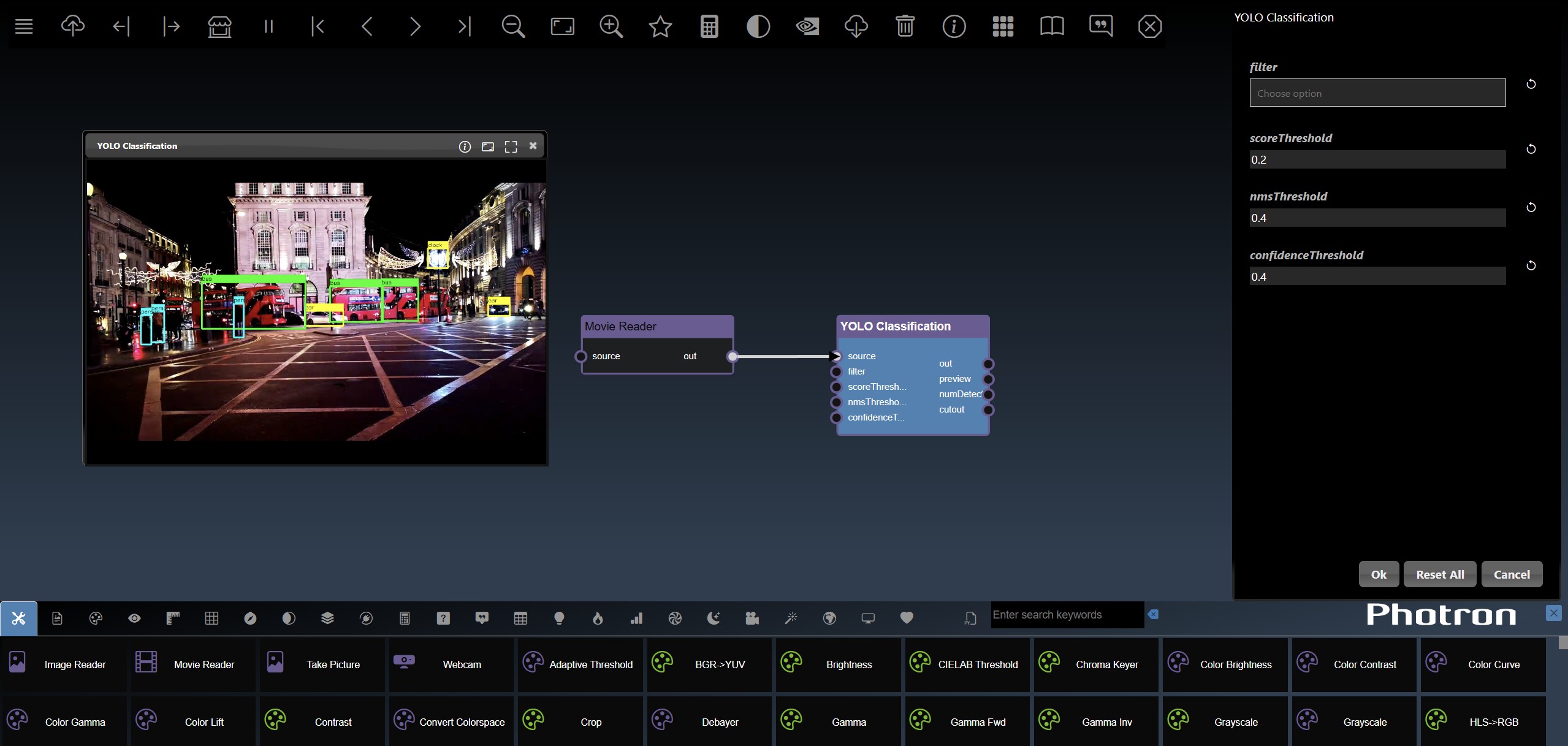
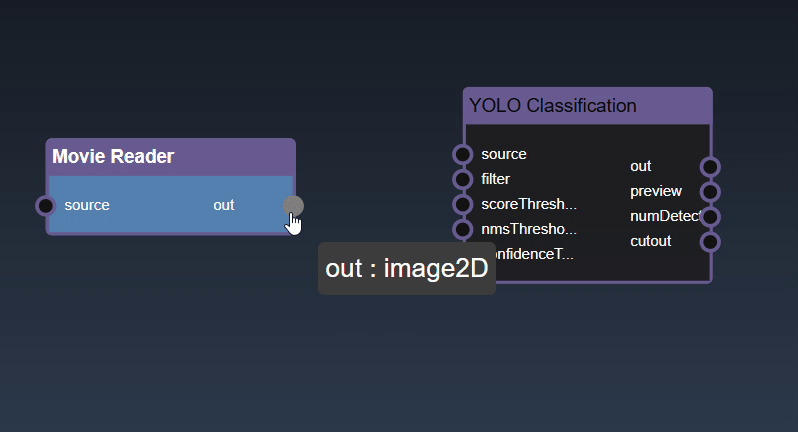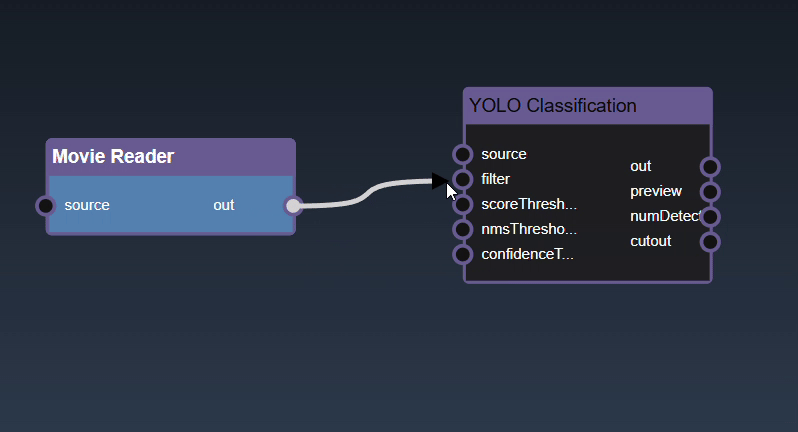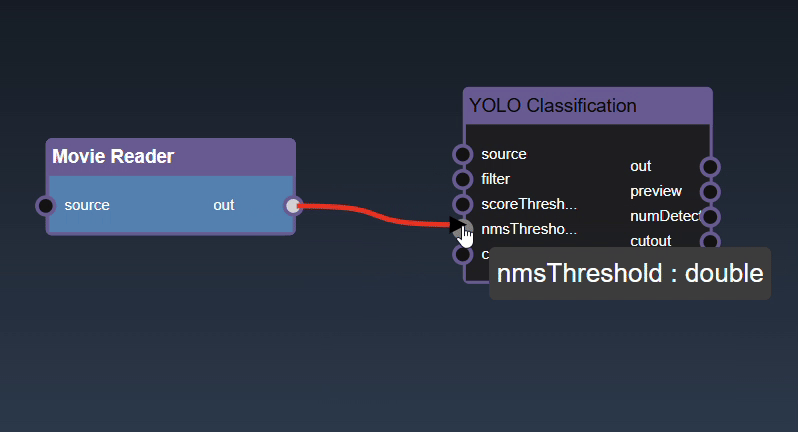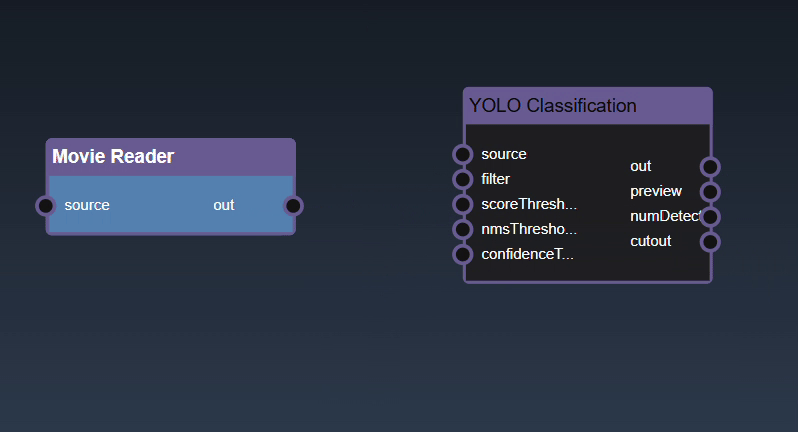
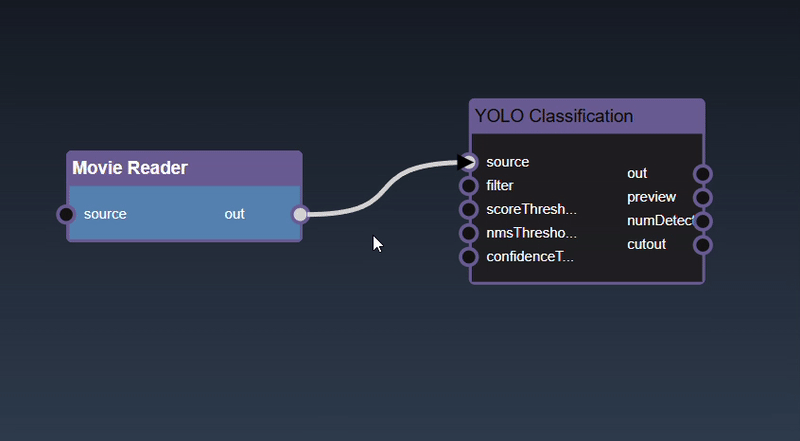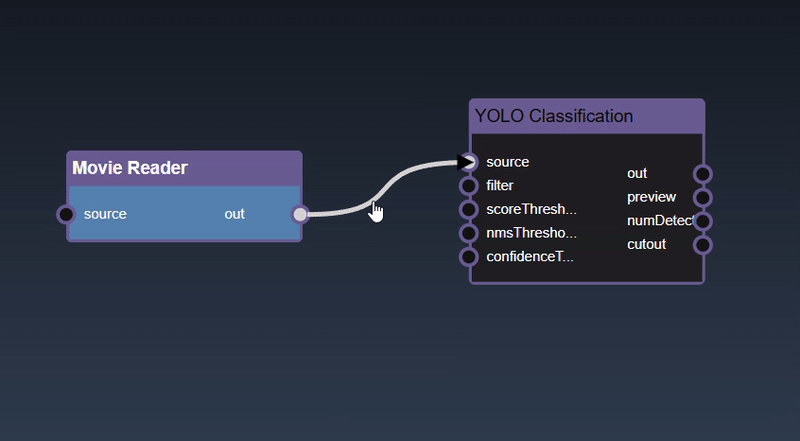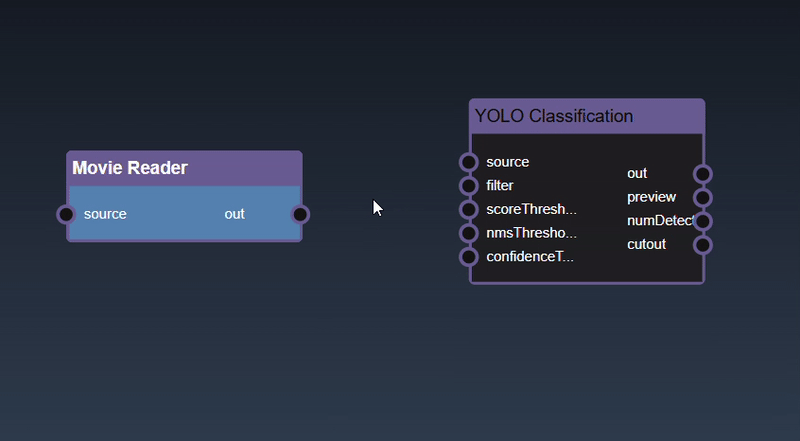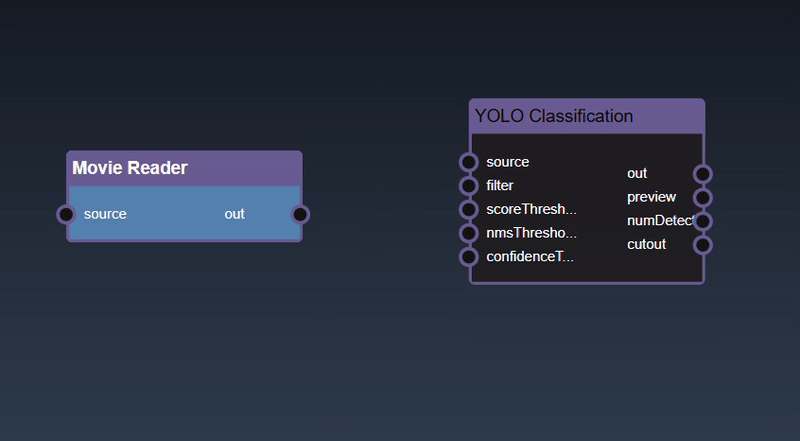
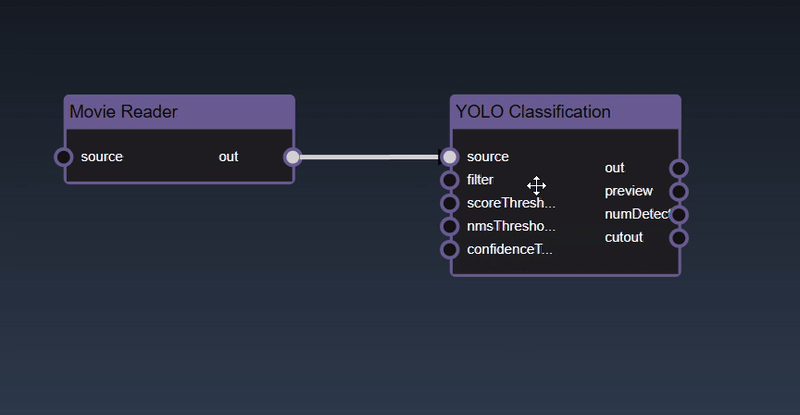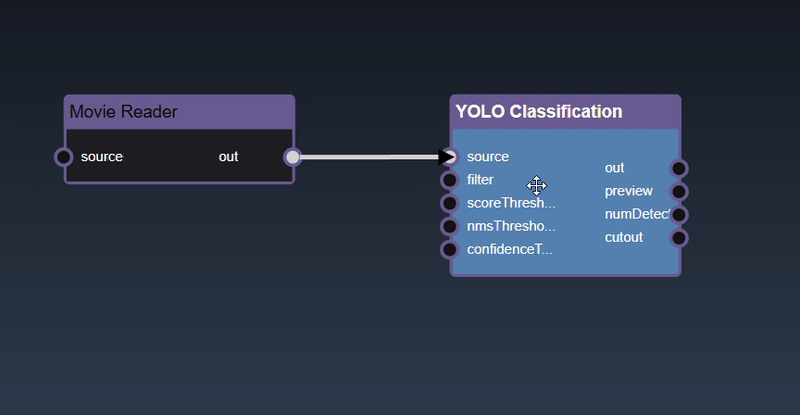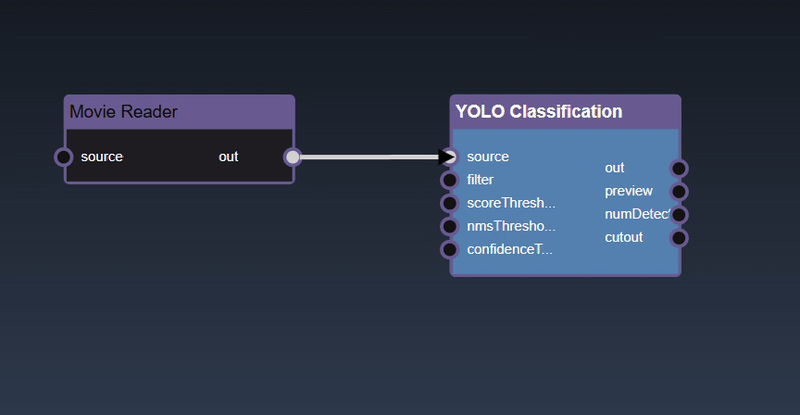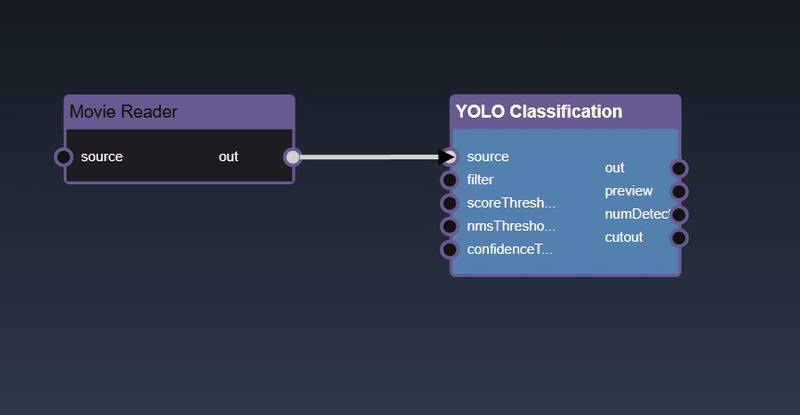
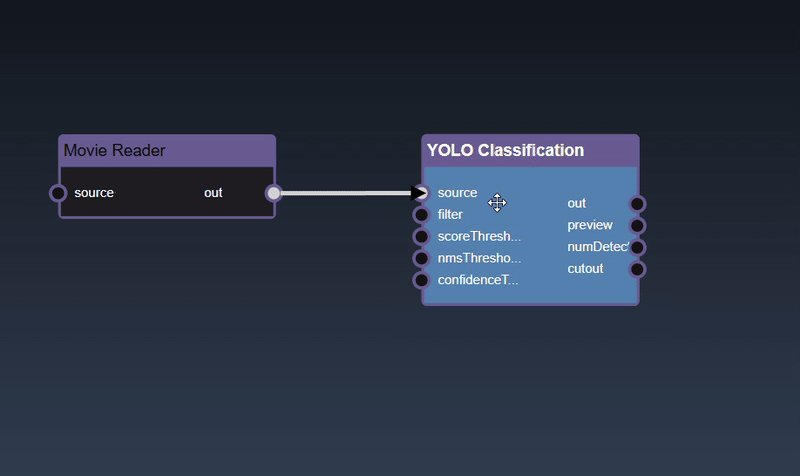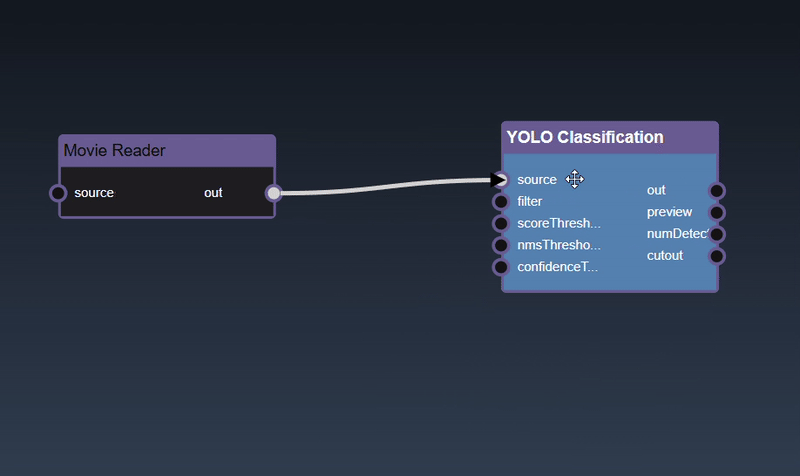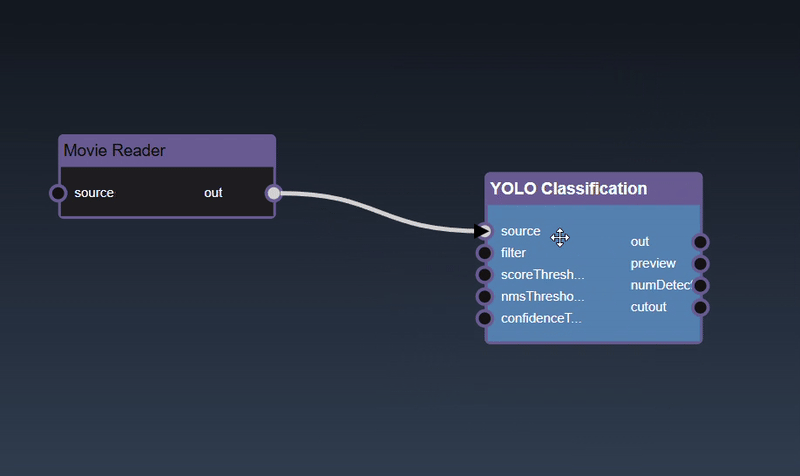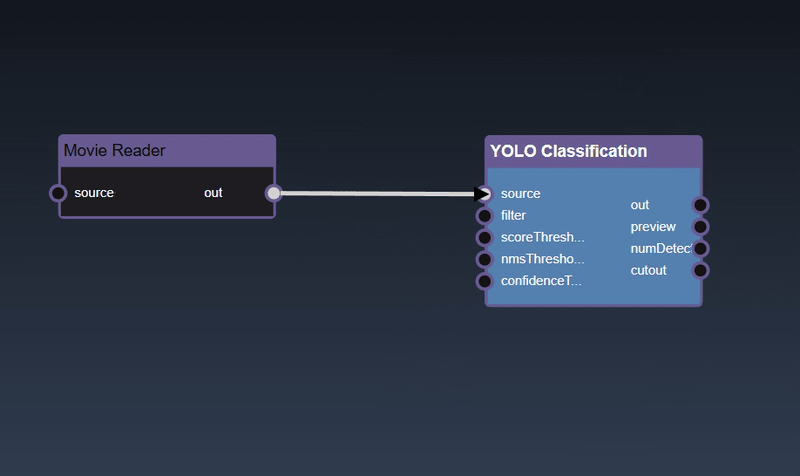
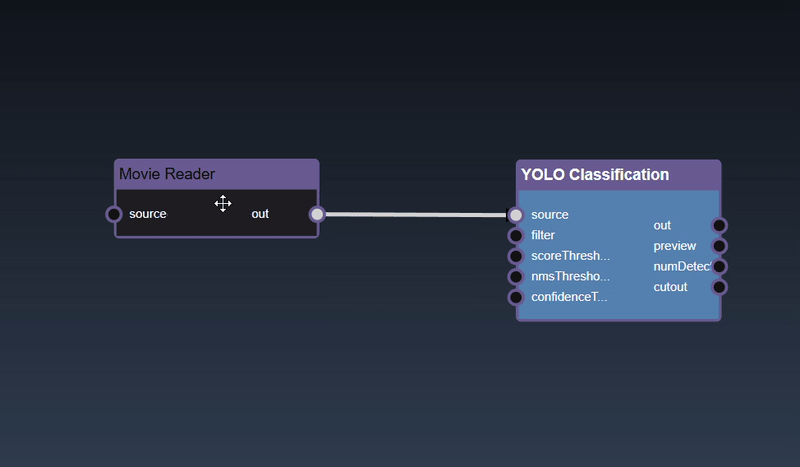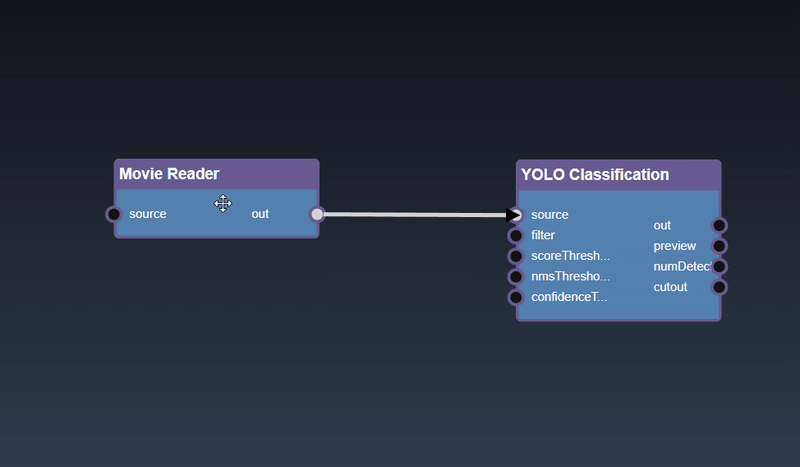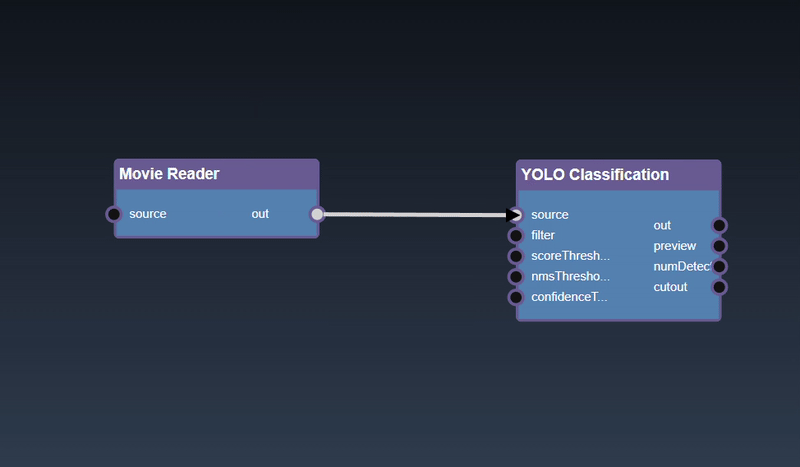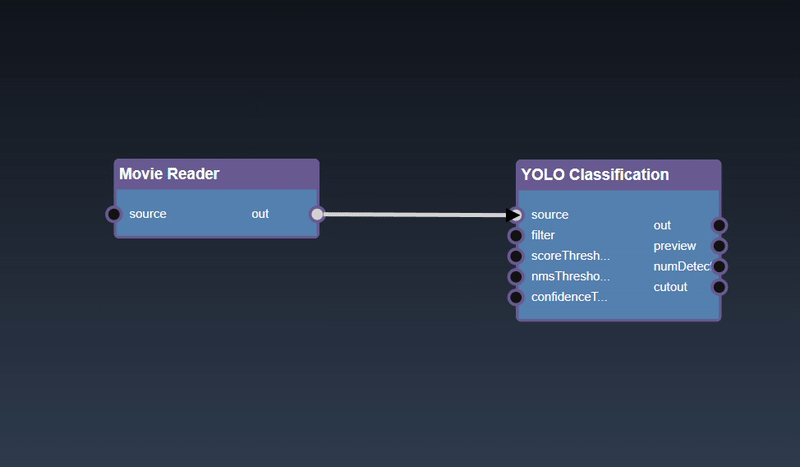
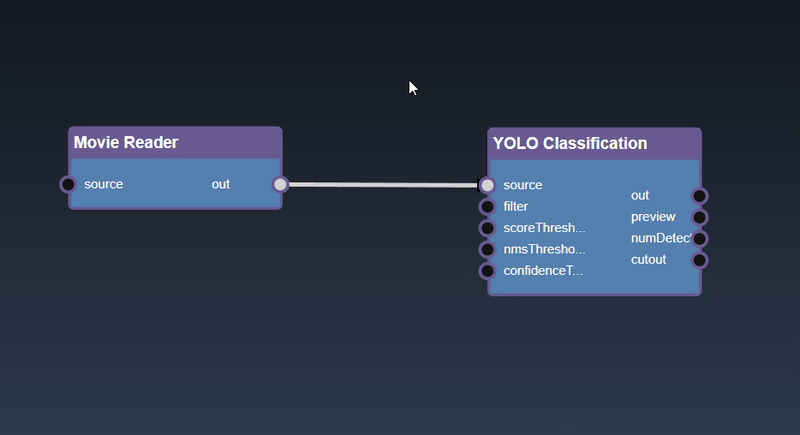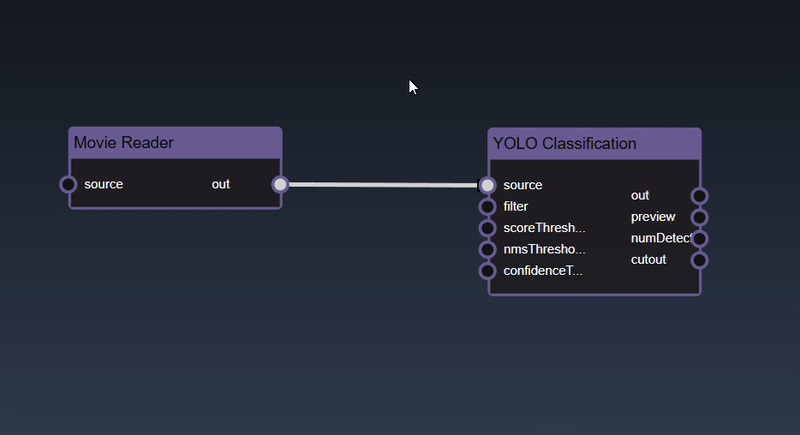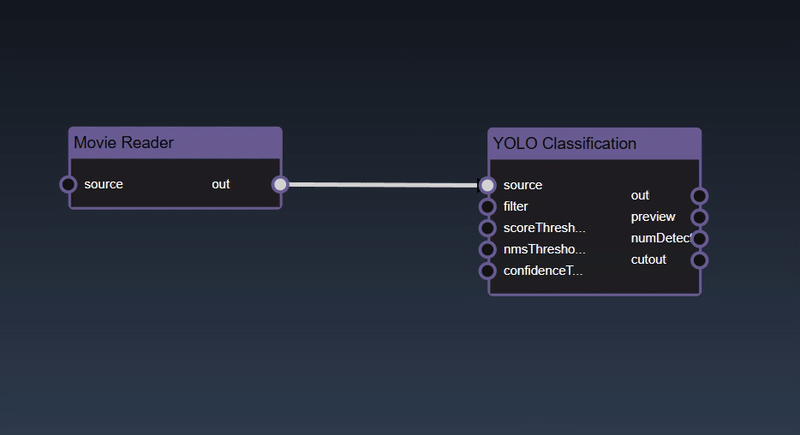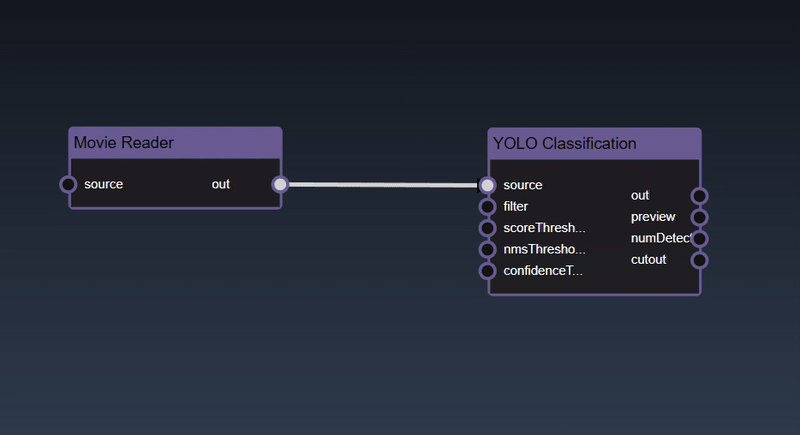
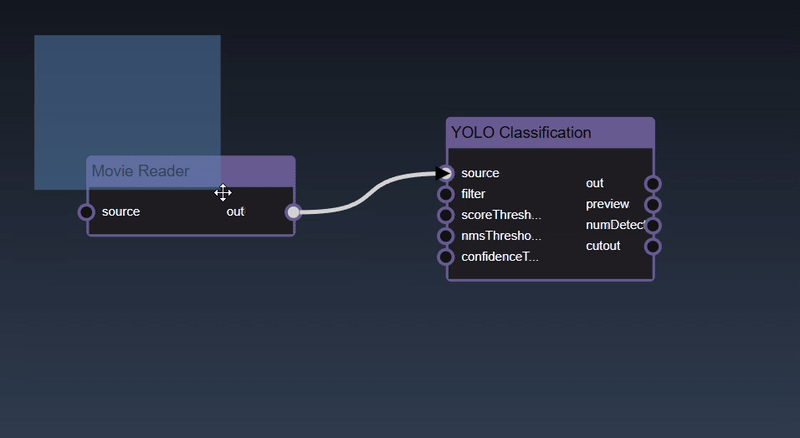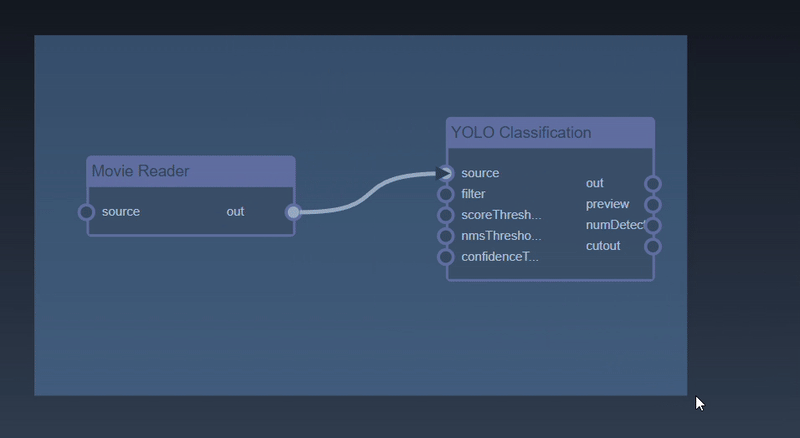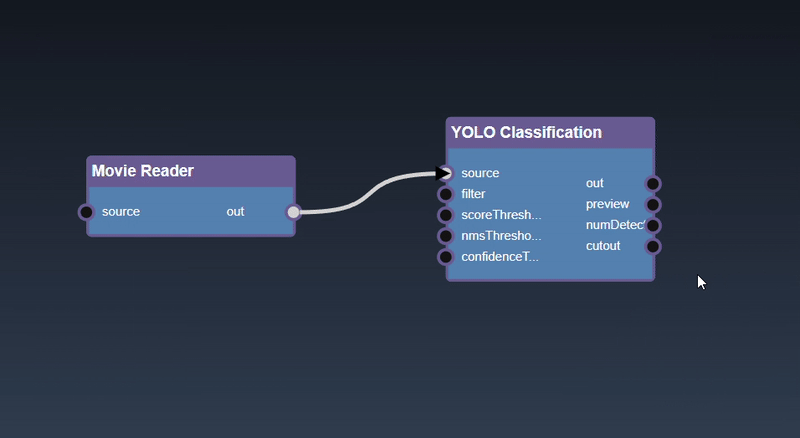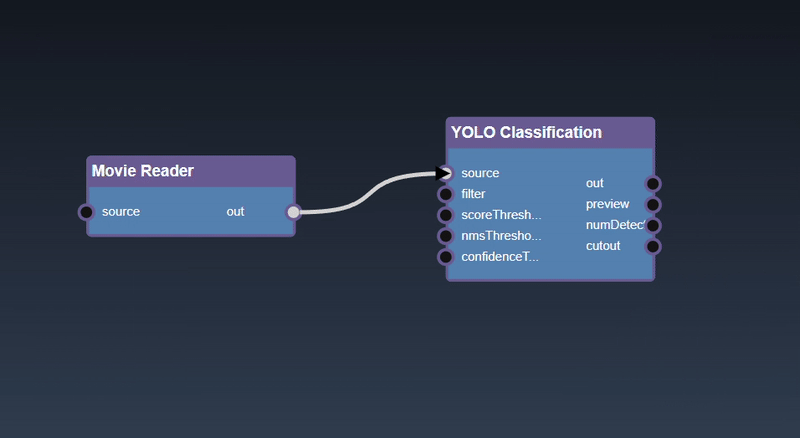
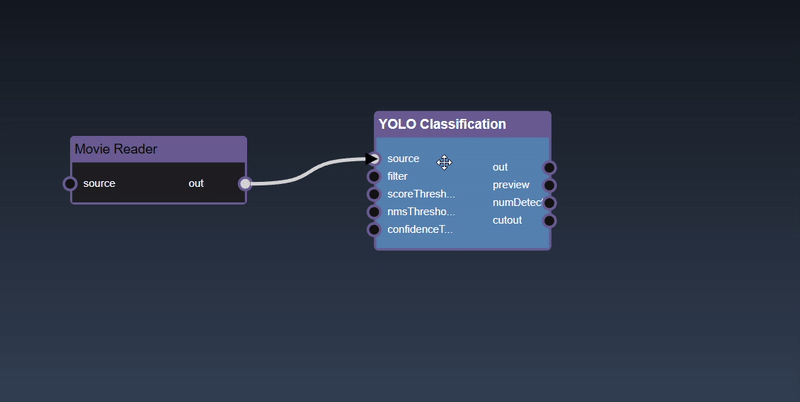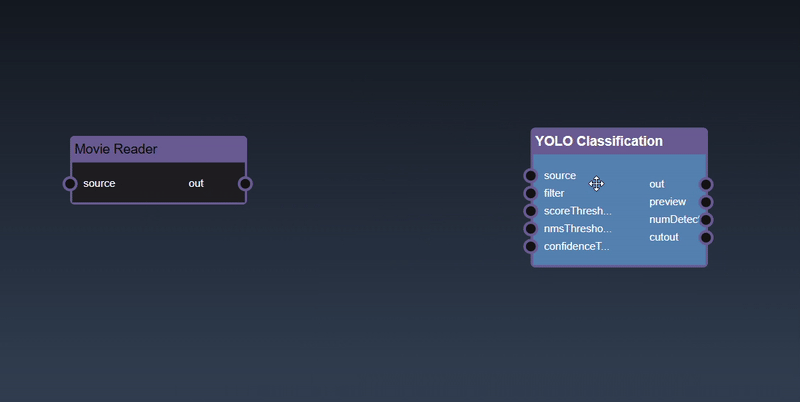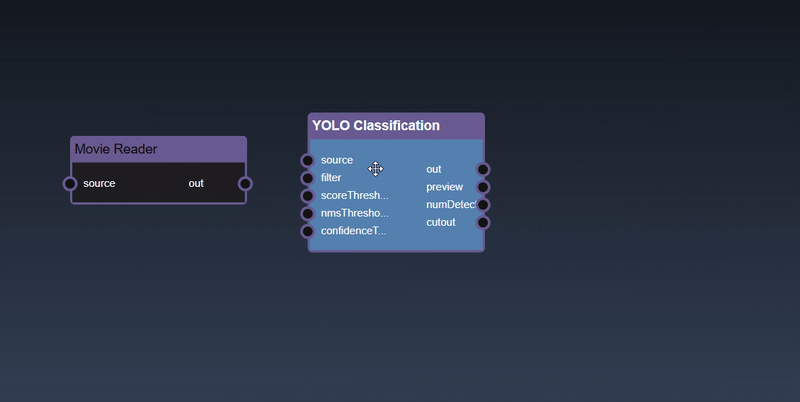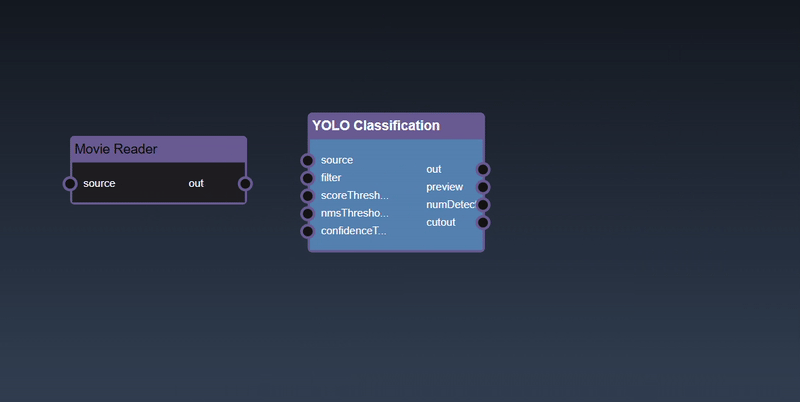
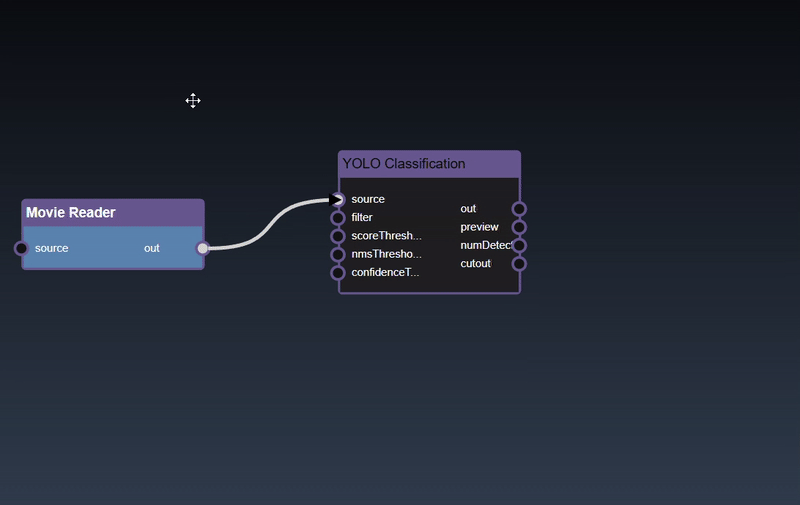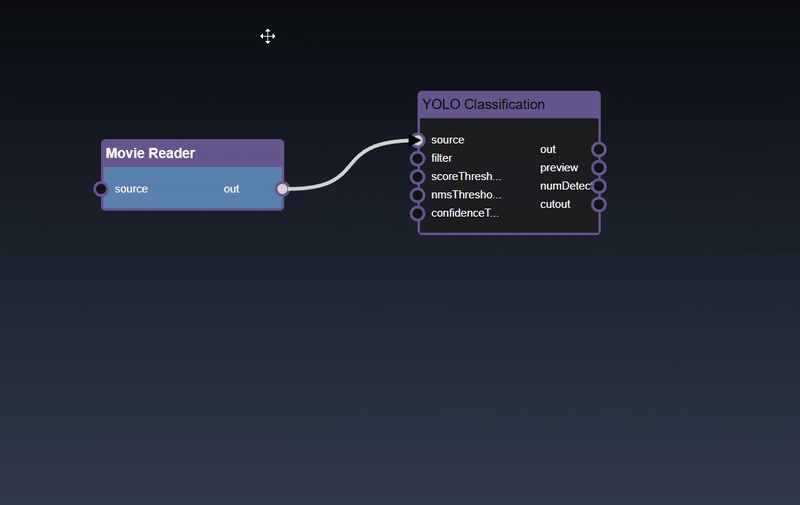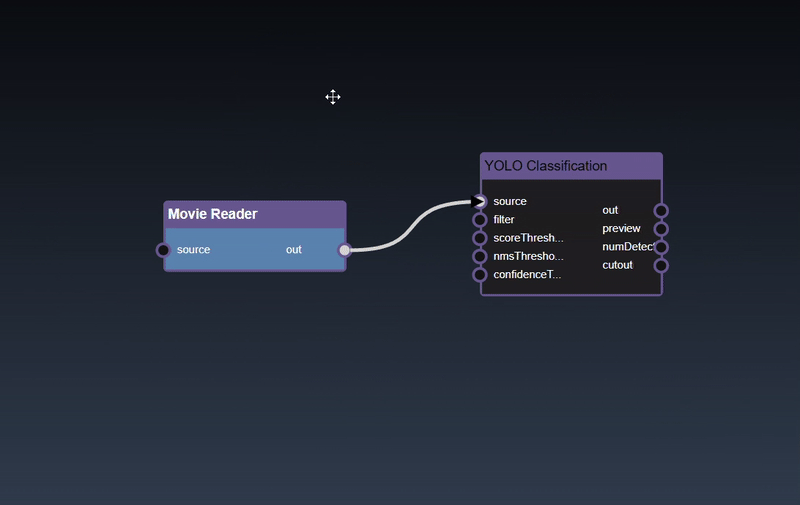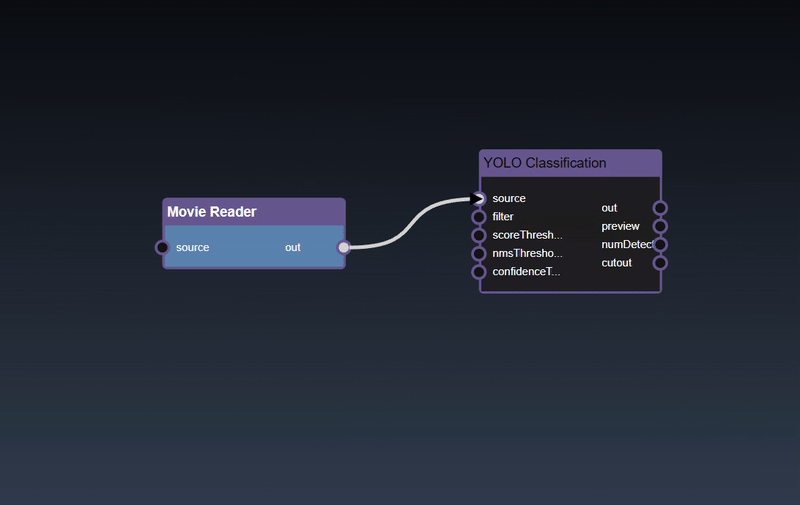
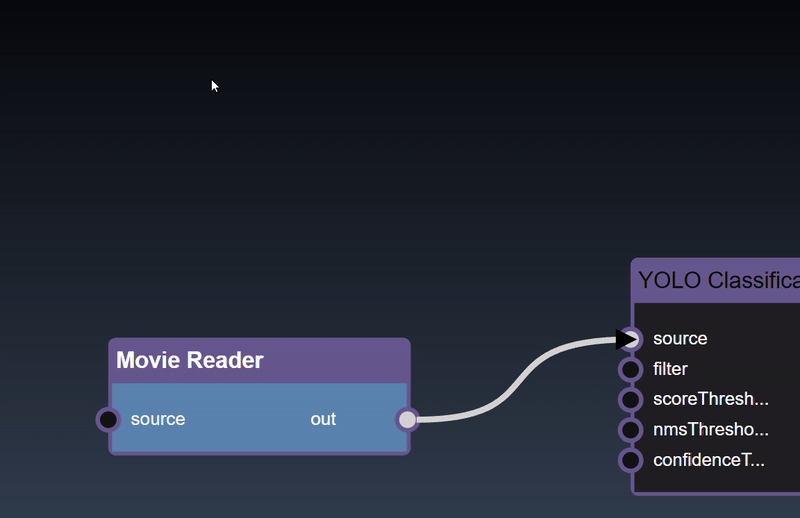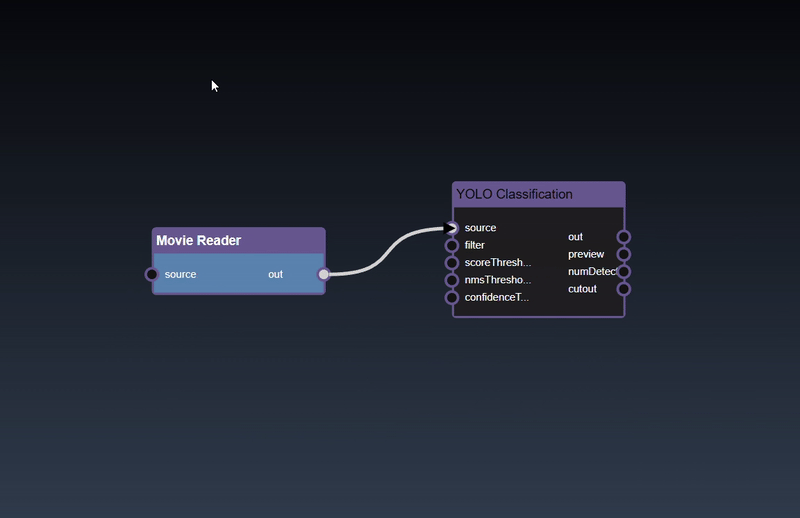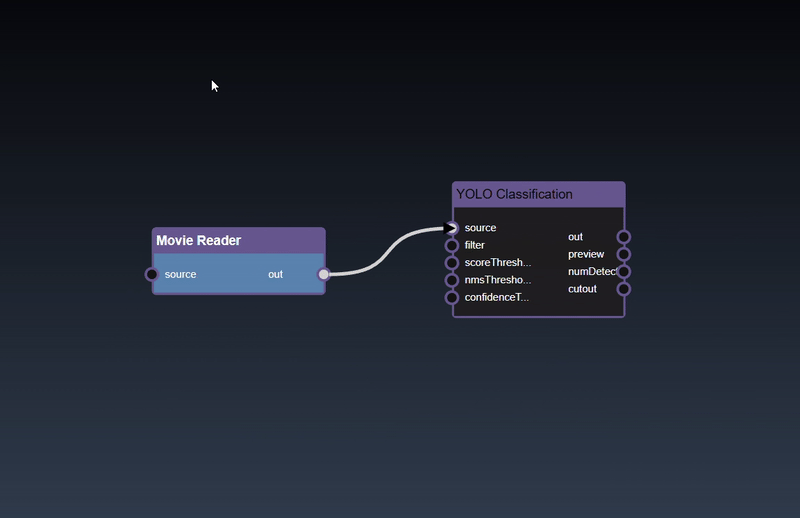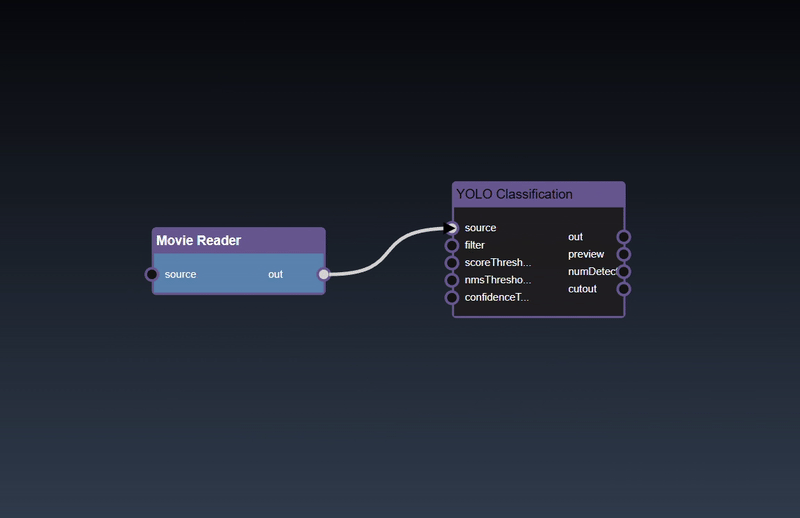
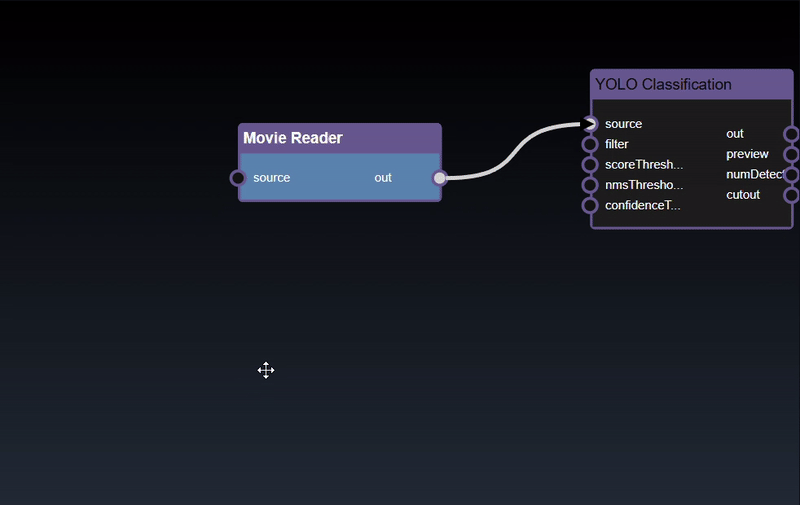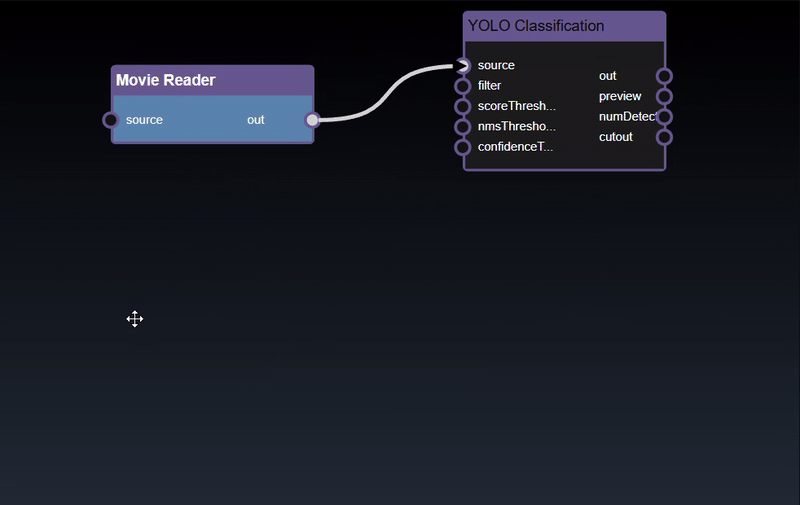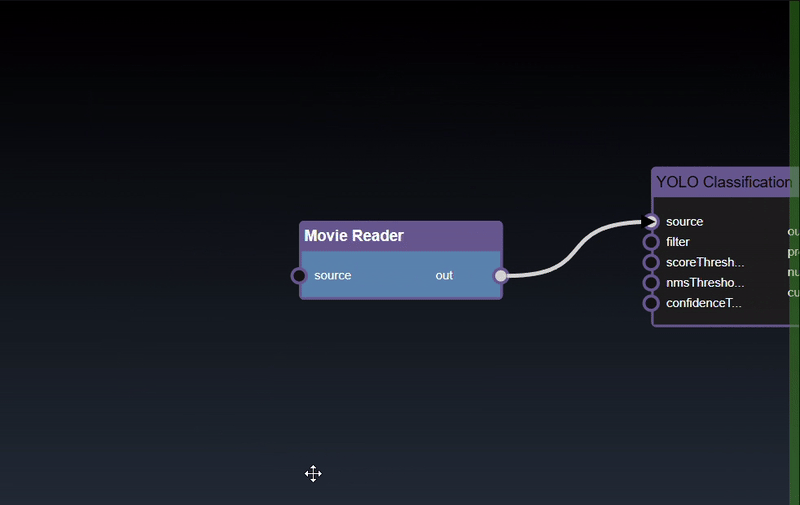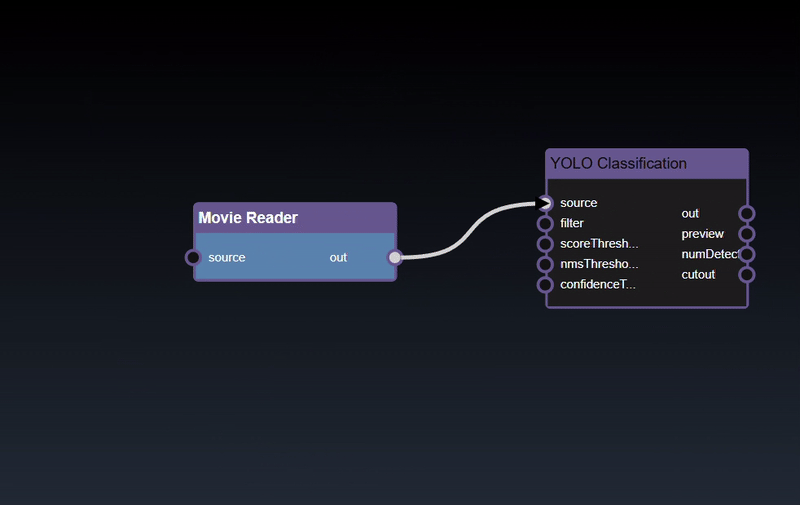
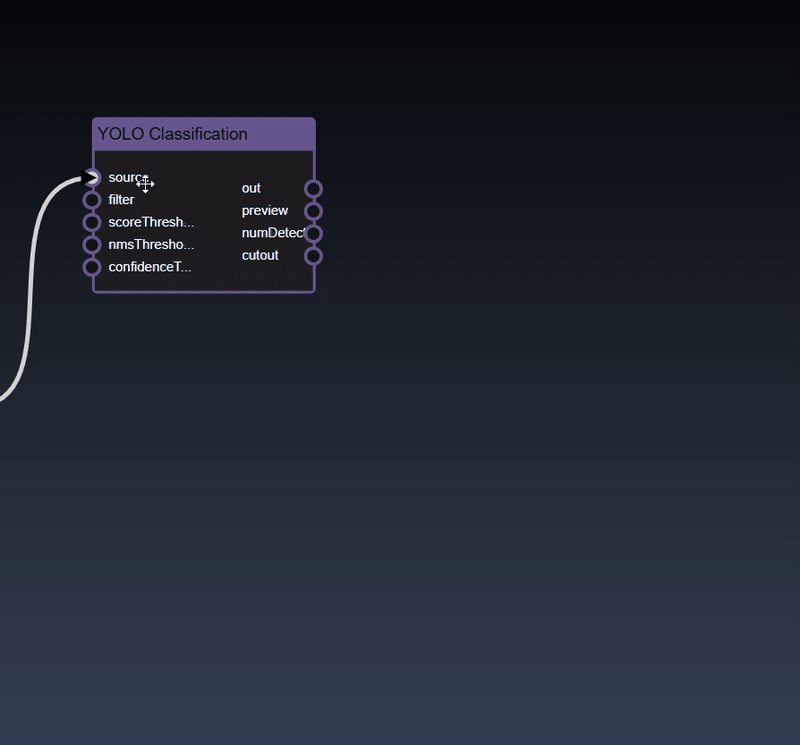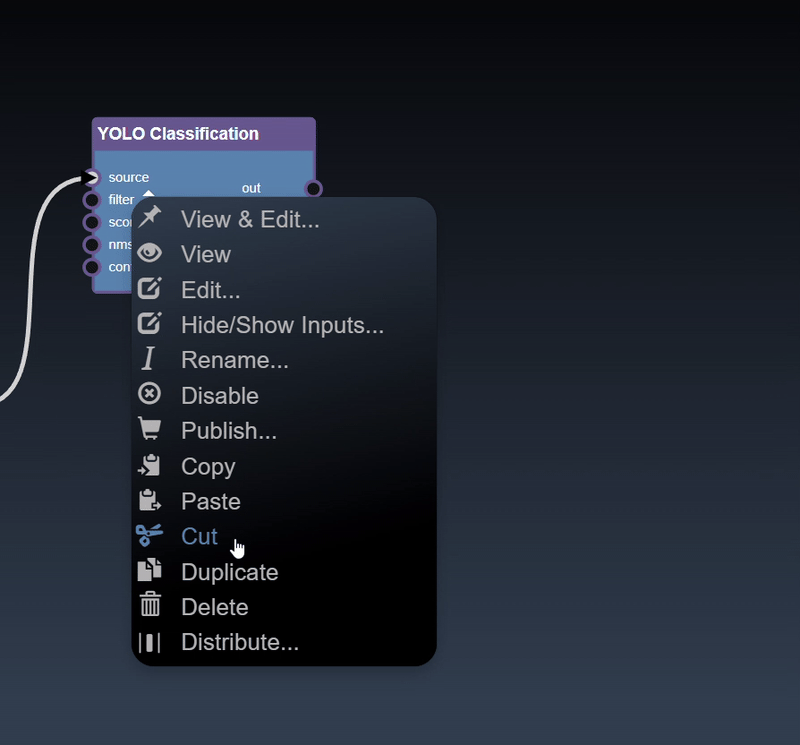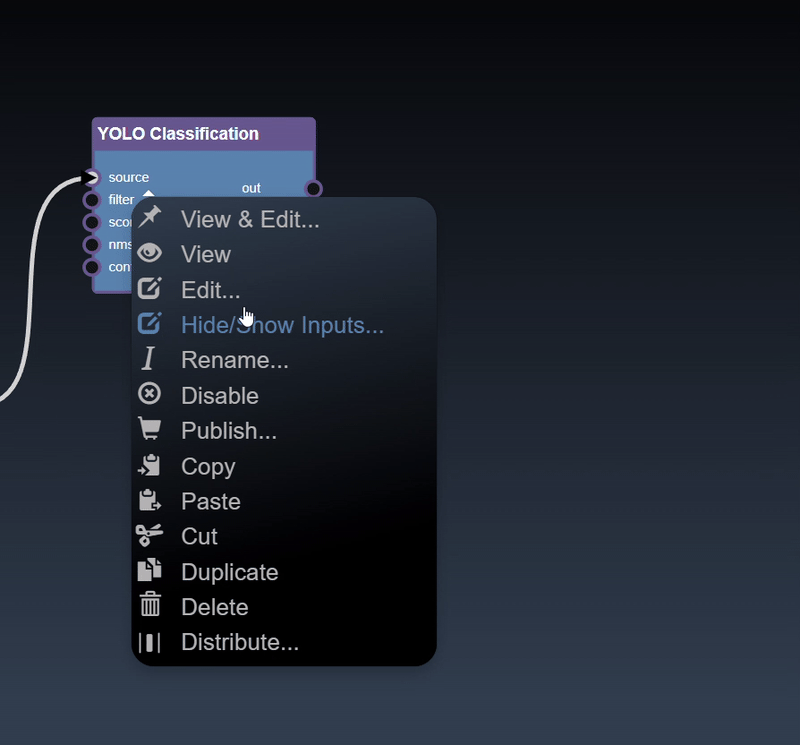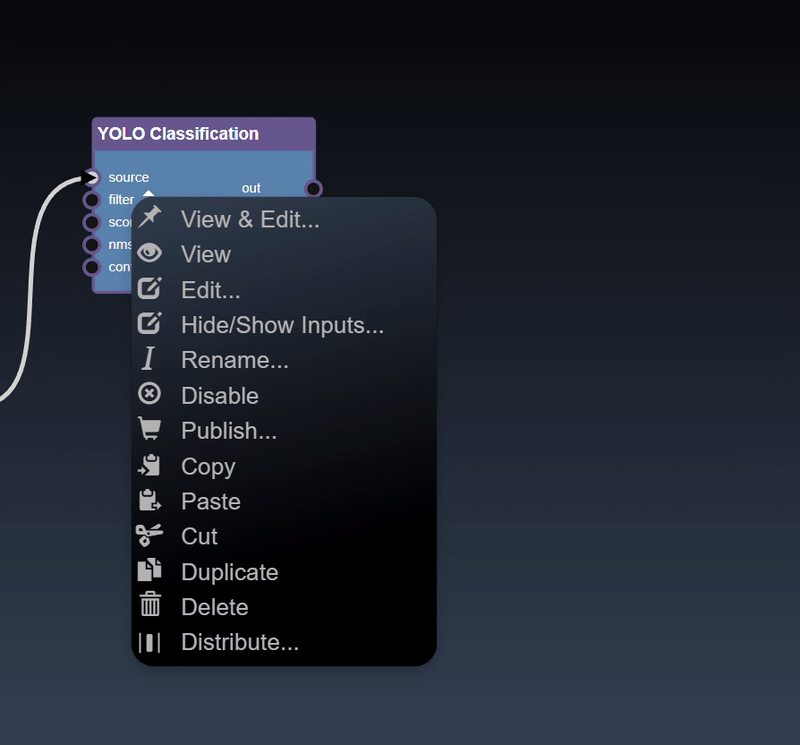
Adding an Edge to connect the output of an upstream node to the input of a downstream node. In this example, we want to have the Yolo Classification be done on a Movie Reader, we thus connect the output of the Movie Reader node to the input of the Yolo Classification node. Click on the source port of the upstream node and the drag to the destination port of the downstream node. A green line color indicates that the edge is allowed which is based on the type matching between the two ports
If the types do not match then a red line color indicates that the edge is invalid
There are a few exceptions to allow different types to be connected to each other. For example, the image2D type, which represents a 2D image in system memory, can be connected to a type cuda2D, a 2D image in GPU memory and vice-versa. The exceptions are as follows:
| Output Type | Input Type |
|---|---|
| * | Any type |
| Any type | * |
| image2D | cuda2D |
| cuda2D | image2D |
| double, int, bool or numeric | double, int, bool or numeric |
| double, int, bool or numeric | double, int, bool or numeric |
| numeric2 | double2, int2 |
| double2, int2 | numeric2 |
| numeric3 | double3, int3 |
| double3, int3 | numeric3 |
| torch.nn.Module | torchvision.model |
| torchvision.model | torch.nn.Module |
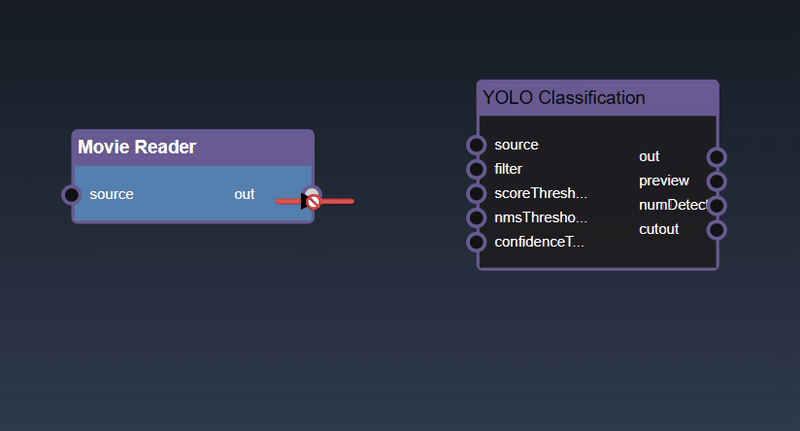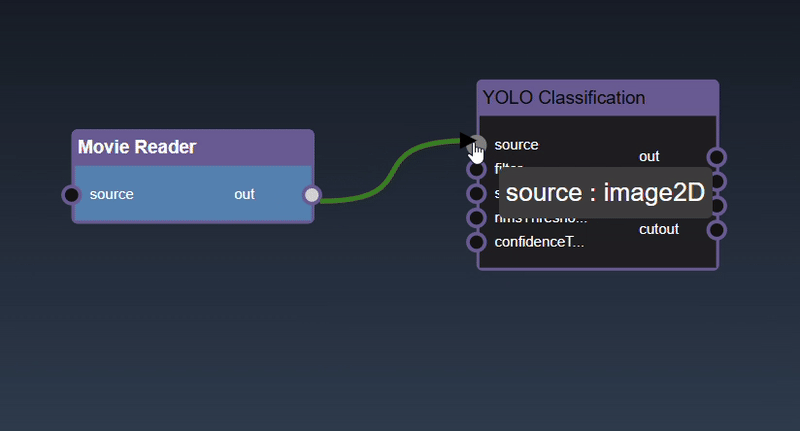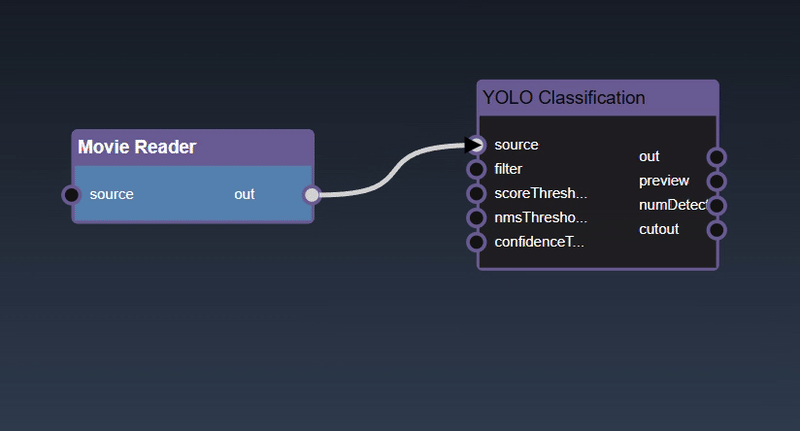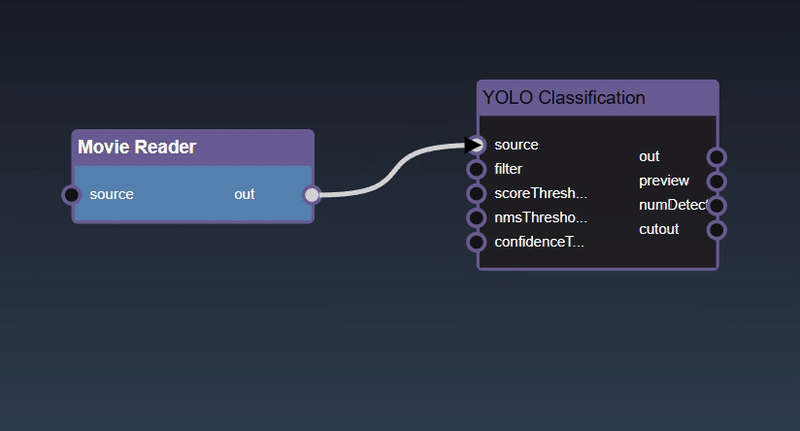
Removing an Edge disconnects the output of upstream node to the input of a downstream node. In this example we no longer want the Yolo Classification be done on the output of the Movie Reader. Hover over the edge, it will indicate it can be deleted when a change in cursor happens, then click on the edge to delete it
To see the type of a node's input or output, hover over the port and it will show as a tooltip

Select a node can be done with a single click on the node. The node is shown highlighted in blue when it is selected
Clicking and dragging on a node will select it and also allow you to move the node around in the flowgraph
Holding the shift key whilst clicking allows you to add more nodes to the selection
To deselect all the nodes you can click on the flowgraph
Multiple nodes can also be selected by doing a rectangular selection, hold the alt key and drag the mouse which shows a box selection which will select all the nodes in the rectangle intersection after the mouse is released
To delete a node can be done by clicking the delete key
To 'View & Edit' a node, double click the node, if there are multiple outputs a menu will allow you to select which output you wish to view
To View a specific output you can double click on the output port of the node
You can also 'rip' a node to remove it from the edges by shaking the node quickly
To zoom into the center of the flowgraph you can press the + hotkey
To zoom out of the flowgraph you can press the - hotkey
To zoom fit flowgraph, showing all nodes in viewport, you can press the f hotkey
If you wish to view a specific output of a node, you can double click the output port directly and avoid needing to select from the menu
Click on the trigger icon for input ports to trigger the action
Mandatory inputs will be show in a rectangular border whereas optional inputs are drawn in a circular border:

To pan the flowgraph you can click and then drag the mouse. This allows you to navigate the workflow in the flowgraph when it becomes more complex
You can also zoom in and out using mouse scroll wheel or zoom gesture
When nodes are not in the visible viewport then indicators are shown on the boundary of the viewport. The indicators are useful to highlight scrolling or zooming will yield hidden nodes.
Clicking the left mouse button over the node brings up the node context menu and also selects the node
Inspect and adjust functions
Node attribute functions
Performance related functions
Input/output port related functions
ML functions are available when ML nodes are selected
Clipboard functions
Experimental functions
When you bring up the context menu without a node selected, the flowgraphs viewport functions are shown:
The Parameter Editor allows you to edit the parameters of the currently edited node
The UI consists of the tool icon and the name of the node that is being editoed, followed by the list of input parameters of the edited node and finally the dialog buttons. The description link, which shows the name of the edited node, when clicked will open a webpage that has the description of the tool. The input parameters are shown for any inputs that are not connected via the flowgraph.
Hovering over the parameter will show the description of the parameter:
The dialog buttons allow you to close the dialog - either you can accept the changes made by clicking OK, or reject any changes made to the parameters by clicking Cancel. A button also allows you to Reset All the parameters to the original default tool settings. The UI for each parameter input will be based on the type of the input, but all of them will have a reset icon that allows you to reset that particular parameter input back to its default value. The different types of parameter UI controls are as follows
| UI Look | Example | Description |
|---|---|---|
| Numeric textfield |  |
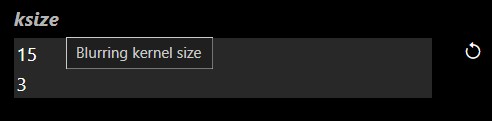
A numeric input allows you to enter a value. There are also step controls that allow you to increment one unit up and down. Below the numeric input you can drag, a range UI will appear. Whilst dragging, holding the shift key will do smaller step changes whilst holding control key will do larger step changes. |
| Numeric2 textfield |  |
Two numeric inputs allow you to enter both numerical values. Below the numeric input you can drag, a range UI will appear. Whilst dragging, holding the shift key will do smaller step changes whilst holding control key will do larger step changes. |
| Numeric slider |  |
If the slider has minimum and maximum values a slider appears Whilst dragging, holding the shift key will do smaller step changes whilst holding control key will do larger step changes. |
| Numeric2 slider |  |
Two numeric inputs with sliders that can optionally be locked together to modify both values at the same time. Whilst dragging, holding the shift key will do smaller step changes whilst holding control key will do larger step changes. |
| Checkbox |  |
A checkbox toggle to allow you to set values of true or false |
| Selection menu |  |
A selection menu allows you to set the value to one of the predefined values from a permitted set of values in the selection menu |
| Multi selection menu |  |
Multi selection allows you to add tags of permitted values. Click on the widget and a list of permitted values will show up. In some cases youur own user defined values that are not in the permitted set of values |
| Textfield |  |
A multi line textfield to allow you to enter the value for string parameters |
| Point |  |
A point allows you to set the values with a textfield and also has an icon that when clicked opens the viewer and you can select a point by clicking in the image directly |
| Color |  |
A color button when clicked allows you to set the color using a color dialog 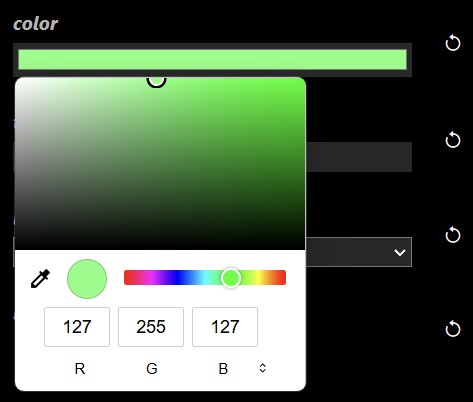
|
| Curve |  |
An icon when pressed opens the bezier curve editor
|
| Map | 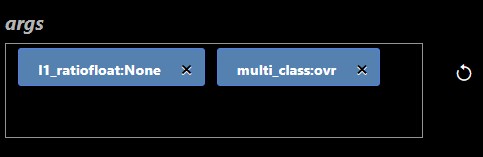 |
A map is a series of key/value pairs.
Clicking on the widget opens a dialog editor that shows documentation as well as
allow you to enter the key abd value pair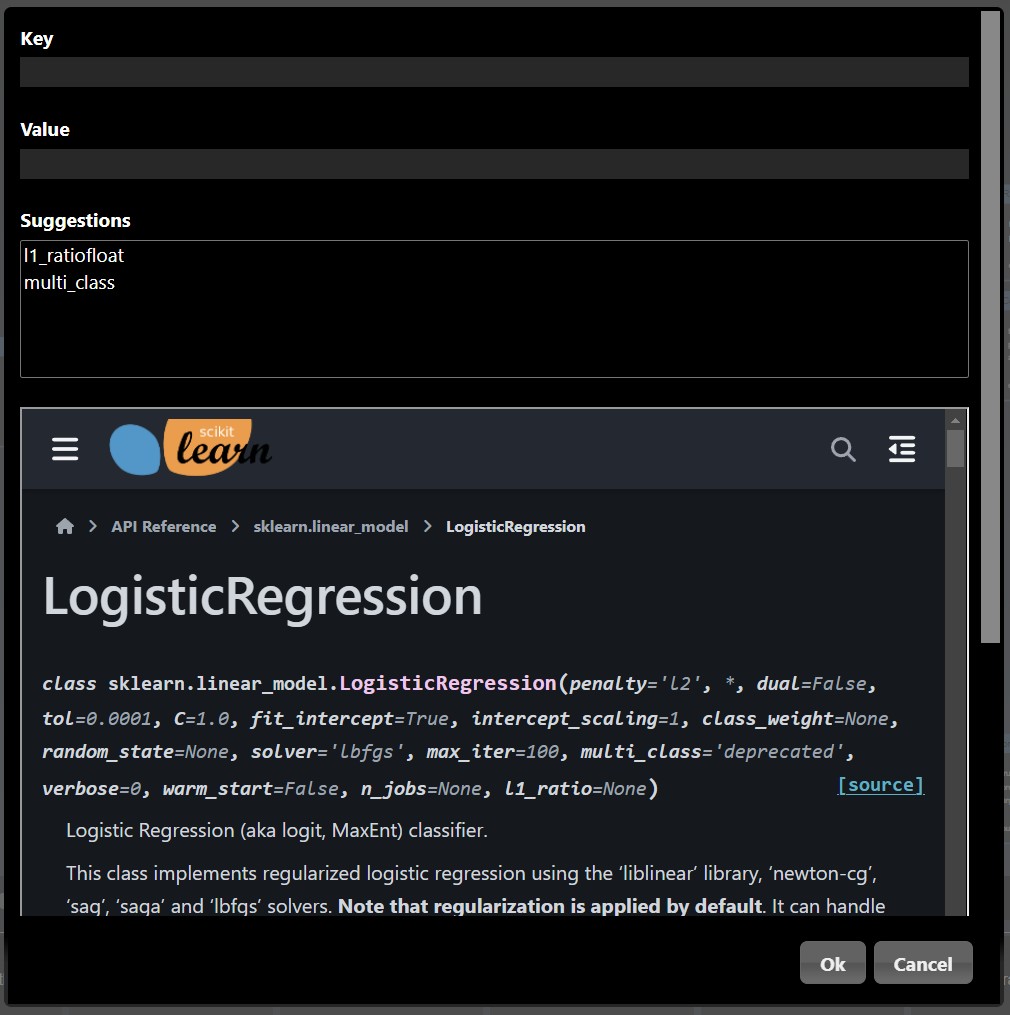
|
| Filebrowser |  |
An icon when pressed opens the IO Dialog that allows you to set the file location. The prefix ${assets} is used to specify the file location is in the assets folder. |
| Tabs | 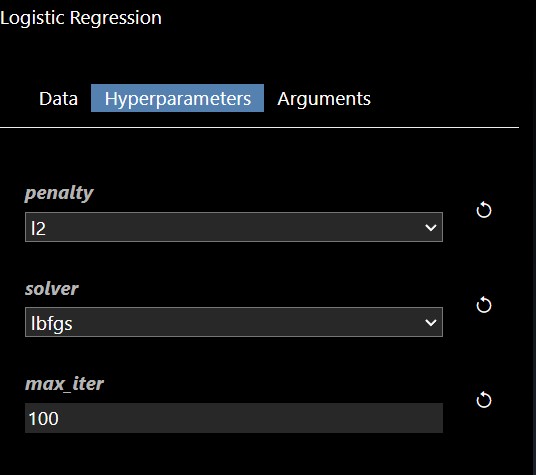 |
Some of the tools also have a Tab user-interface to layout the controls into different tabs. |
The viewer allows you to view the outputs of the currently viewed node
A node can be viewed using the node context menu and selecting 'View' or 'View & Edit'. When viewing a node with multiple outputs a menu will ask which output to view (alternatively, if you wish to view a specific output of a node, you can double click the output port directly and avoid needing to select from the menu)
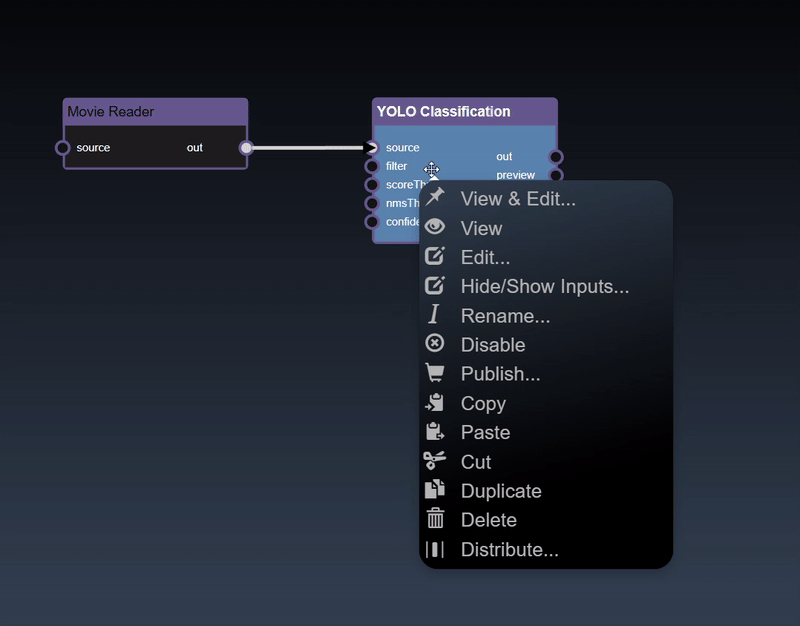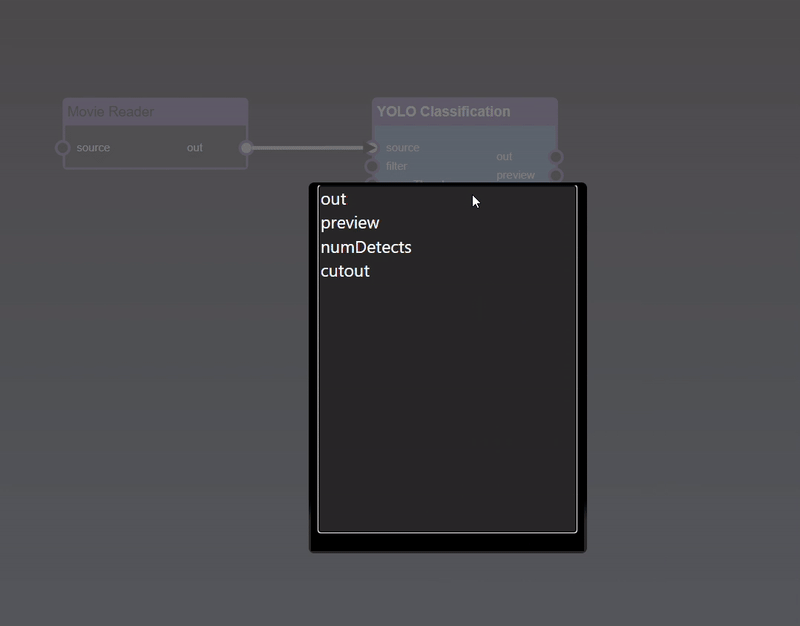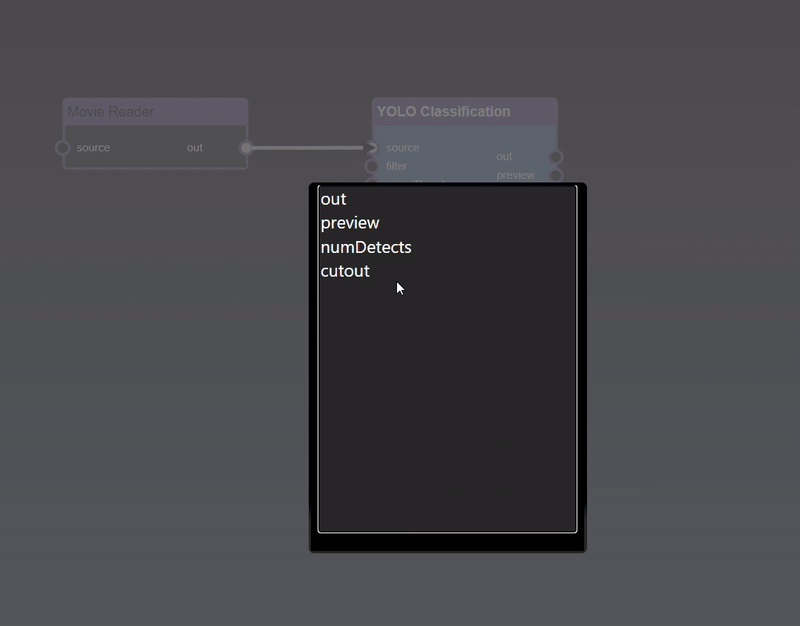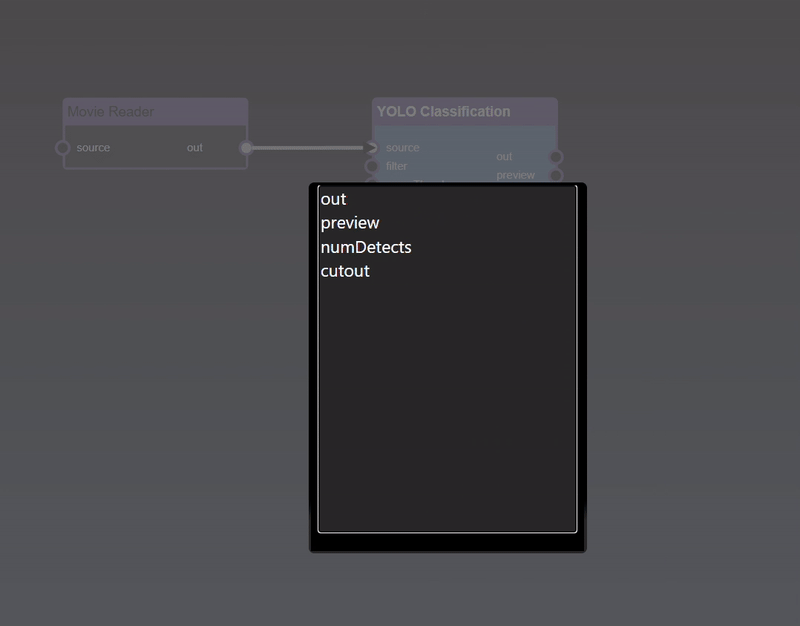
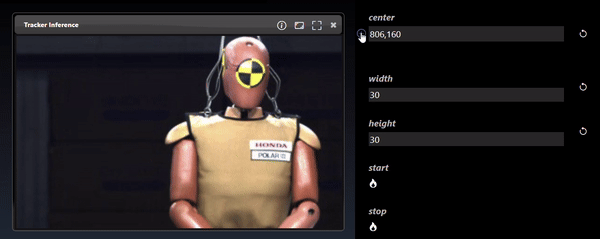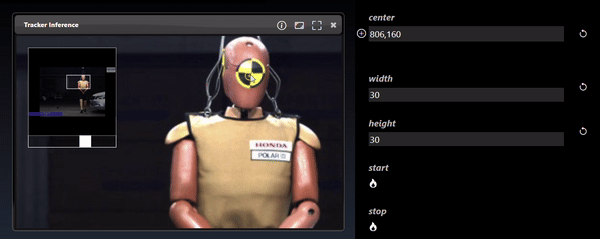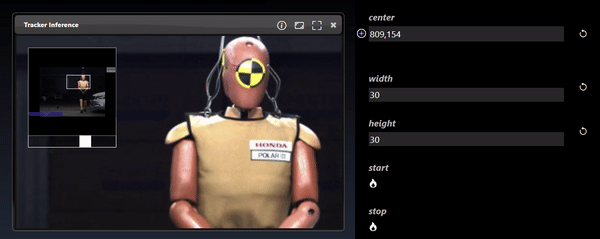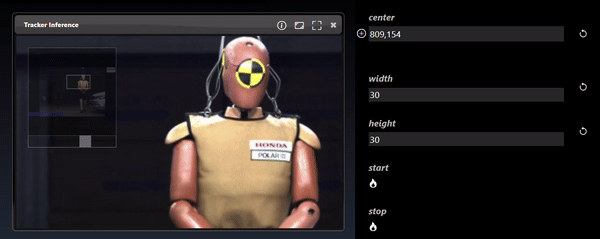
The viewer also has controls to zoom and pan. Using the mouse scroll wheel or zoom gesture you can also then pan by dragging the image. When zoomed in, a thumbnail is shown of the full image together with a slider to set the zoom amount.

Point parameters in the Parameter Editor can be set in the viewer. Select the overlay icon and then click in the viewer to set the location of the point:
Only one node can be viewed at one time in the viewer. However, the flowgraph can also show multiple the output of multiple nodes at the same time. For example, using the 'Thumbnail Image Display' or 'Full Image Display' tool allows you to show images that are drawn in the flowgraph directly. Both the 'Thumbnail Image Display' or 'Full Image Display' allow you to maximize or minimize the image view by hovering over the right hand corner and clicking the icon. Additional Display Nodes are available that can be used to view different types of outputs directly on the flowgraph.
The viewer, on top of displaying images, has specific UI to display mutli-dimensional data:
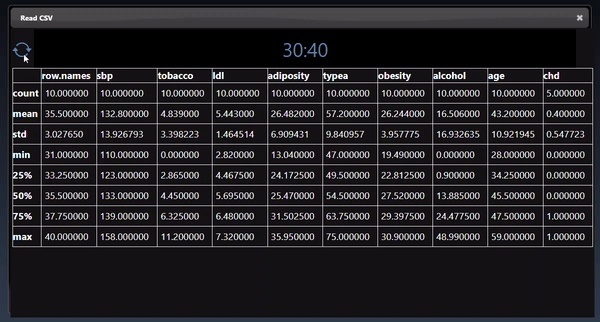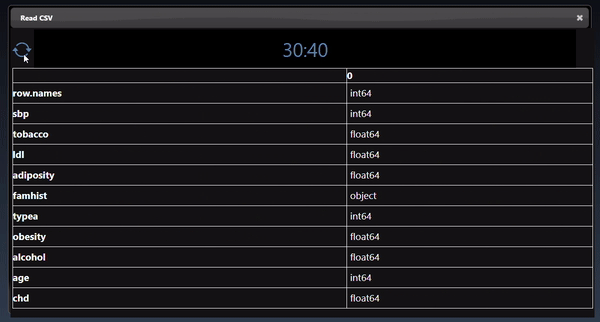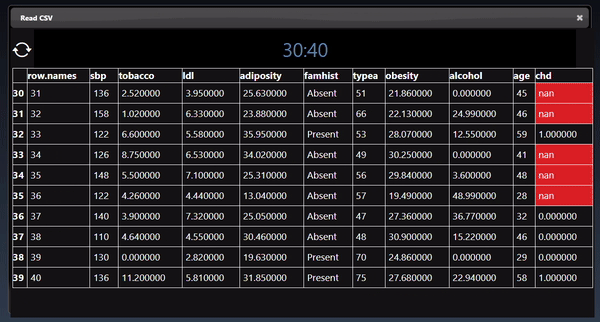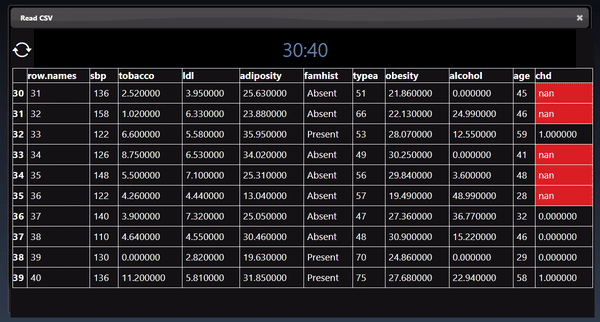
Dataframes represent 2D tables and are implemented using the Pandas Python module. The viewer displays the DataFrame as a HTML table. Additional controls allow you to slice a set of the rows and columns, in the example below we slice rows [30-40). The icon allows different views of the table including showing the sliced rows and columns, with red cells represent missing data, a summary description of the statistics of each column, a line chart of the numerical columns and the description of the types of each column:
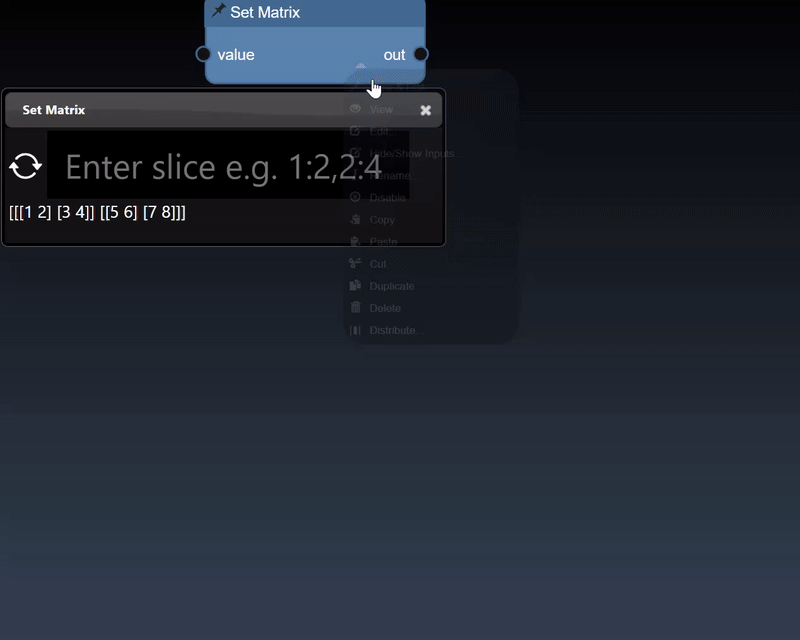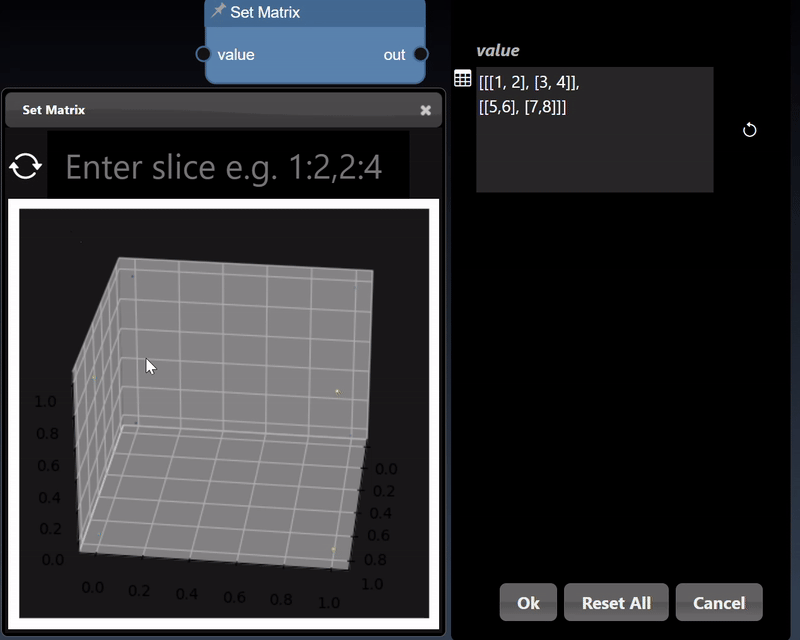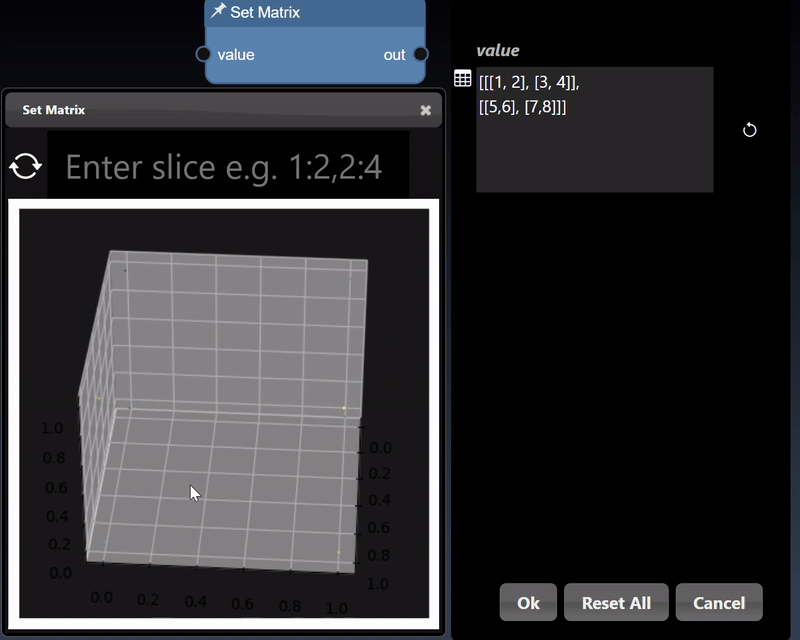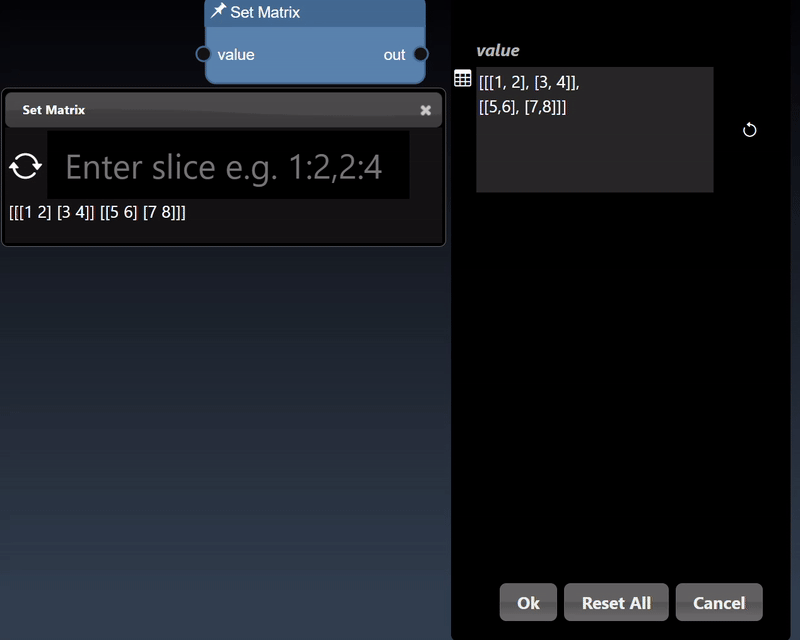
Numpy represents multidimensional numerical arrays and are implemented using the Numpy Python module. You can set a matrix using the Set Matrix tool. The viewer can display Numpy arrays in a variety of different visualizations where it will select the most useful visualization first and by clicking the allows you to visualize other representations of the arrays. Slicing controls are also available to reduce the tensor to a subset of its numerical data.
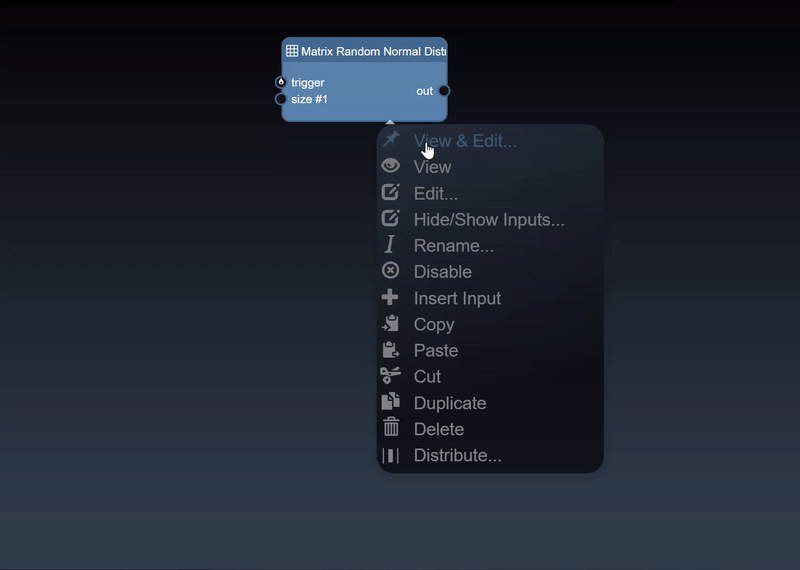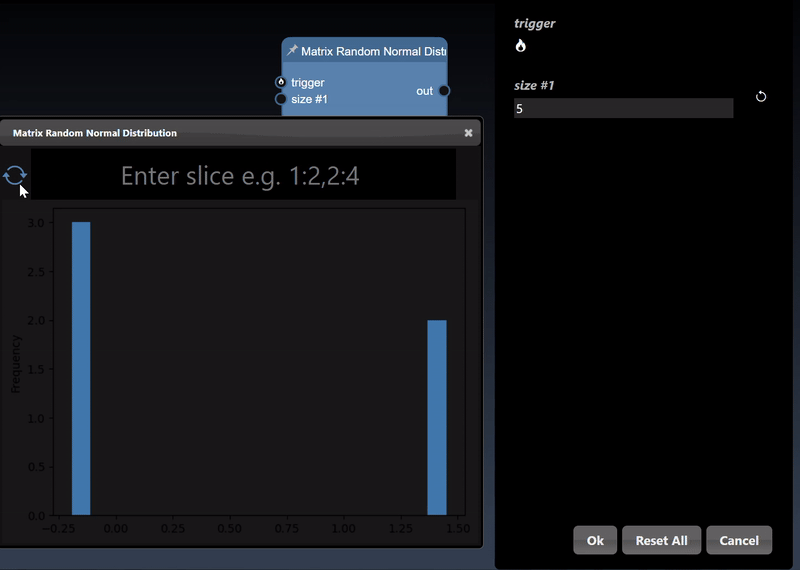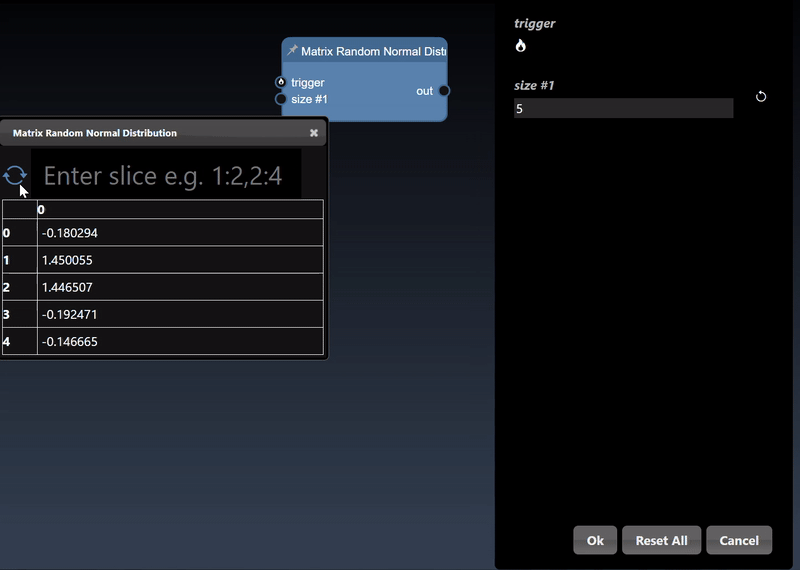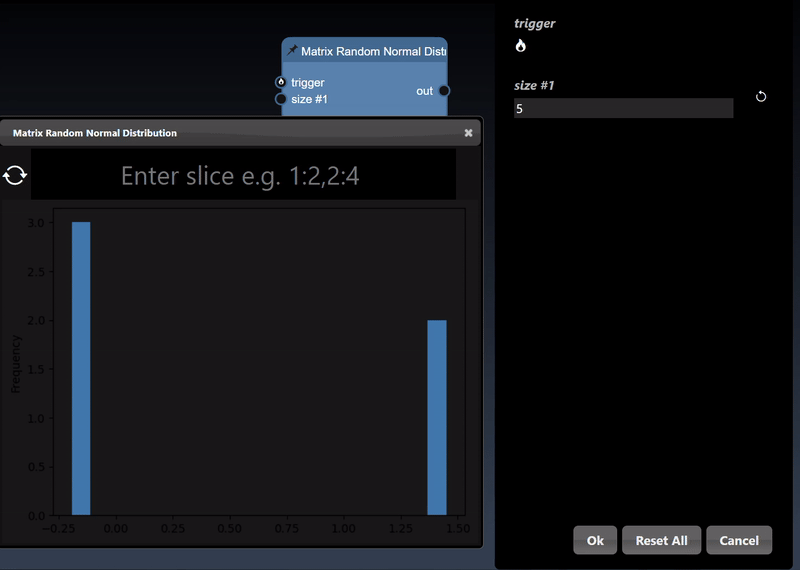
A 1D dimensional array can be randomly generated or set using the Set Matrix tool, with numbers separated by spaces, commas, semicolons, or tabs. It can be viewed as a histogram; a dot plot; a line chart and a histogram chart:
A 2D dimensional array can be randomly generated or set using the Set Matrix tool, with rows of numbers each separated by spaces, commas, semicolons, or tabs. It can be viewed as a heatmap; a 3D height map plot; a line chart and a table:
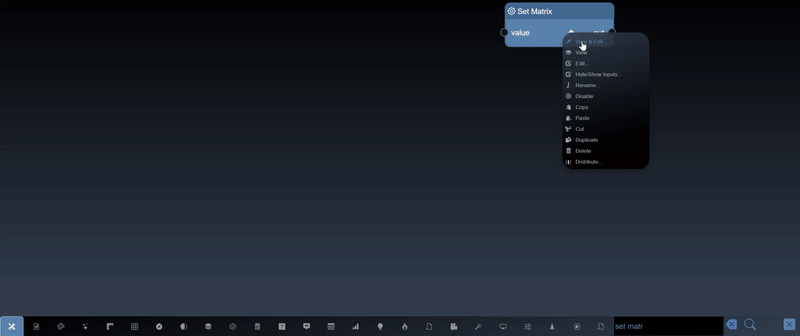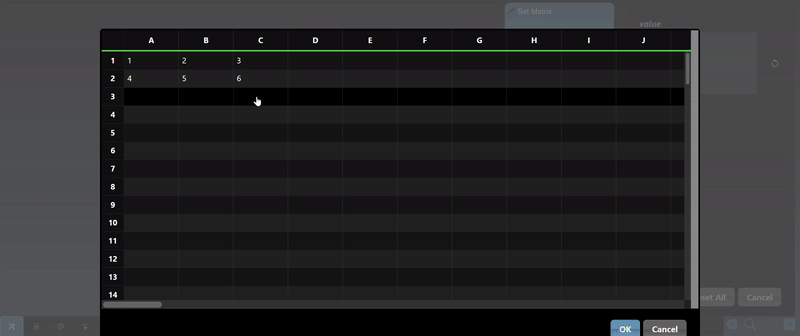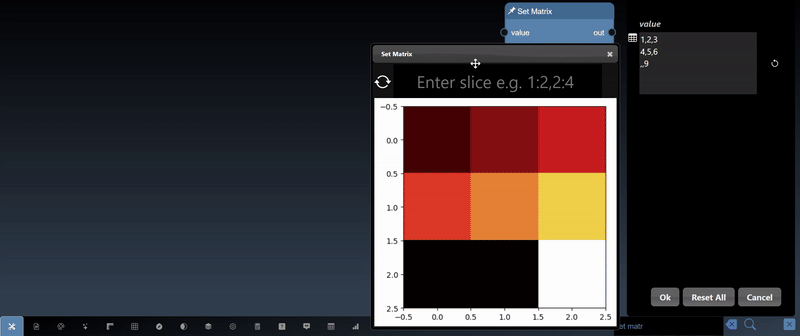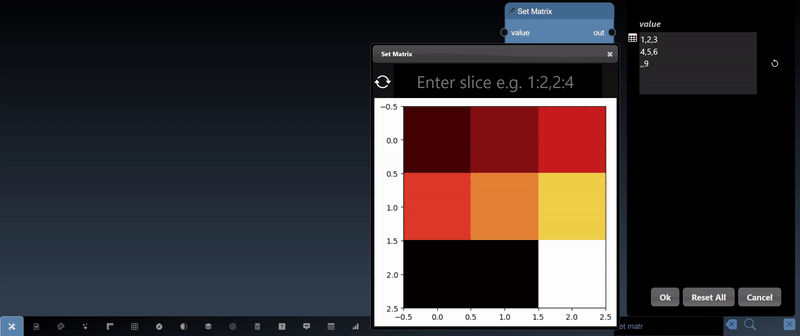
A 2D dimensional array can be randomly generated or set using the Set Matrix tool, with entries separated by commas where each entry can be a number or a list denoted by []. A 3D dimensional tensor can be viewed as a 3D plot and as a list of lists:
Tensors represent multi-dimensional numerical arrays and are implemented using the PyTorch Python module. The viewer can display tensors in a variety of different visualizations where it will select the most useful visualization first and by clicking the allows you to visualize other representations of the tensor. Slicing controls are also available to reduce the tensor to a subset of its numerical data.
A 1D dimensional tensor can be viewed as a histogram; a dot plot; a line chart and a histogram chart:
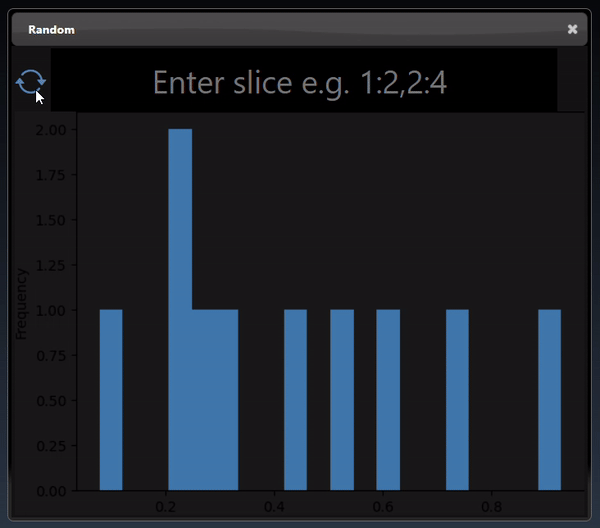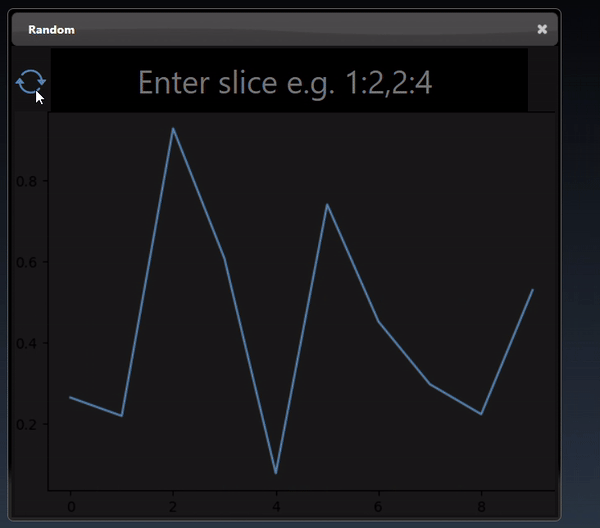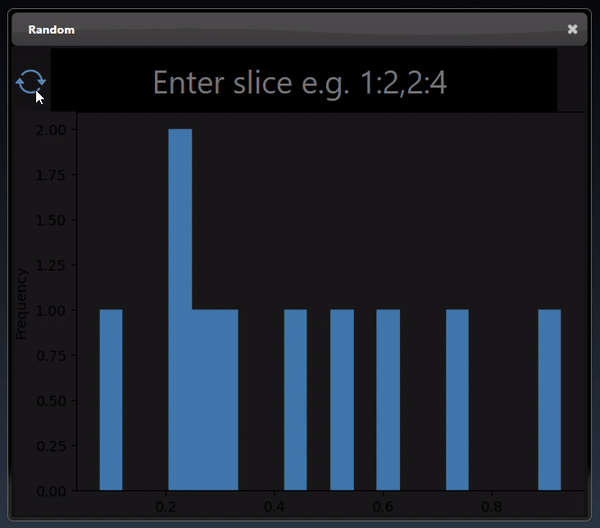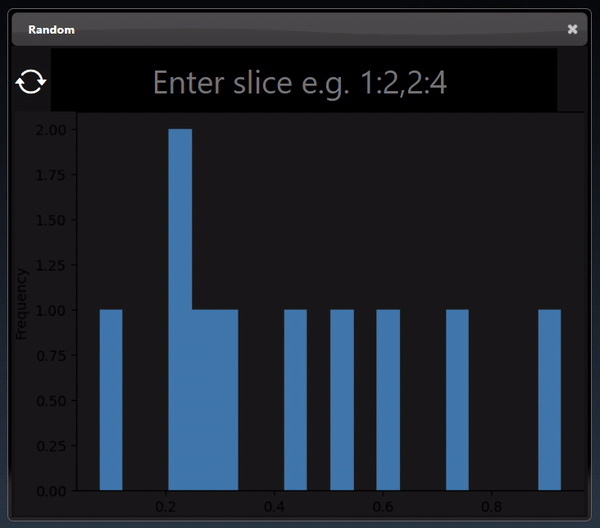
A 2D dimensional tensor can be viewed as a heatmap; a 3D height map plot; a line chart and a table:
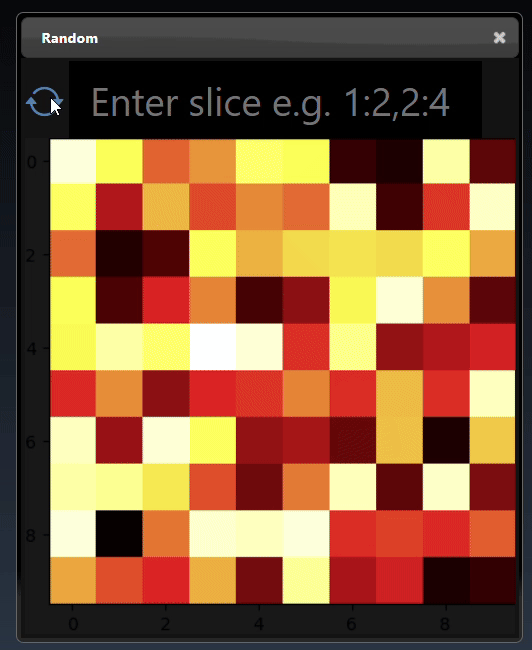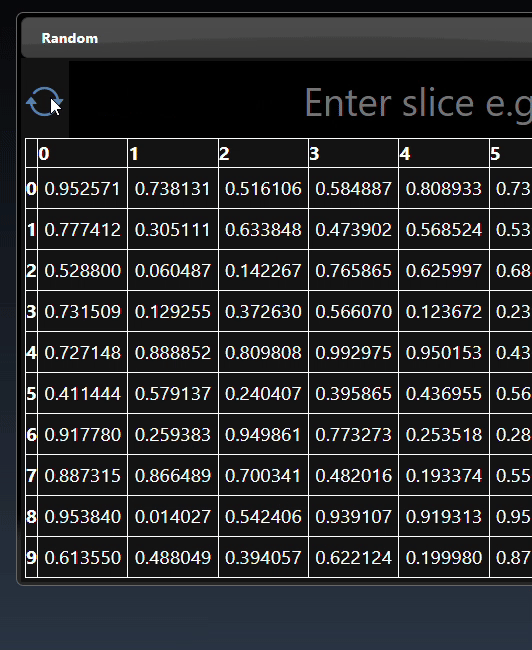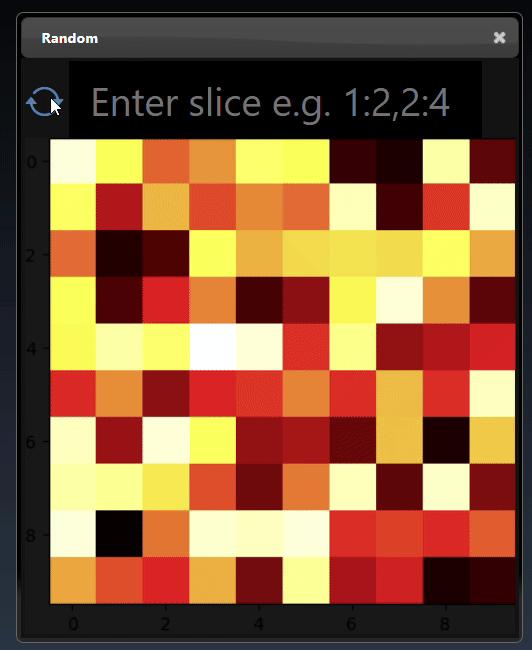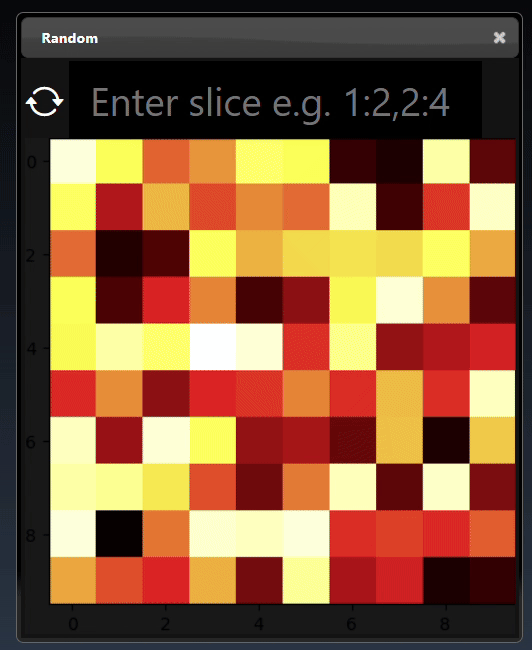
A 3D dimensional tensor can be viewed as a 3D plot and abbreviated tensor list:
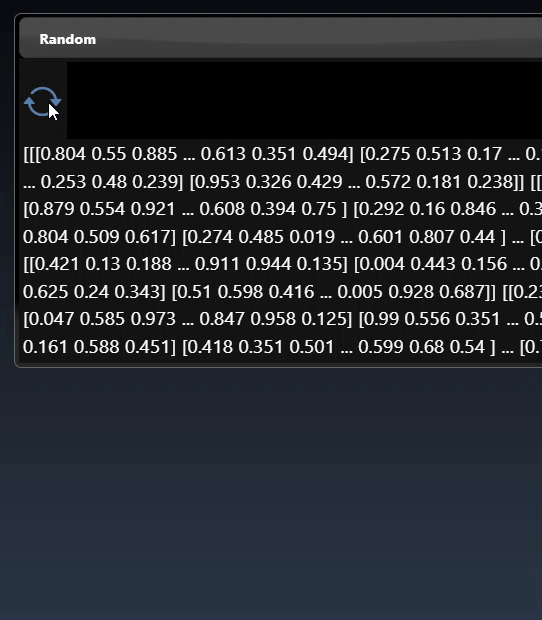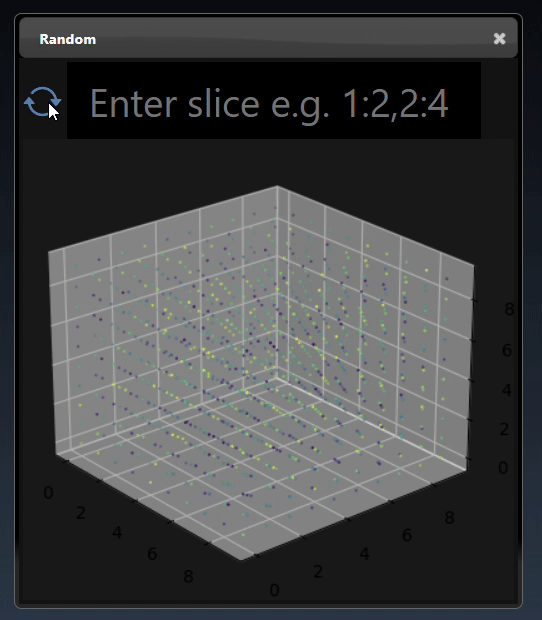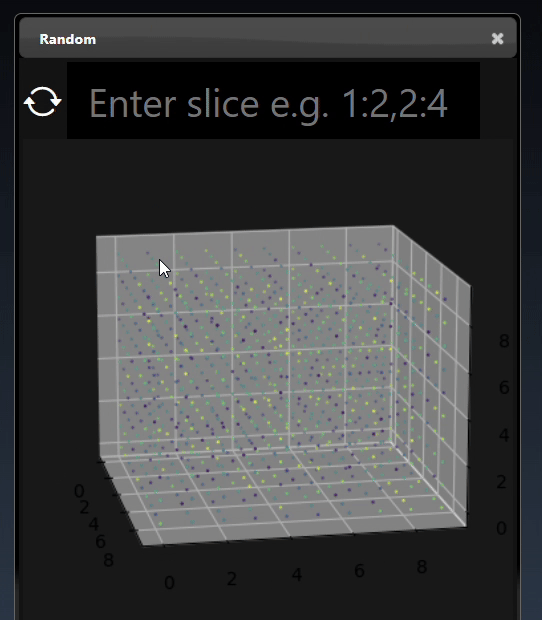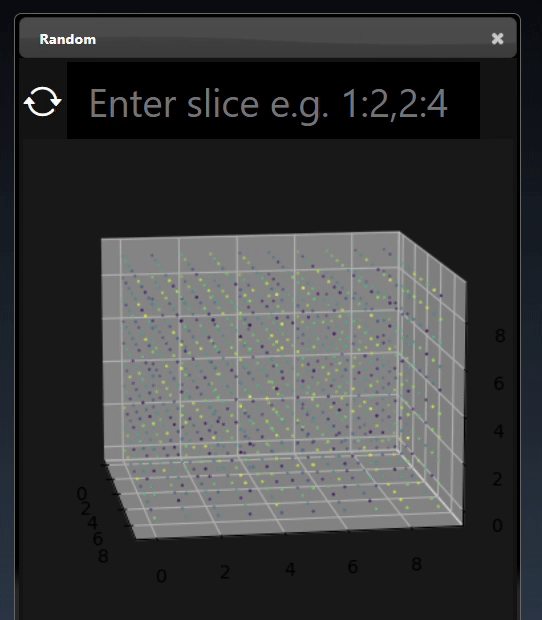
Images can also be converted to tensors (using the 'Image to Tensor' tool) and they will be viewed as a 3D image; a 3D height map plot; a 3D color space plot, and abbreviated tensor list:
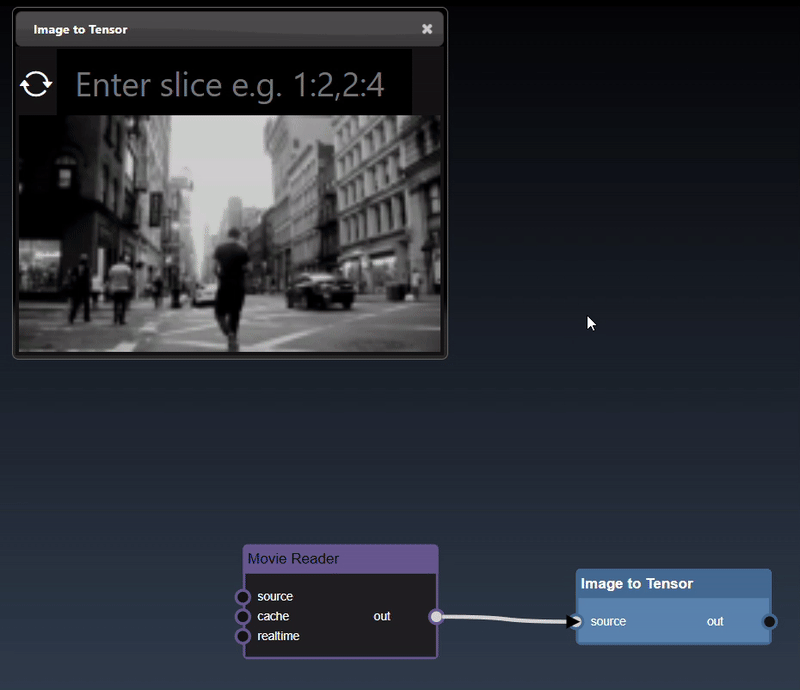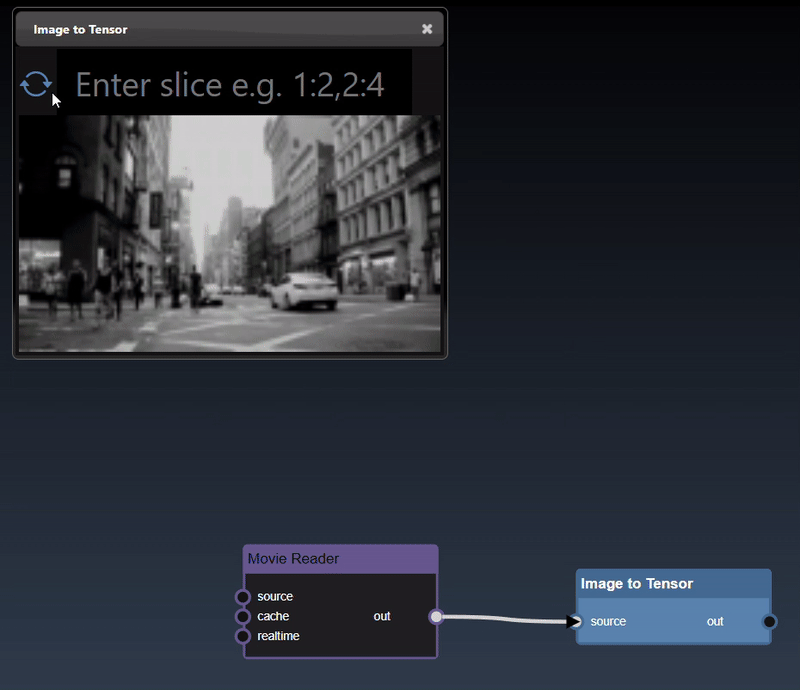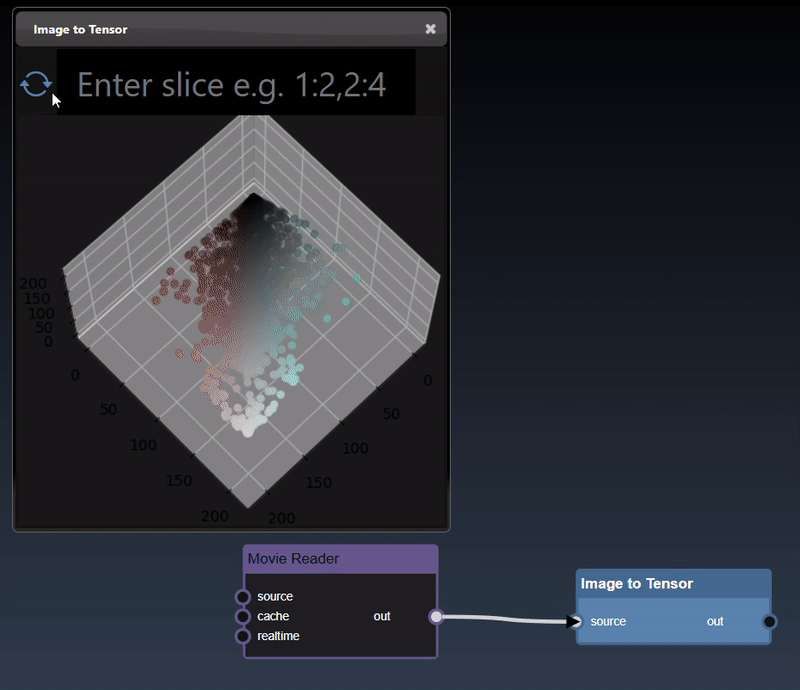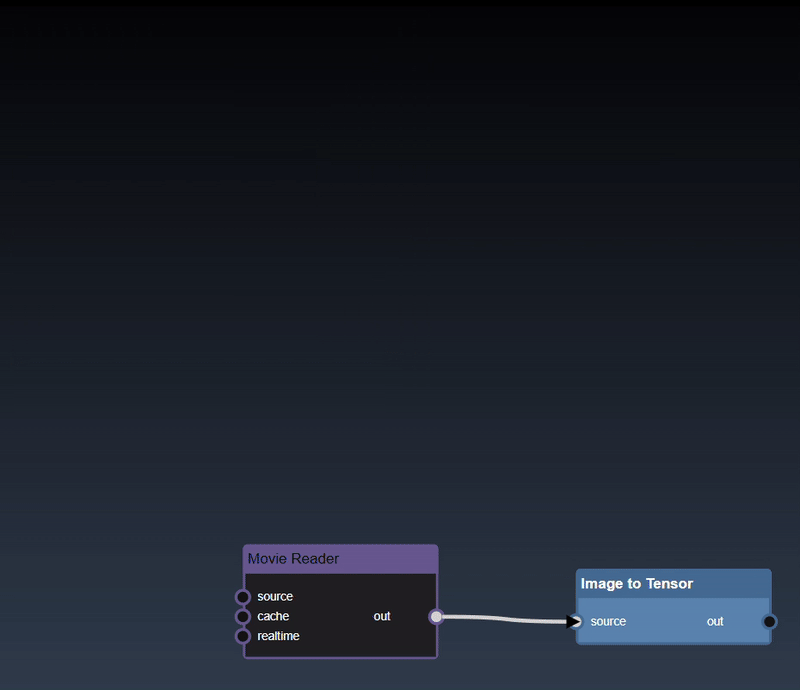
Beyond displaying images and matrices, INFINIWORKFLOW has specific UI to display one-dimensional audio data:
Audio is represented by a list of numerical intensity values over time and they are implemented using the Numpy Python module. You can get audio using the Read Audio tool for audio files or the Input Audio tool for streaming input through the microphone. The viewers in Audio nodes can display audio arrays in two different ways: a waveform and a spectrogram. It will default to the waveform visualization first, which shows the loudness of the sound at every sample over time. By clicking the , it allows you to cycle through visualizations. The other visualization is a spectrogram, which is a colormap of frequencies over time where colors represent the volume of each frequency in decibels (dB).

A set of tools, called Widgets, are available that provide user interface controls directly in the flowgraph

These widgets are an easy way to modify the parameters without having to open the Parameter Editor - you can selectively decide which parameters are important enough to add as widgets to the flowgraph. For example, the following flowgraph has a number of widgets added: a "Filebrowser Widget", a "Selection List Widget" and a "Slider Widget" are added to the flowgraph as well as two "Output Widgets":
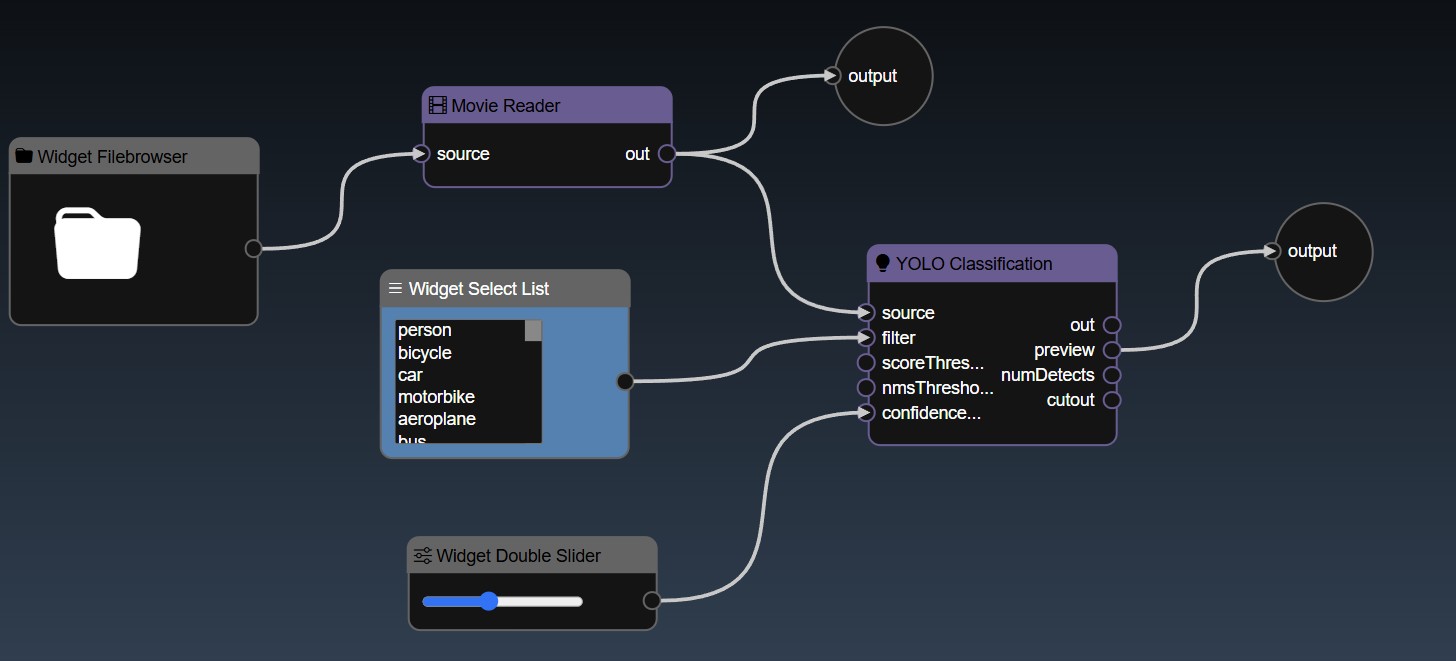
You can now modify those controls directly in the flowgraph. Furthermore, the widgets can be used in conjunction with the 'Publish' feature. You can refine how the widget will be shown in the Publish view by setting the Widgets parameters - edit the Widget in the Parameter Editor and you can set the widget attributes. Widget attributes include the name which will show in the published view for each widget. Widgets such as Sliders allow you to set their specific attributes such as the minimum, maximum and step value for the Slider widget. All widgets have the common attributes of the name and description (used for tooltips) as well as layouts. The layouts allow you to specify an optional Tab that the widget will be placed in and also the order in which the control will be ordered in the UI (a lower order will allow the control at the top of the layout). An example of the Widget Slider's parameters are as follows:
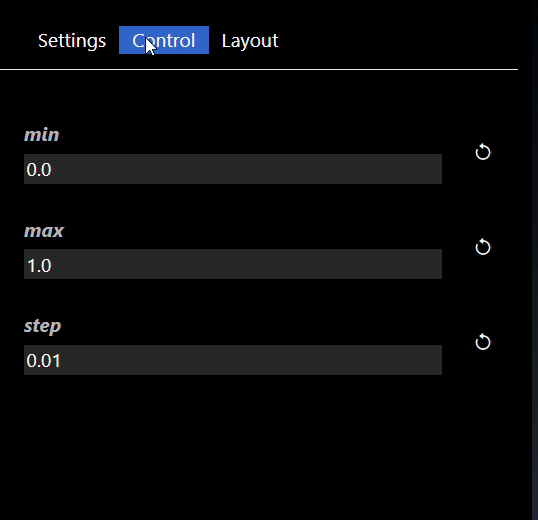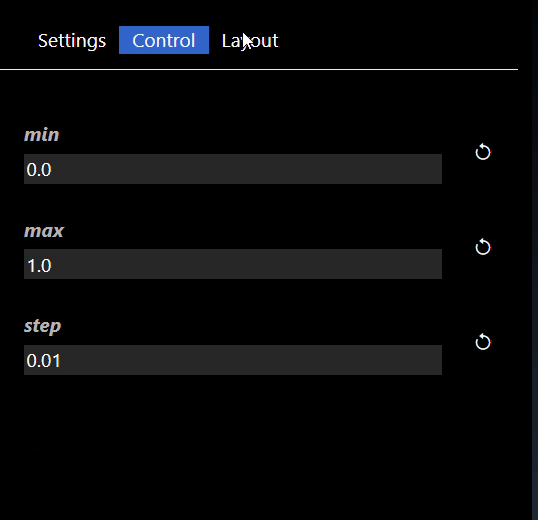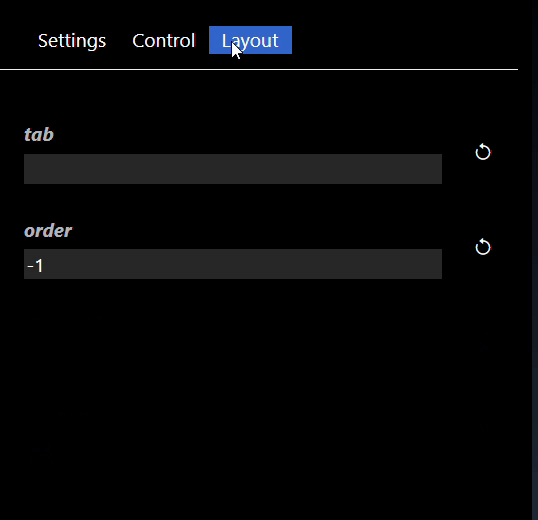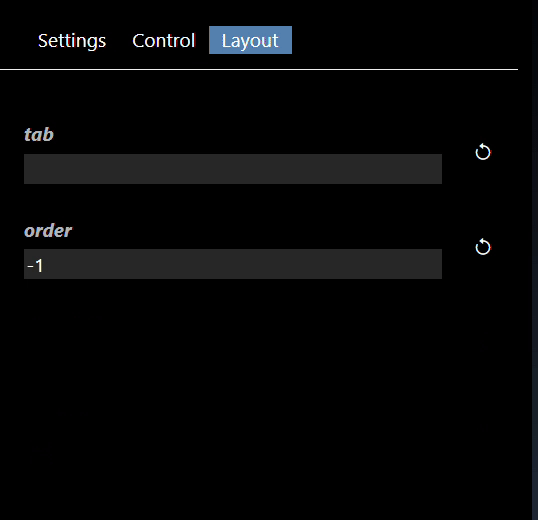
See the reference section for the full list of Widget Tools
See the section on 'publishing' to understand how you can leverage widgets in published workflows.
A set of tools, called Displays, are available that provide viewing displays directly in the flowgraph This allows you to constantly monitor the output of multiple nodes and avoid switching back and for using the Viewer. For example, the "Thumbnail Image Display" tool shows the results of a the image output of a node:
If you instead want to visualize the full size image rather than the thumbnail, you can use the 'Full Image Display' tool. This shows the image at the actual resolution in pixels in thr flowgraph:
You can also display a matrix (matrix2D) output using the 'Matrix2D Display' tool that shows the results in the form of a table:
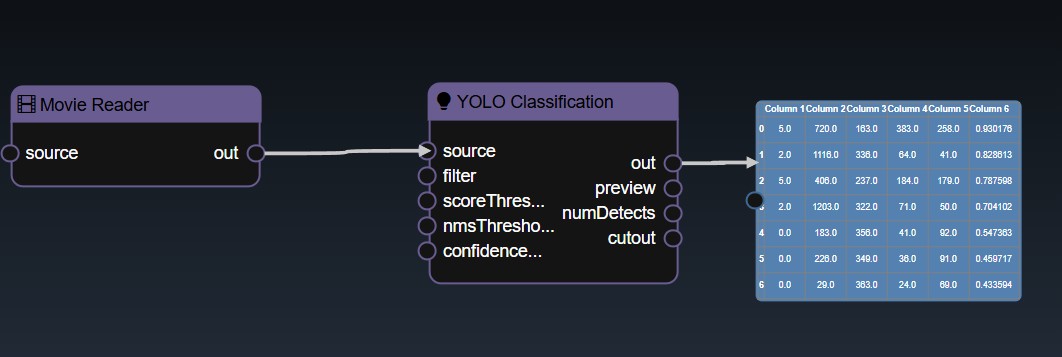
DataFrames can also be displayed as tables on the flowgraph using the 'DataFrame Display'. The first few rows of the table are shown, and double clicking the display node will show the other visualizations (such as the statistics and datatypes views):
Tensors can be displayed using the 'Tensor Display'. Double clicking the node will show the other visualizations for the tensor:

Additionally, displays are available for all the other types such as integers, doubles, booleans etc. These displays are useful to get realtime visualization of the various node outputs in your flowgraph:
See the reference section for the full list of Display Tools
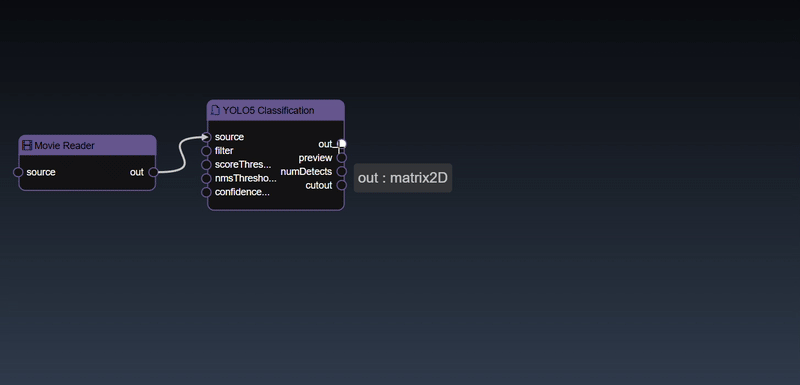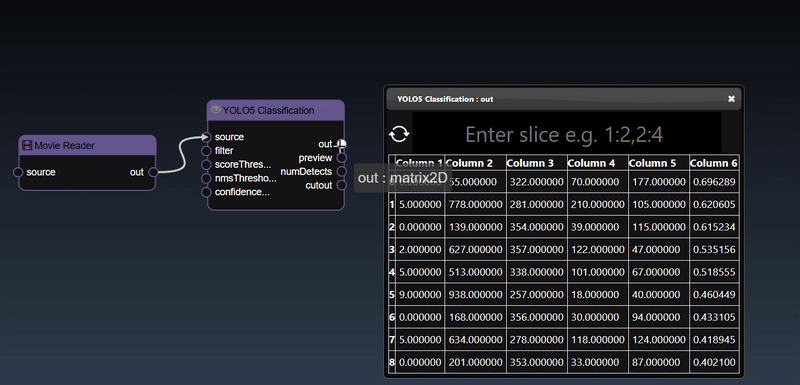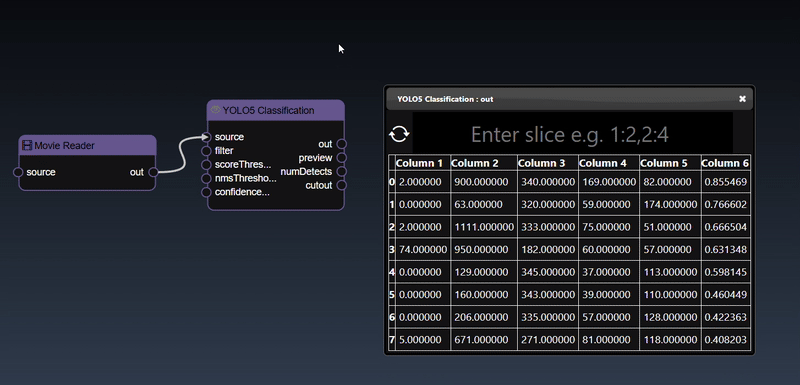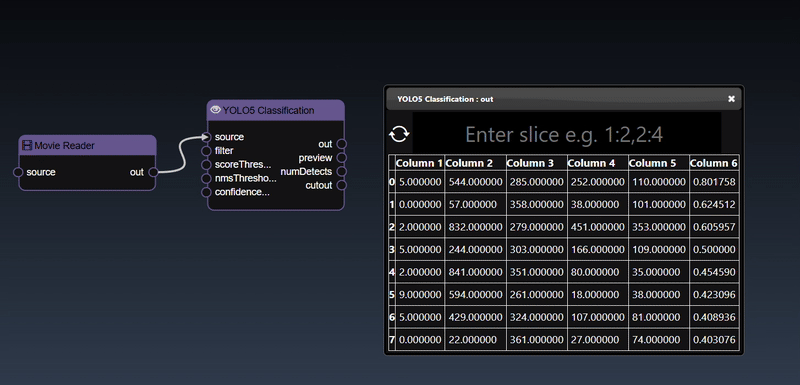
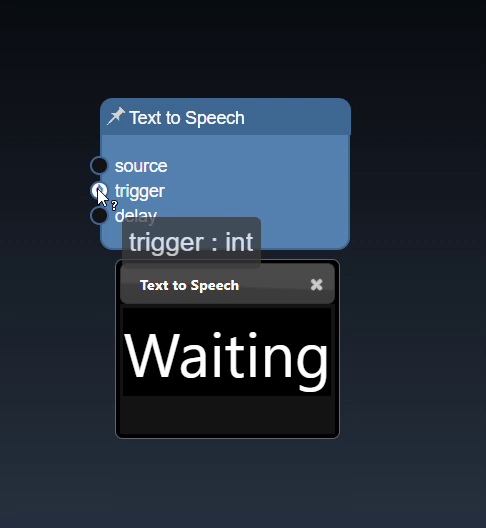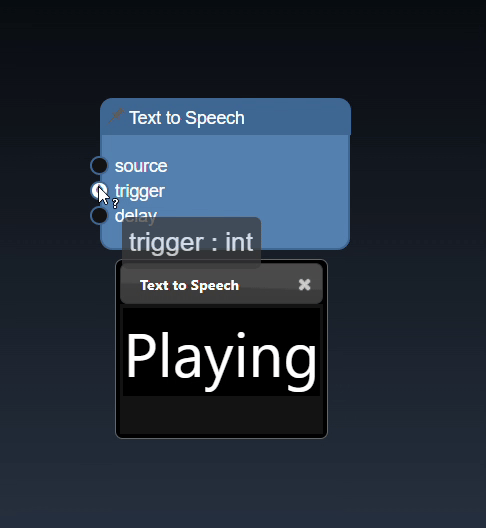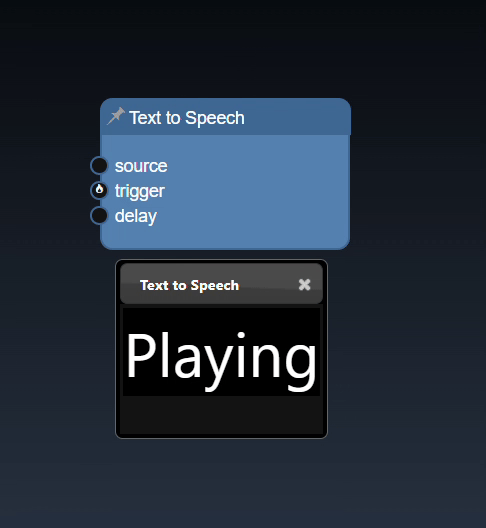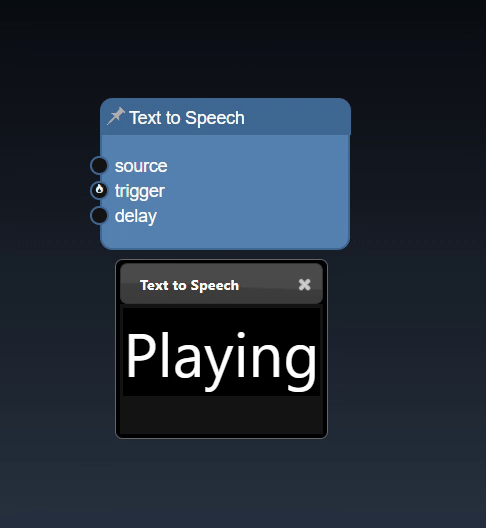
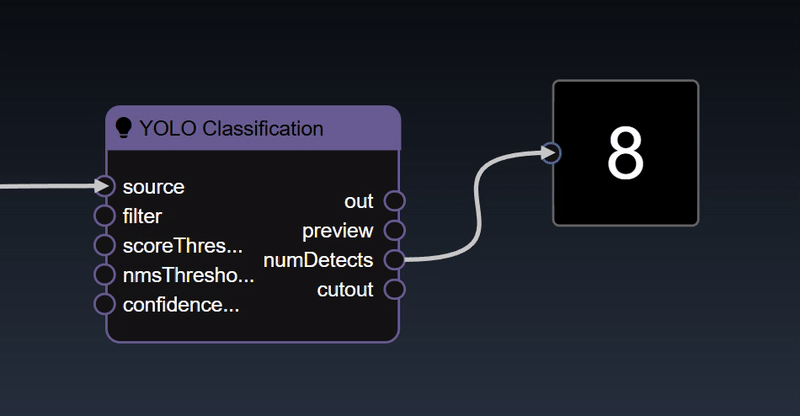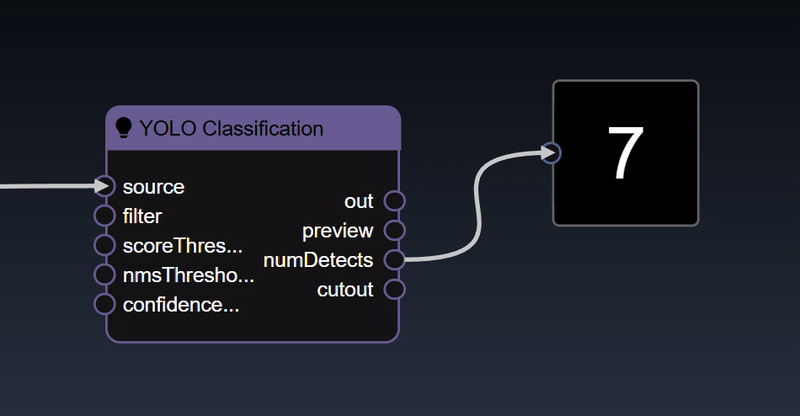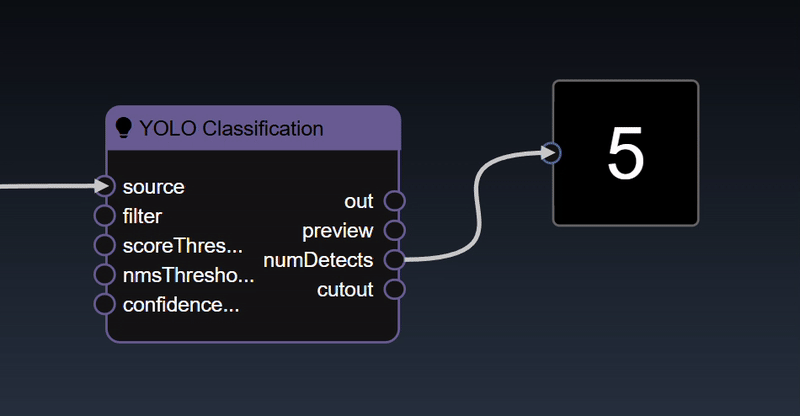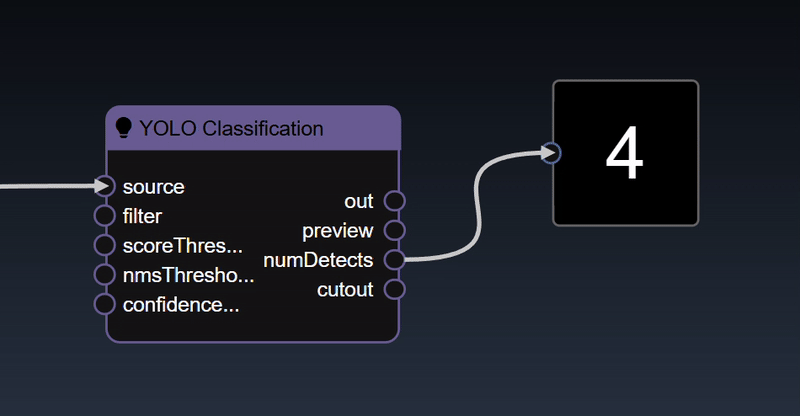
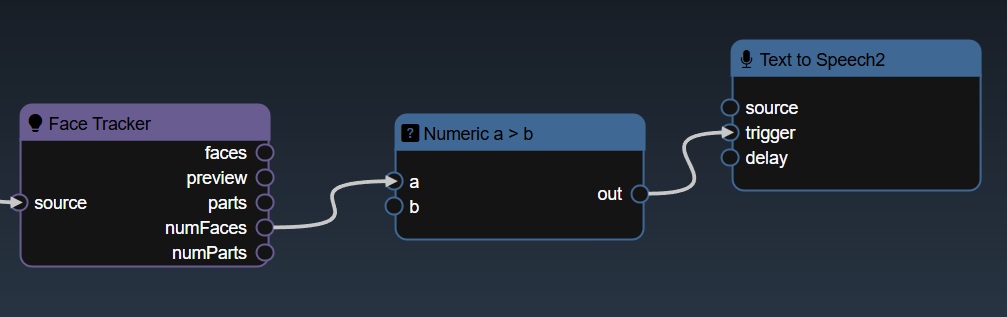
You can create triggers to activate certain nodes that require the trigger to start execution. Typically, you can use the various boolean expression - for example, in the workflow below, the number of detected faces is applied to a "Numeric a>b" tool, this will yield a true value whenever the number of faces is greater than a certain amount. The output of this node is a "trigger" that is used to execute the "Text to Speech" node.
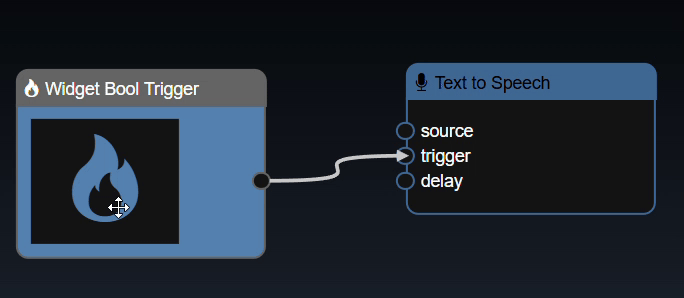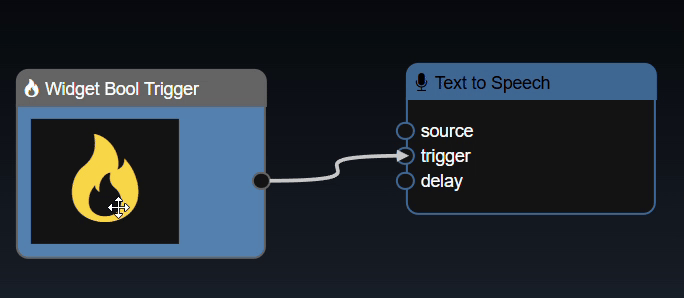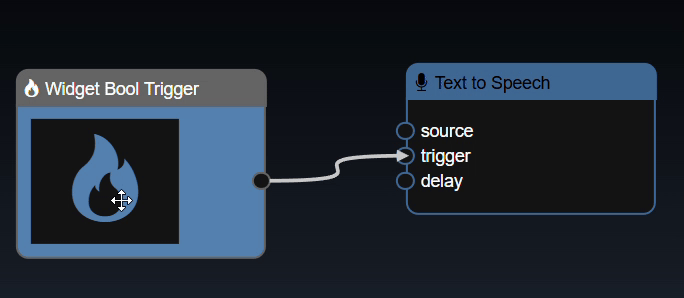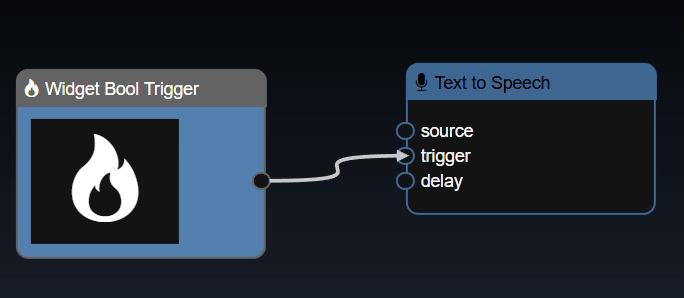
As well as creating triggers automatically based on your outputs of the nodes on your flowgraph, you can also create manual triggers. The Widgets include a "Widget Bool Trigger" and a "Widget Int Trigger". A bool trigger creates a "binary pulse", whereas an int trigger generates a staircase function. Both are useful to manually trigger a node or use one trigger to manually trigger multiple nodes.
Loop Triggers is allows you to update a Trigger Variable based on when downstream Python nodes have executed and trigger an upstream Python node. This allows you to do "for" loops as the workflow graph is acyclic - meaning no edges can connect a downstream node to an upstream node, so loops are not allowed. However, with this feature you can make a trigger happen upstream when a downstream node is executed. You can add two new nodes, 'Loop Variable' and 'Loop Trigger':
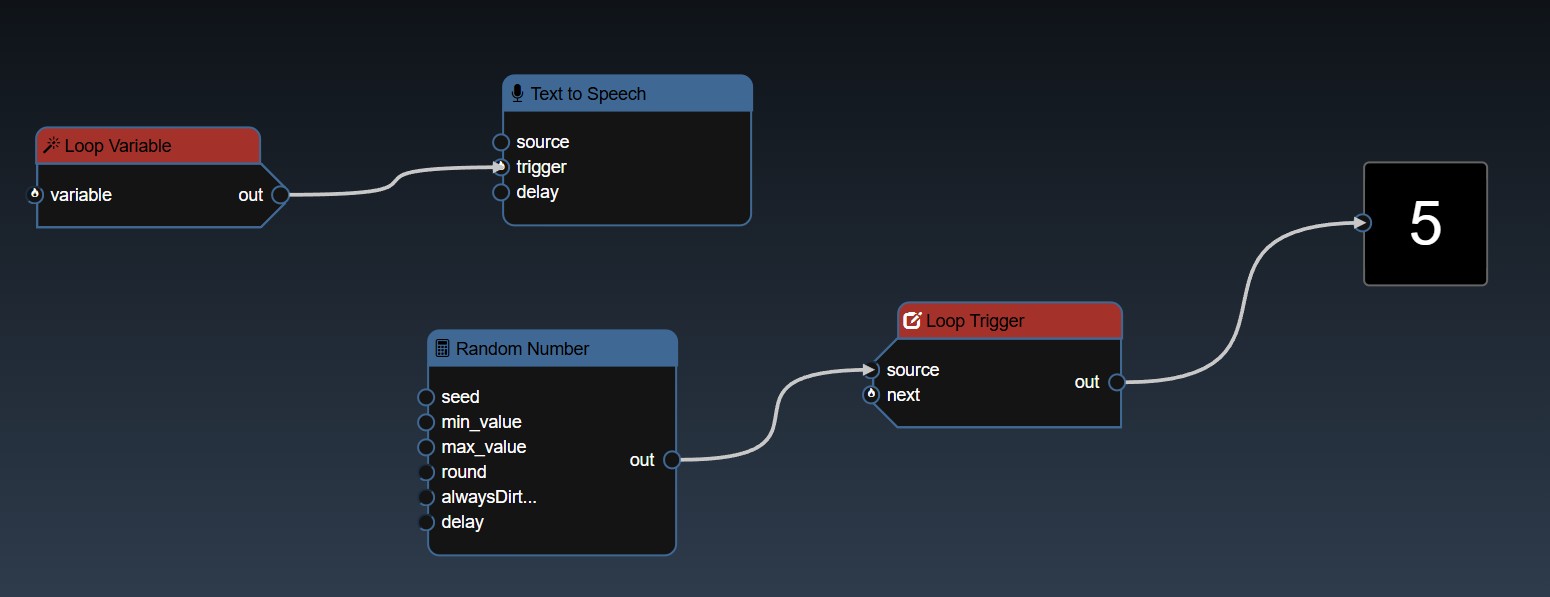
The Loop Trigger when the source has changed (or you click the next trigegr), will use the referenced Loop Variable and will trigger the output of the Loop Variable. The Loop Variable can be placed upstream and flow back to the Loop Trigger, and thus this forms a loop cycle. You can use Loop triggers to perform simulations which may require multiple passes of the workflow nodes.
Infinicam is a high-speed streaming camera capable of capturing and transferring 1.2-megapixel of image data to PC memory at 1,000fps via USB 3.1. Infiniworkflow, on top of all of its many other functionalities, is designed to be a platform for using Infinicam(s) and saving Infinicam footage. There are certain differences between nodes related to Infinicam and most other nodes, so if you will be using an Infinicam, reading through this section is the fastest way to understand everything Infiniworkflow can do with your Infinicam.
The following section will be broken into 3 parts: the Infinicam viewer node and the Infinicam saving nodes.
When an Infinicam is plugged in, a node called "Infinicam" will come up. This node allows you to view the Infinicam, and also set the preroll and postroll frames (pre/postroll frames will be discussed later). If multiple Infinicams are connected, each Infinicam will show up as its own node (i.e. "Infinicam", "Infinicam #2", etc). Note that the Infinicam may take a few seconds to open. Also note that this node only allows you to view the Infinicam; saving is done separately.
Infiniworkflow has 2 ways of saving Infinicam footage - "Infinicam Save Movie" and "Infinicam Save Compressed". These 2 saving nodes will come up for each respective Infinicam that is connected to your machine (in other words, if you have 2 Infinicams connected, "Infinicam Save Movie" and "Infinicam Save Compressed" save footage from the first Infinicam, and "Infinicam Save Movie #2" and "Infinicam Save Compressed #2" save footage from the second Infinicam). Note that these saving nodes do not need to be connected to the "Infinicam" viewer node itself; all that is required is that the Trigger is clicked.
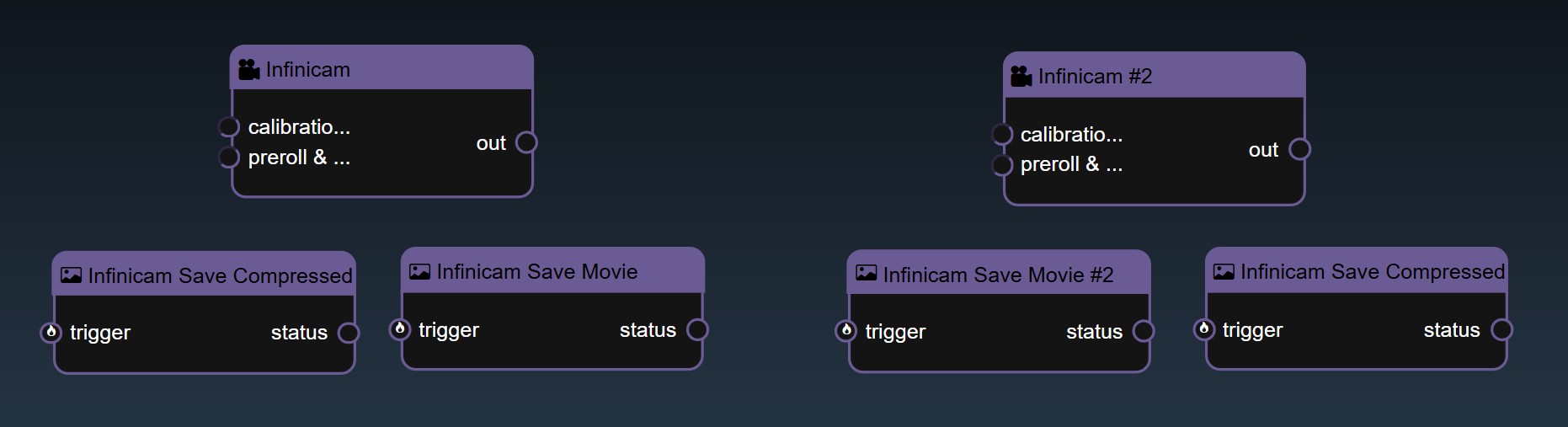
The "Infinicam Save Movie" node, upon hitting the Trigger, saves footage from the selected Infinicam in any file type (.MP4, .MDAT, etc.) and to any file location. The total number of frames of Infinicam footafe that will be saved by this node when the Trigger is clicked is based on your Infinicam's pre-roll and post-roll number of frames. To explain what these terms means, consider the following example: you wish to save footage whenever an object falls off a conveyor belt in a factory. You have a workflow that will set a Trigger to True as soon as it detects that an object has just begun to fall off the belt. To understand why objects sometimes fall off the belt, you want to save the 2000 frames of footage from before the moment the object begins falling, as well as 1000 frames of footage after that point for good measure. Thus, you will set your pre-roll to 2000, and your post-roll to 1000. When Infinicam Save Movie node is Triggered, a total of 3000 frames will be saved precisely as you want them to.
The "Infinicam Save Movie" node tends to be slower, as it needs to compress and decompress data on the fly. The "Infinicam Save Compressed" node, on the other hand, saves out compressed images, which means that the footage gets saved to your computer faster and is more informationally dense (a single 2 second video can be a few hundred megabytes). Whereas the prior node allows users to select the Codec and the File format, the "Infinicam Save Compressed" node hardcodes both, so 2 files are always returned: a MDAT file of the footage itself and a CIH file of the footage metadata.
Note for both saving nodes: if the Trigger has already been pressed and you wish to stop saving (i.e. save a shorter clip of footage), you can simply click the Trigger again to immediately save out all frames already gathered to your machine.
If you wish to view the footage that is saved from the "Infinicam Save Compressed" node, use the "Infinicam Movie Reader" node, which reads MDAT/CIH files.
Important note: by default, when "Infinicam Save Compressed" is Triggered, the number of frames that will be saved will be equal to the Infinicam's preroll plus postroll. However, if you wish to save out Infinicam footage continually, you can click the checkbox in the "Infinicam Save Compressed" editing menu for "Constant Saving". When true, you may set the maximum file size you wish for the saved Infinicam footage. When the node is Triggered now, footage will continue to save into the file you created until the maximum file size limit has been reached.
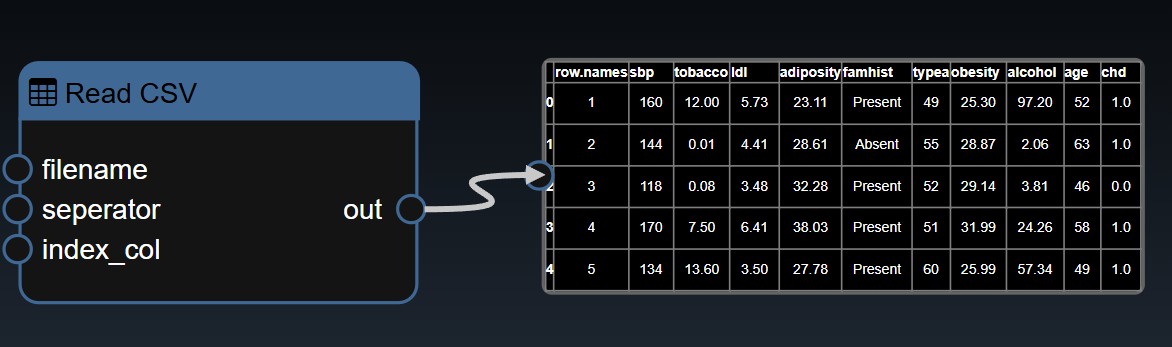
The Data Science tools are all under the Data Frame category. The implementation is based on Pandas, an open source data analysis and manipulation library. A DataFrame can be loaded with the "Read CSV" or "Read Excel" tools or created programmatically with the "Random Table" tool or converting from numpy or tensors. For many of the tools, they will use "Column" or "Columns" properties representing a choice of a single column or a subset of columns. Some of the tools also have an "arg" property which is a map parameter that allows you to pass in additional key/value pair optional arguments The Key/Value Dialog UI will show the corresponding Pandas function's documentation which is useful to determine the additional parameters you wish to set.
See the reference section for the full list of Data Science Tools
A number of tools are available to create charts for DataFrames. These tools are all under the Plot category. Each plot tool has parameters placed into two different tabs: Data and Layout. The Data parameters allow you to set the columns you wish to plot and the Layout parameters allow you to adjust the title of the chart etc. For example, the "Line Plot" tool has the following Data parameters:
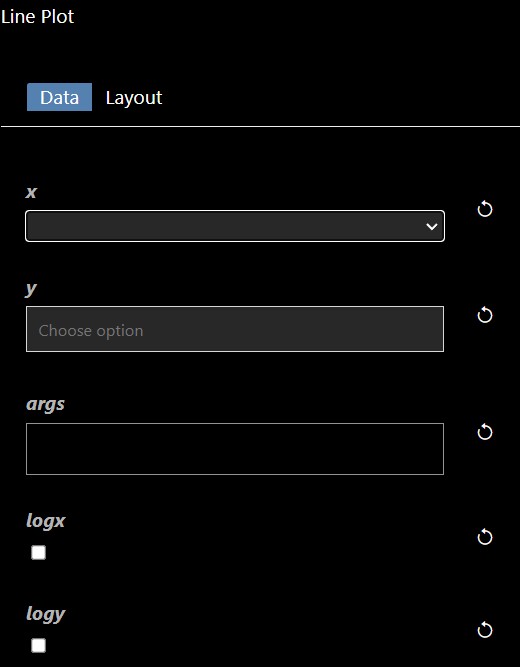
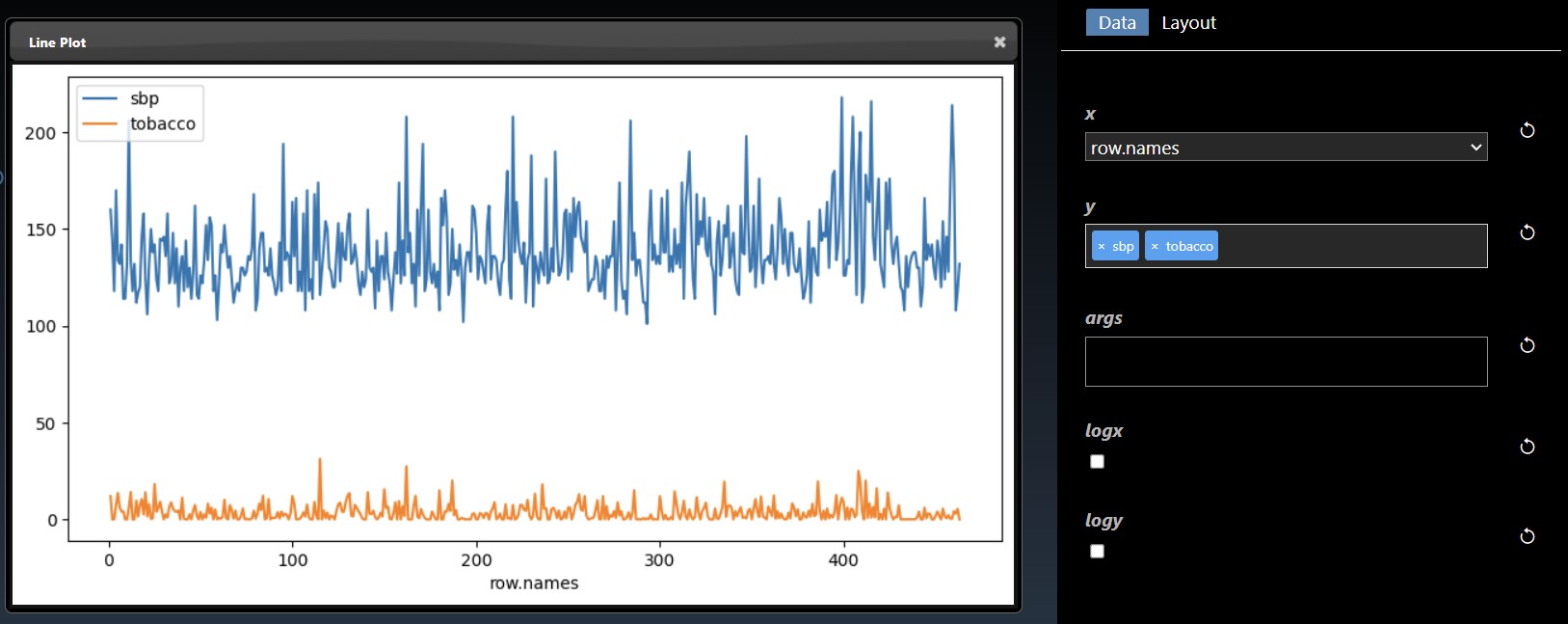
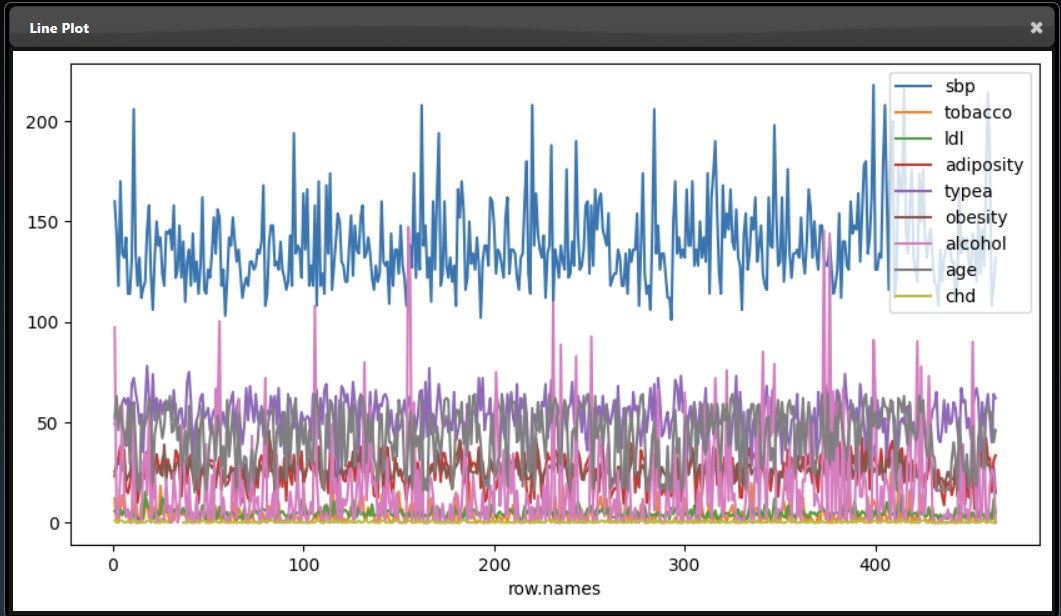
The X and Y allow you to set the columns you wish for the X and Y-axis. If no columns are set for the Y-axis then the plot will include all numerical columns in the DataFrame. If the X parameter is not set then the index of the DataFrame will be used as the X-axis. In the example, below two columns (sbp and tobacco) are plotted for Y against the "row.names" column:
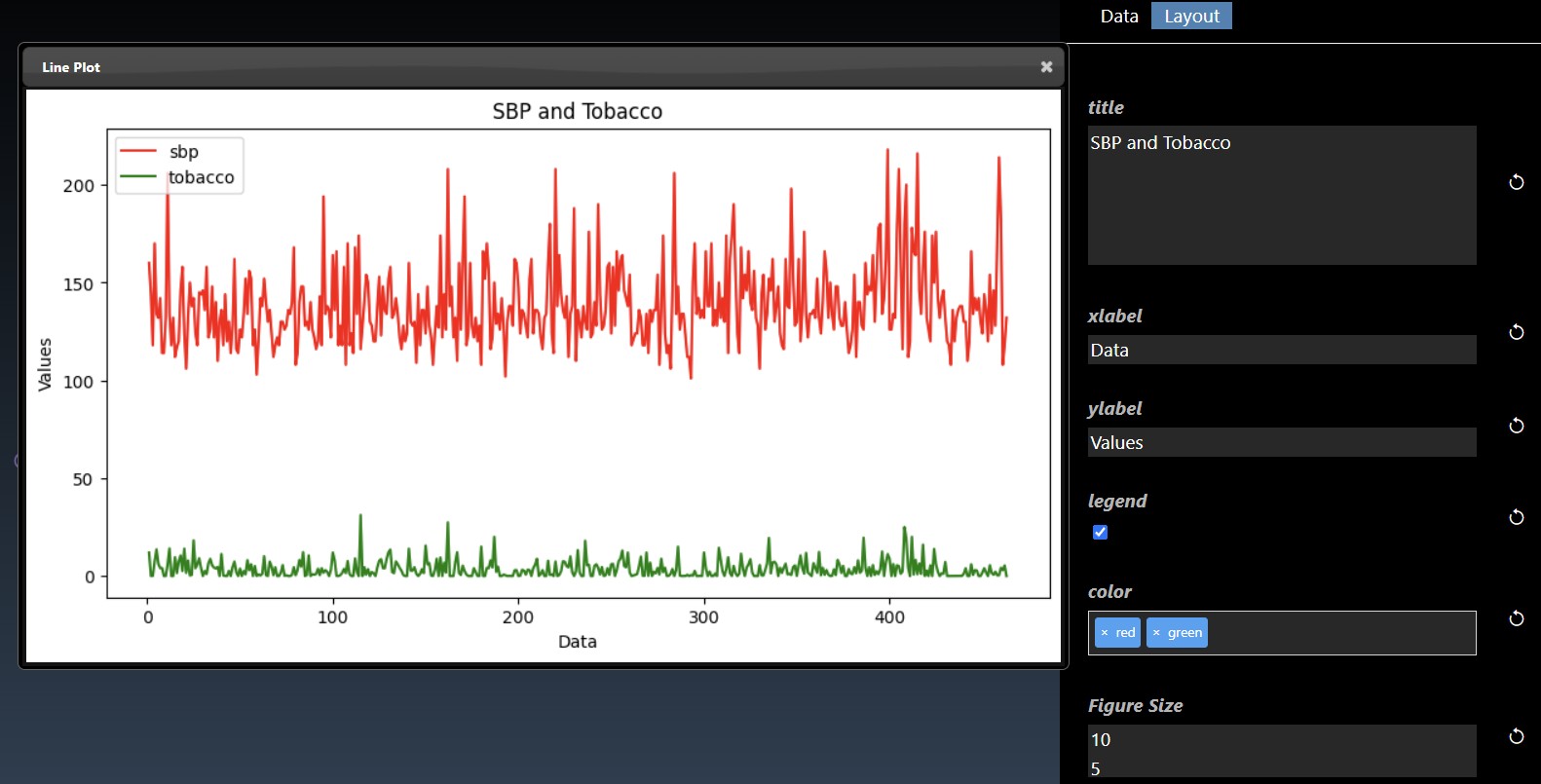
The Layout tab allows you to specify the title for the chart as well as the labels for the axis. You can also hide or show the Legend and set the size of the figure in inches. The "color" parameter is a multi-selection list parameter that you can set colors such as "red", or #6580ab etc. If you have two Y columns you plot then if you set one color both line charts will use the same color but if you set two colors in the list then you can distinguish each line chart.
An subset of the plot tool visualizations are as follows:
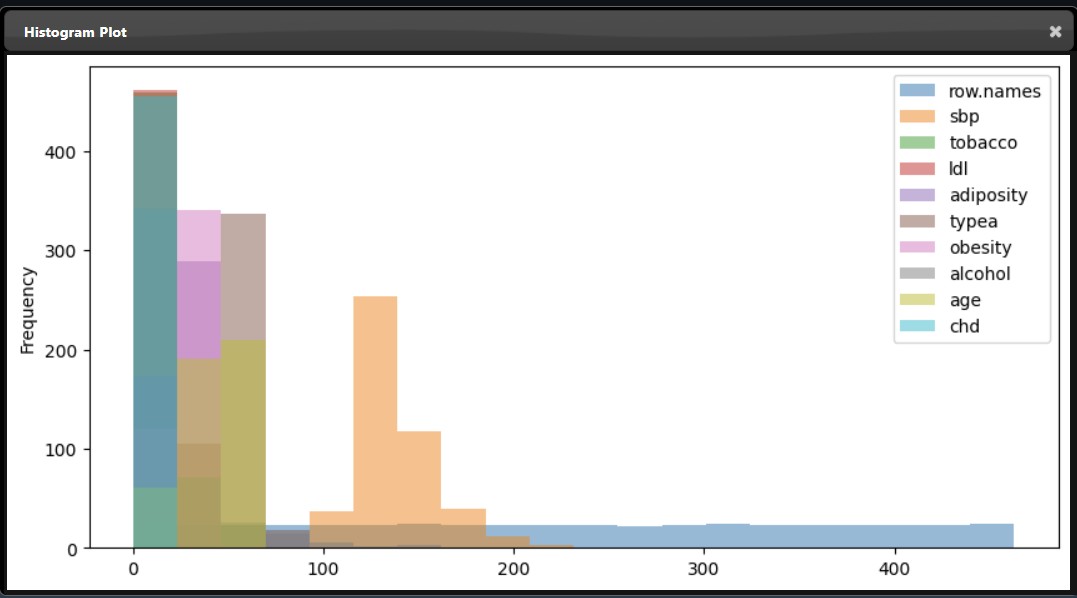 |
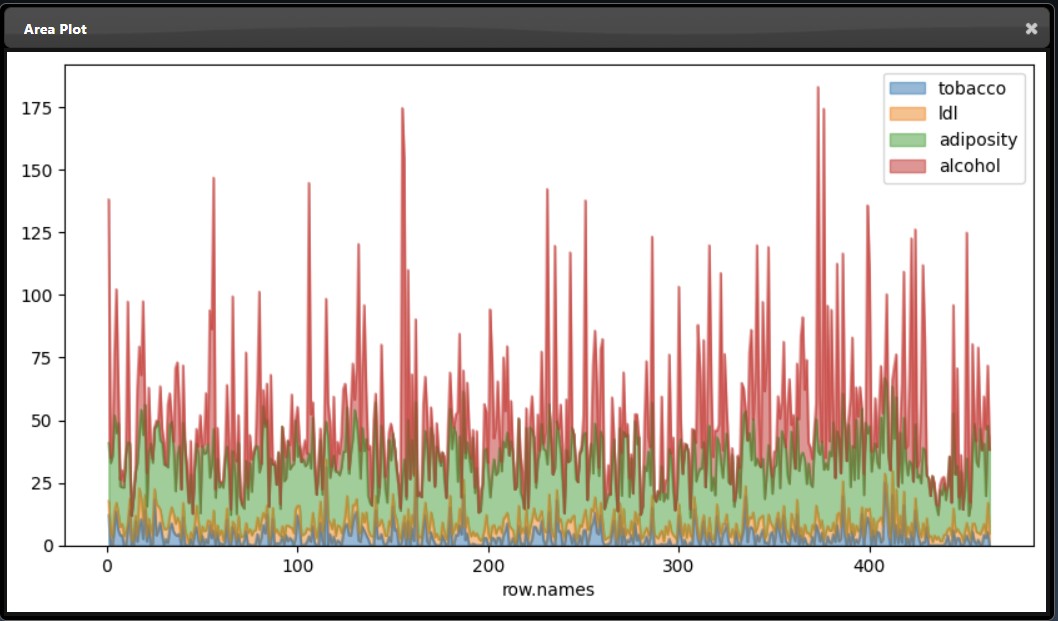 |
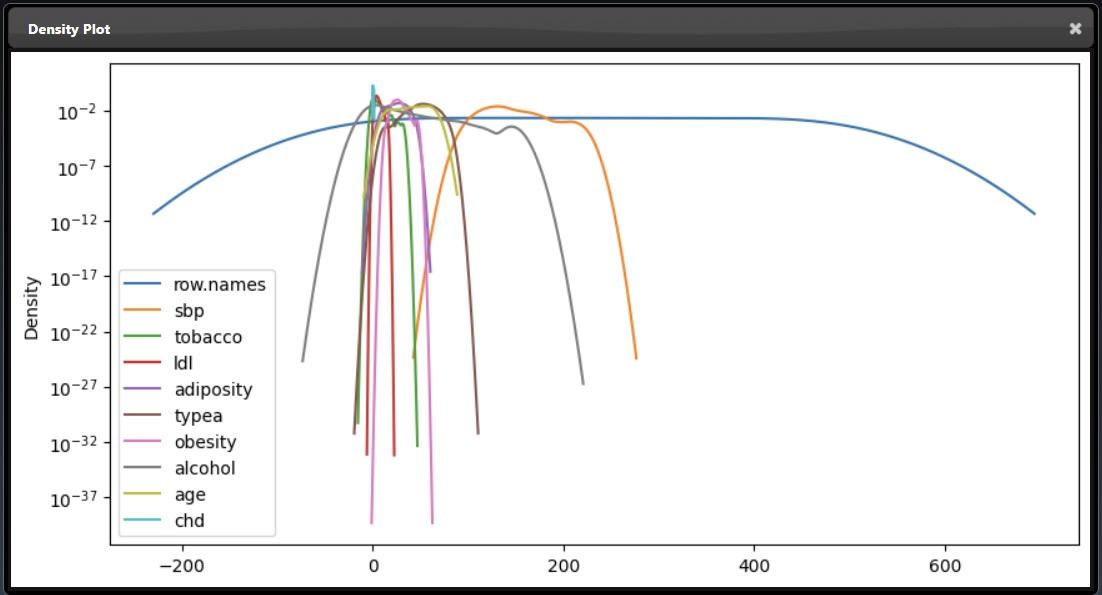 |
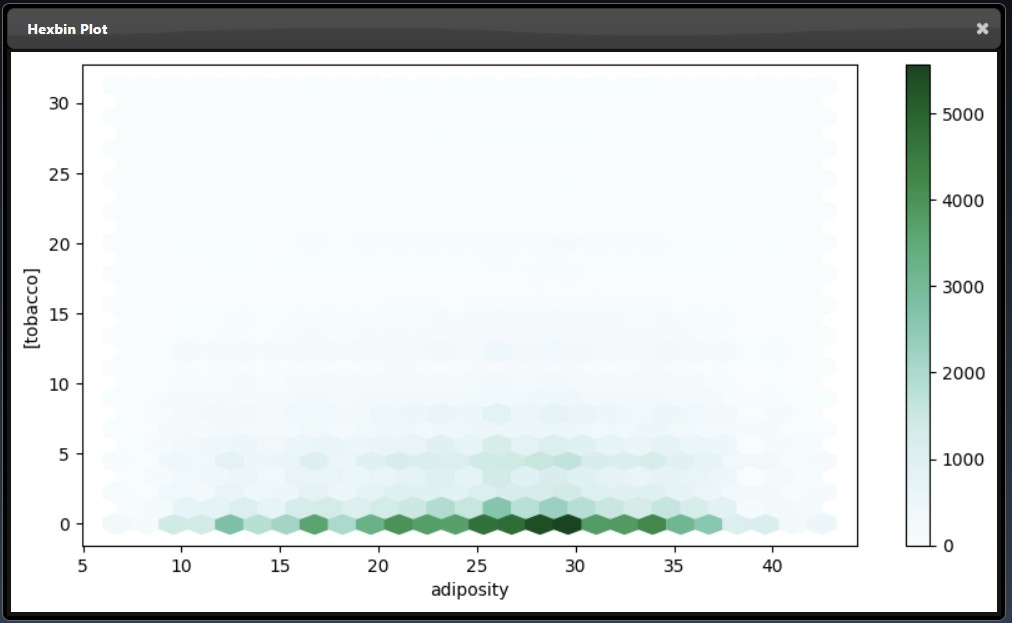 |
 |
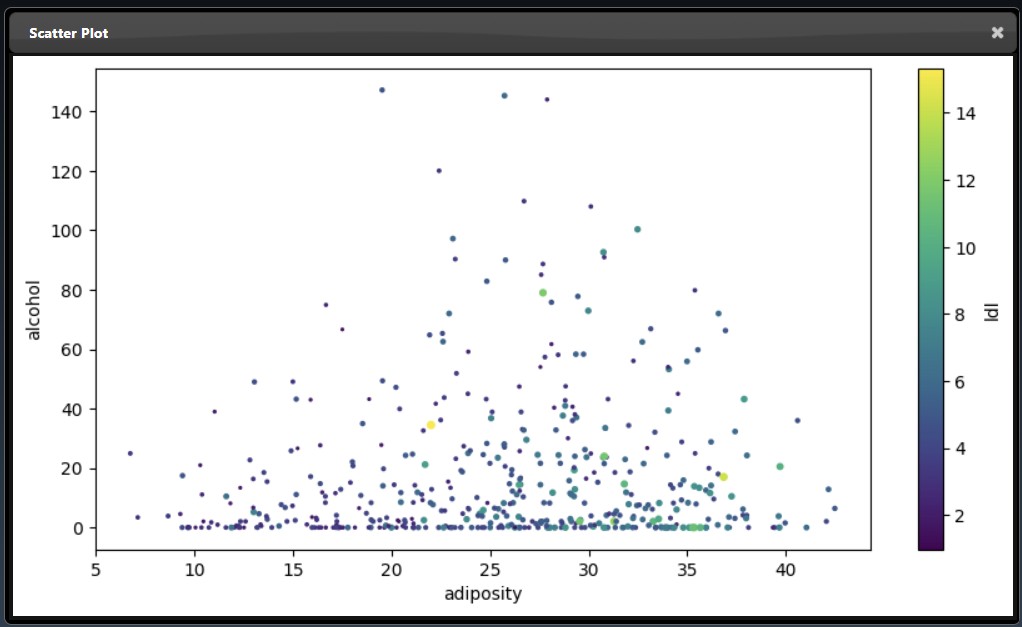 |
See the reference section for the full list of Plot Tools
The Machine Learning filters are based using scikit-learn Python module are all under the ML category. Each ML tool has 3 tabs: Train, Hyperparameters and Export. The Train parameters allow you to set the X and Y columns as well as a trigger to start the training. As training can be slow so a trigger is used to start the process, however, when doing a grid search, the trigger is automatically generated. An example of the training parameters for the 'Logistic Regression' ML Tool is shown as follows:
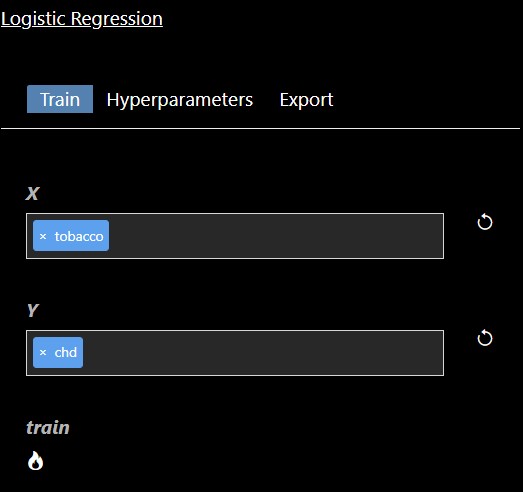
In this scenerio, we are training a model based on the tobacco column to predicy heart disease (chd). Clicking the "train" trigger will start the process of fitting the data to create a ML model. The Hyperparameters tab has the specific hyperparameters that allow customization and tuning of the model. The hyperparameters for the logistic regression tool are as follows:
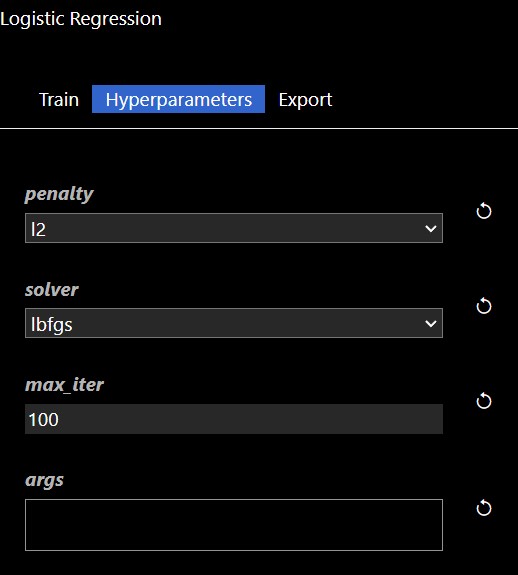
Each ML training tool will have a different set of hyperparameters and these will show up in the Grid Search dialog. Additionally, an "arg" map parameter is also included which allows you to set any parameters that are not in the UI - this is a map of key/values pairs. After clicking the "arg" widget, the Key/Value dialog appears that shows the documentation of the ML model, this is useful so you can review any additional parameters you may wish to set:
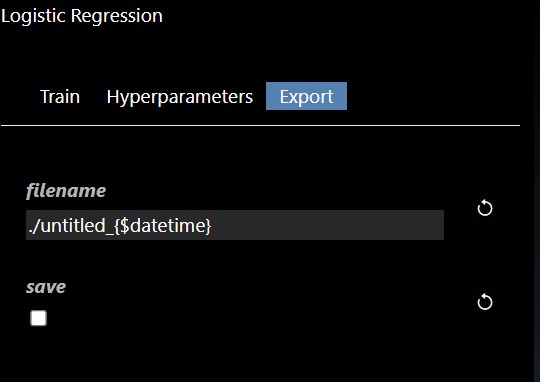
The Export tab allows you to set whether you want to save the model to a file, by default models will not be saved but it is recommended to save your models whenever you have complex models that take time to execute. A common practice when doing grid search is to connect the "Is Batch" Tool to the "save" input parameter of the model - this will always be true when a grid search is done in a background batch process - thus, the models will be saved during the grid search process.
The typical approach to building models involves splitting your training data into test and train splits. The following workflow illustrates the steps involved and the nodes required to implement the training:
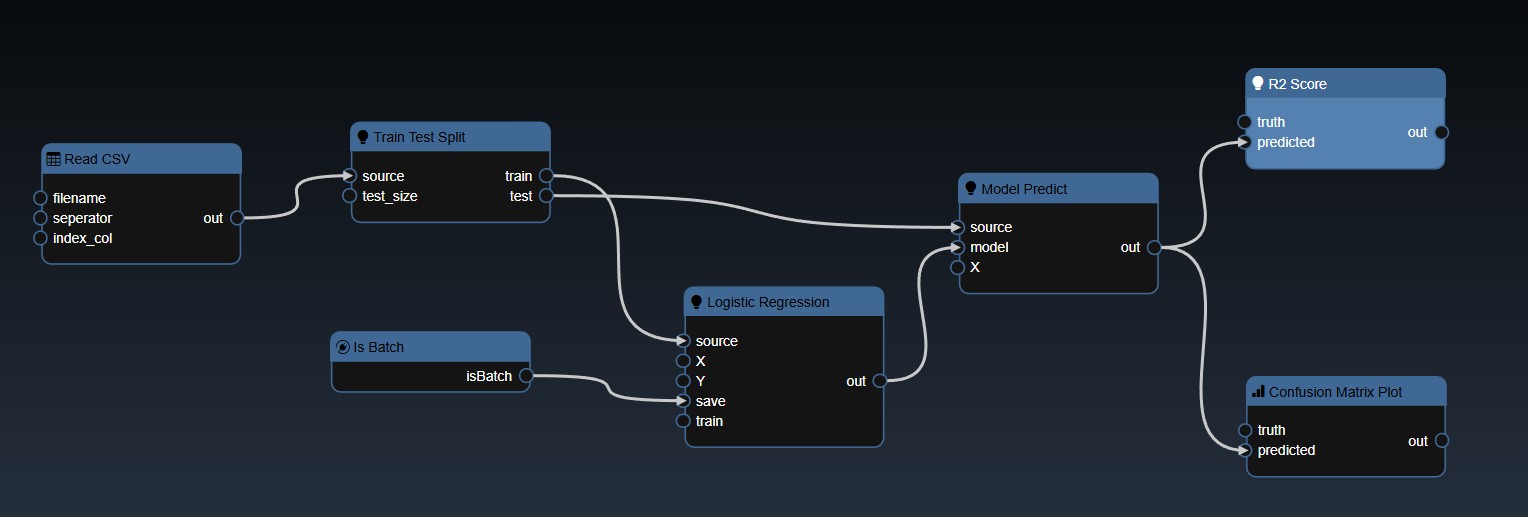
The CSV file is read and then a test train split is done, the training table is then passed to the ML model. In this case the "Is Batch" Tool is used to set the "save" parameter which will automatically save the model for any Grid Search. The output of the model is then passed to a model predict and the predicted values can be compared against the ground truth to establish the accuracy of the model. In this scenerio, we use a confusion matrix to plot the accuracy of the results. And a ML metric nodes such as "R2 Score" allow you to see the accuracy and it can be further used to initiate a Grid Search.
See the reference section for the full list of ML Tools
The AI Inference algorithms including using pretrained models tools are all under the AI category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Body Pose COCO |
|
| Body Pose COCO detection using CAFFE model The following package is required: pose |
|
| Body Pose MPI |
|
| Body Pose MPI detection using CAFFE model The following package is required: pose |
|
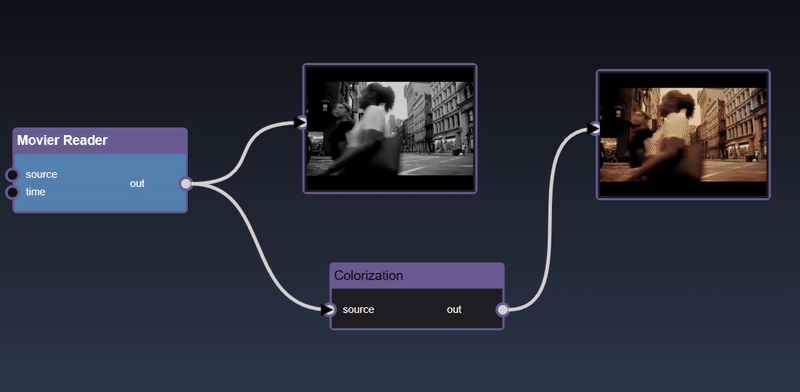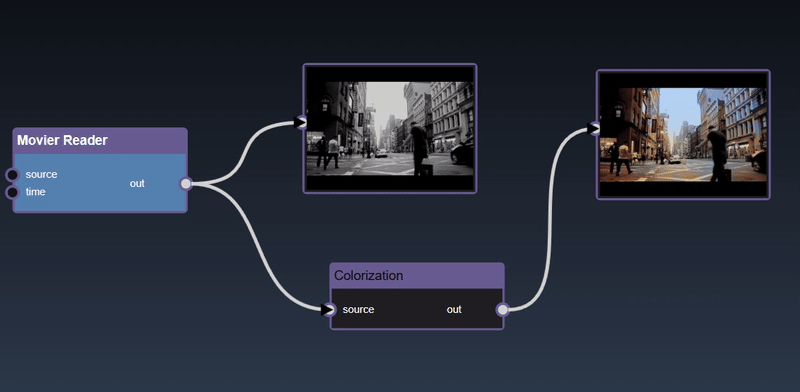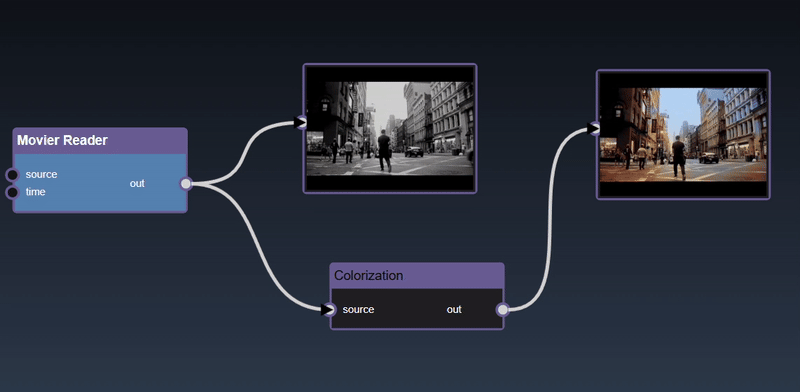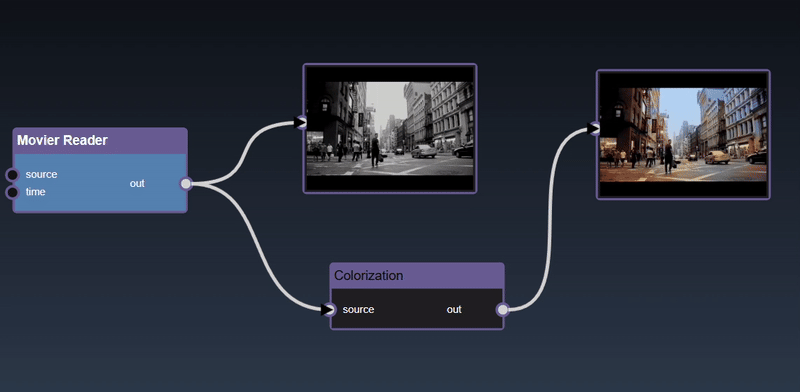
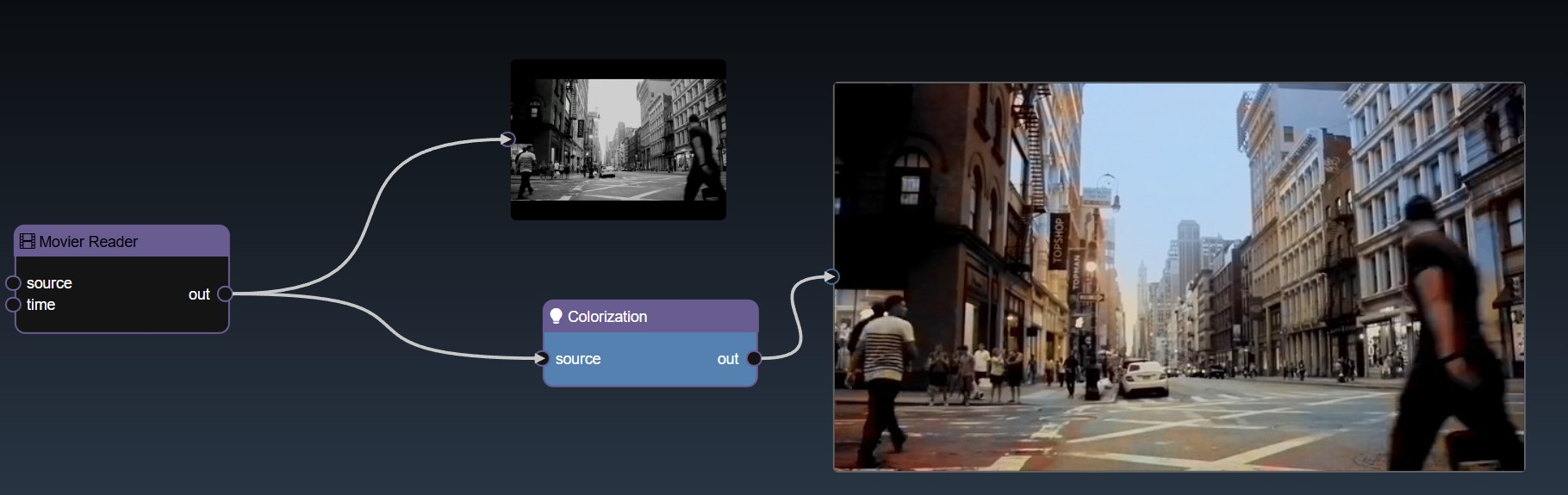
| Colorization |
|
| Colorization The following package is required: colorization |
|
| Depth Inference |
|
| Detects depth using ONNX model The following package is required: midas |
|
| Holistically-Nested Edges |
|
| Detects edges using CAFFE model The following package is required: edge |
|
| Dexined Edge Detect |
|
| Detects edges using ONNX model The following package is required: dexined |
|
| YuNET Face Detect |
|
| Detect faces using YuNET ONNX model. This model can detect faces of pixels between around 10x10 to 300x300 due to the training scheme. The following package is required: yunet |
|
| Face Tracker |
|
| Detects and tracks facial and body features The following package is required: haarcascades |
|
| YuNET Facial Expression |
|
| Detect facial expressions using YuNET ONNX model: angry, disgust, fearful, happy, neutral, sad, surprised. The following package is required: yunet |
|
| Handpose Estimation |
|
| Detects palms and fingers based on OpenPose neural network model. In out, the 1st column is the id of the point, the 2nd and 3rd are the coordinates of that point, and the 4th column is the confidence. The following package is required: pose |
|
| Human Parsing Inference |
|
| Parses (segments) human body parts from an image using opencv's dnn The following package is required: human |
|
| Human Segmentation Inference |
|
| Perform segmentation on humans using PPHumanSeg model. The following package is required: human_segmentation |
|
| Mask Inference |
|
| Mask labels objects based on RCNN neural network model The following package is required: mask_rcnn |
|
| ONNX for Basic Classification |
|
| Performs basic Classification using custom ONNX model The following package is required: onnx_runtime_windows |
|
| ONNX for Basic Segmentation |
|
| Performs basic Segmentation using custom ONNX model The following package is required: onnx_runtime_windows |
|
| ONNX for Regression |
|
| Performs Regression using custom ONNX model The following package is required: onnx_runtime_windows |
|
| Onnx Runtime Classification |
|
| Onnx Runtime Inference for Classifications The following package is required: onnx_runtime_windows |
|
| Onnx Runtime YOLOX |
|
| Onnx Runtime Inference for YOLOX The following package is required: onnx_runtime_windows |
|
| Person ReID |
|
| Matches a person's identity across different cameras or locations in a video or image sequence using features such as appearance, body shape, and clothing to match their identity in different frames The following package is required: personReiD |
|
| Segmentation |
|
| Parses (segments) various objects from an image using opencv's dnn The following package is required: segmentation |
|
| Speech Recognition |
|
| Detects speech | |
| Text Spotting |
|
| Spots text in images using DNN The following package is required: text_spotting |
|
| YOLO3 Classification |
|
| Detects and labels objects based on YOLO neural network model The following package is required: custom_yolo3 |
|
| YOLO5 Classification |
|
| Detects and labels objects based on YOLO5 neural network model The following package is required: yolo |
|
| YOLOX Inference |
|
| YOLOX is a high-performing object detector The following package is required: yolox_inference |
The Audio filters tools are all under the Audio category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Amplify Audio |
|
| Makes audio louder or quieter The following package is required: audio |
|
| Bandpass Audio |
|
| Filters out low and high frequencies The following package is required: audio |
|
| Classify Audio |
|
| Outputs the sounds detected and their confidence scores The following package is required: audio_classify |
|
| Concat Audio |
|
| Combines audio files and saves it The following package is required: audio |
|
| Fade Audio |
|
| Fades into and out of audio The following package is required: audio |
|
| Frequency Audio |
|
| Returns min, max, average, and harmonic volume of audio The following package is required: audio |
|
| Highpass Audio |
|
| Filters out low frequencies The following package is required: audio |
|
| Input Audio |
| Streams audio from microphone The following package is required: audio |
||
| Length Audio |
|
| Returns length of audio The following package is required: audio |
|
| Lowpass Audio |
|
| Filters out high frequencies The following package is required: audio |
|
| Output Audio |
|
| Plays audio stream The following package is required: audio |
|
| Play Audio |
|
| Plays Audio from an audio object The following package is required: audio |
|
| PYIN Audio |
|
| Uses the probabilistic YIN algorithm to return fundamental frequency of audio The following package is required: audio |
|
| Read Audio |
|
| Reads Audio from a file The following package is required: audio |
|
| Reverse Audio |
|
| Reverses audio The following package is required: audio |
|
| Save Audio |
|
| Saves Audio to a file The following package is required: audio |
|
| Slice Audio |
|
| Trims audio file and saves it The following package is required: audio |
|
| Variable Speed Audio |
|
| Plays audio faster or slower The following package is required: audio |
|
| Volume Audio |
|
| Returns min, max, and average volume of audio The following package is required: audio |
The Color Correction tools are all under the Color category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Brightness |
|
| Change the Brightness thorugh a Look Up Table (L.U.T.) for a Colored Image | |
| CLAHE Histogram Equalization |
|
| CLAHE, or Contrast Limited Adaptive Histogram Equalization, is an image processing technique used to enhance the local contrast of images, best used when the overall image contrast is low or uneven. | |
| Contrast |
|
| Change the Contrast thorugh a Look Up Table (L.U.T.) for a Colored Image | |
| Color Curve |
|
| Create a Curve Mask Thorugh a Look Up Table (L.U.T.) for a Colored Image | |
| Convert Colorspace |
|
| Convert Colorspace | |
| BGR->YUV |
|
| BGR to YUV of Cuda Buffer | |
| Brightness |
|
| Change Brightness of Cuda Buffer | |
| Contrast |
|
| Change Contrast of Cuda Buffer | |
| Crop |
|
| Crop input image | |
| Gamma |
|
| Change Gamma of Cuda Buffer | |
| Gamma Fwd |
|
| Gamma Fwd of Cuda Buffer | |
| Gamma Inv |
|
| Gamma Inv Cuda Buffer | |
| HLS->RGB |
|
| HLS to RGB of Cuda Buffer | |
| HSL Correct |
|
| Modify Color of Cuda Buffer Using HSL Sliders | |
| HSV->RGB |
|
| HSV to RGB of Cuda Buffer | |
| HSV Correct |
|
| Modify Color of Cuda Buffer Using HSV/HSB Sliders | |
| Invert |
|
| Inverts RGB channels of Cuda Buffer | |
| Levels |
|
| Smoothstep leveling of Cuda Buffer Using Gamma Function | |
| Lift |
|
| Change Lift of Cuda Buffer | |
| RGB->HLS |
|
| RGB to HLS of Cuda Buffer | |
| RGB->HSV |
|
| RGB to HSV of Cuda Buffer | |
| RGB->YUV |
|
| RGB to YUV of Cuda Buffer | |
| Smoothstep |
|
| Smoothstep of Cuda Buffer | |
| YUV->BGR |
|
| YUV to BGR of Cuda Buffer | |
| YUV->RGB |
|
| YUV to RGB of Cuda Buffer | |
| Debayer |
|
| Debayer | |
| Histogram Equalization |
|
| Histogram Equalization | |
| Gamma |
|
| Change the Gamma thorugh a Look Up Table (L.U.T.) for a Colored Image | |
| HSL->HSV |
|
| Convert Colorspace | |
| HSL->RGB |
|
| Convert Colorspace | |
| HSV->RGB |
|
| Convert Colorspace | |
| Image2D to Matrix2D |
|
| Convert Image2D to Matrix2D | |
| Invert Color |
|
| Invert Color Using Bitwise Not | |
| Levels |
|
| In/Out Black and White and Gamma Levels | |
| Color Lift |
|
| Lifts the Brightness thorugh a Look Up Table (L.U.T.) for a Colored Image | |
| Matrix2D to Image2D |
|
| Convert Matrix2D to Image2D | |
| RGB->HSL |
|
| Convert Colorspace | |
| RGB->HSV |
|
| Convert Colorspace | |
| RGB->YUV |
|
| Convert Colorspace | |
| Smoothstep |
|
| Smoothstep to set in and out black levels | |
| YUV->HSV |
|
| Convert Colorspace | |
| YUV->RGB |
|
| Convert Colorspace |
The Combine and Split Images tools are all under the Composite category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Absolute Difference |
|
| Absolute Difference Operations on Two Images | |
| Add |
|
| Add Operations on Two Images | |
| Bitwise And |
|
| Bitwise And Operations on Two Images | |
| Binary |
|
| Binary Operations on Two Images | |
| Add |
|
| Composite with Add blend mode | |
| Average |
|
| Composite with Average blend mode | |
| Blend |
|
| Change Blend of Cuda Buffer | |
| Color Burn |
|
| Composite with Color Burn blend mode | |
| Color Dodge |
|
| Composite with Color Dodge blend mode | |
| Darken |
|
| Composite with Darken blend mode | |
| Difference |
|
| Composite with Difference blend mode | |
| Exclusion |
|
| Composite with Exclusion blend mode | |
| Glow |
|
| Composite with Glow blend mode | |
| Hard Light |
|
| Composite with Hard Light blend mode | |
| Hard Mix |
|
| Composite with Hard Mix blend mode | |
| Lighten |
|
| Composite with Lighten blend mode | |
| Linear Burn |
|
| Composite with Linear Burn blend mode | |
| Linear Dodge |
|
| Composite with Linear Dodge blend mode | |
| Linear Light |
|
| Composite with Linear Light blend mode | |
| Multiply |
|
| Composite with Multiply blend mode | |
| Negation |
|
| Composite with Negation blend mode | |
| Normal |
|
| Composite with Normal blend mode | |
| Overlay |
|
| Composite with Overlay blend mode | |
| Phoenix |
|
| Composite with Phoenix blend mode | |
| Pin Light |
|
| Composite with Pin Light blend mode | |
| Reflect |
|
| Composite with Reflect blend mode | |
| Screen |
|
| Composite with Screen blend mode | |
| Soft Light |
|
| Composite with Soft Light blend mode | |
| Subtract |
|
| Composite with Subtract blend mode | |
| Vivid Light |
|
| Composite with Vivid Light blend mode | |
| Divide |
|
| Divide Operations on Two Images | |
| Draw Circles |
|
| Draws Circles | |
| Draw Contours |
|
| Draws contours outlines or filled contours | |
| Draw Lines |
|
| Draws Lines | |
| Draw Paths |
|
| Draws Paths | |
| Draw Rectangles |
|
| Draws Rectangles | |
| Draw Shapes |
|
| Draws Lines, Circles, and/or Rectangles | |
| Draw Text |
|
| Draws Text String | |
| Extract Channel |
|
| Extract One Channel | |
| Horizontal Combine |
|
| Horizontally Combine Two Images | |
| Maximum |
|
| Maximum Operations on Two Images | |
| Merge |
|
| Merges inputs into one channel. | |
| Minimum |
|
| Minimum Operations on Two Images | |
| Multiply |
|
| Multiply Operations on Two Images | |
| Bitwise Not |
|
| Inverts every bit of an array | |
| Bitwise Or |
|
| Bitwise Or And Operations on Two Images | |
| Split |
|
| Splits image into individual channels. | |
| Per Element Sqrt |
|
| Calculates a square root of array elements | |
| Subtract |
|
| Subtract Operations on Two Images | |
| Switch Image2D |
|
| Outputs one of the selected inputs | |
| Vertical Combine |
|
| Vertically Combine Two Images | |
| Bitwise XOR |
|
| Bitwise XOR Operations on Two Images |
The Database filters tools are all under the Database category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Store Row to Database |
|
| Store Row to Database The following package is required: database |
|
| Connect Generic Database |
|
| Connect to a database The following package is required: database |
|
| Connect MySQL |
|
| Connect to a MySQL database The following package is required: database |
|
| Connect Oracle |
|
| Connect to a Oracle database The following package is required: database |
|
| Connect PostgreSQL |
|
| Connect to a PostgreSQL database The following package is required: database |
|
| Connect SQLite |
|
| Connect to a SQLite database The following package is required: database |
|
| Connect Teradata |
|
| Connect to a Teradara database The following package is required: database |
|
| Get Table Names |
|
| Get names of all tables in Database The following package is required: database |
|
| Query Database |
|
| Query Database table The following package is required: database |
|
| Read Database Chunk |
|
| Read tables from Database in chunks The following package is required: database |
|
| Read Database Table |
|
| Read Database table The following package is required: database |
|
| Store Table to Database |
|
| Store Table to Database The following package is required: database |
The Datascience filters tools are all under the Datascience category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Bool Cell |
|
| Get bool cell value. | |
| Columns |
|
| Returns a subset of columns | |
| Columns Table |
|
| Returns the columns of the table | |
| Count Table |
|
| Returns the count of the table | |
| Group By Count Table |
|
| Returns the table with grouped count | |
| Double Cell |
|
| Get double cell value. | |
| Drop Columns Table |
|
| Returns the table with some columns dropped | |
| Drop Nan Columns |
|
| Drop any columns with Not a Number | |
| Drop Nan Rows |
|
| Drop any rows with Not a Number | |
| Drop Rows Table |
|
| Returns the table with some rows dropped | |
| Fill Nan Columns |
|
| Fill any columns with Not a Number | |
| Fill Nan Rows |
|
| Fills any rows with Not a Number | |
| Index Location Table |
|
| Integer-location based indexing for selection by position. | |
| Int Cell |
|
| Get int cell value. | |
| Join Table |
|
| Join Two Tables | |
| Export Matrix2D |
| Exports CSV file from Matrix2D | ||
| Max Table |
|
| Returns the max of the table | |
| Group By Max Table |
|
| Returns the table with grouped max | |
| Mean Table |
|
| Returns the mean of the table | |
| Group By Mean Table |
|
| Returns the table with grouped mean | |
| Merge Table |
|
| Merges Two Tables | |
| Min Table |
|
| Returns the min of the table | |
| Group By Min Table |
|
| Returns the table with grouped min | |
| Numpy To Table |
|
| Converts numpy to dataframe | |
| One Hot Encoding |
|
| Reflect the DataFrame over its main diagonal by writing rows as columns and vice-versa | |
| Random Table |
|
| Return random table | |
| Read CSV |
|
| Read CSV file into Panda Table | |
| Read Excel |
|
| Read Excel into Panda Table | |
| Sample Table |
|
| Returns the sampled table | |
| Set Table |
|
| Set values in table | |
| Table Shape |
|
| Returns the number of rows and columns | |
| Sort Columns |
|
| Sort Columns | |
| Sort Rows |
|
| Sort Rows | |
| STD Table |
|
| Returns the standard deviation of the table | |
| Group By STD Table |
|
| Returns the table with grouped standard deviations | |
| String Cell |
|
| Get string cell value. | |
| Sum Table |
|
| Returns the sum of the table | |
| Group By Sum Table |
|
| Returns the table with grouped sums | |
| Export CSV |
| Exports CSV file from Panda Table | ||
| Transpose Table |
|
| Reflect the DataFrame over its main diagonal by writing rows as columns and vice-versa | |
| Value Counts Table |
|
| Returns the number of unique rows of the table | |
| Where Table |
|
| Returns the table after a query is performed |
The Experimental Tools tools are all under the Experimental category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Abs Subtraction Shaders |
|
| Find Absolute Value of Difference Between 2 Images using a GPU Shader | |
| Add Shaders |
|
| Add 2 Images Together using a GPU Shader | |
| Beams Shader |
|
| Applies Beam Rendering | |
| Brightness Shader |
|
| Change the Brightness using a GPU Shader | |
| Clouds Shader |
|
| Applies Cloud Rendering | |
| Contrast Shader |
|
| Change the Contrast using a GPU Shader | |
| Dissolve Shaders |
|
| Dissolve 2 Images Together using a GPU Shader | |
| Texture Download |
|
| Downloads to CPU System Memory from GPU Texture Memory | |
| Flip Shader |
|
| Flips horizontal/vertical | |
| Gamma Shader |
|
| Change the Gamma using a GPU Shader | |
| Geo Api |
|
| Geo Api The following package is required: geopy |
|
| Grayscale Shader |
|
| Change a Color Texture to Grayscale using a GPU Shader | |
| Horizontal Ramp |
|
| Change Color Texture with Vertical Ramp using a GPU Shader | |
| Invert Shader |
|
| Inverts RGB channels of OpenGL Texture | |
| Lift Shader |
|
| Change the Lift using a GPU Shader | |
| Max Shaders |
|
| Find Max of 2 Images Together using a GPU Shader | |
| Min Shaders |
|
| Find Min of 2 Images Together using a GPU Shader | |
| Multiply Shaders |
|
| Multiply 2 Images Together using a GPU Shader | |
| Primatte AI |
|
| Primatte AI | |
| Reverse Geo Api |
|
| Reverse Geo Api The following package is required: geopy |
|
| Sobel Shader |
|
| Applies Soberl Edge Filter | |
| Stock Price |
|
| Stock Price using Yahoo Finance The following package is required: yfinance |
|
| Subtract Shaders |
|
| Subtract 2 Images Together using a GPU Shader | |
| Texture Output |
| Outputs Native Viewer | ||
| Transform Shader |
|
| Transform 2D Shader using a GPU Shader | |
| Texture Upload |
|
| Uploads CPU System Memory to GPU Texture Memory | |
| Vertical Ramp |
|
| Change Color Texture with Vertical Ramp using a GPU Shader |
The Image Processing Filters tools are all under the Image Processing category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Bilateral Filter |
|
| Applies bilateral filter to image | |
| Blur |
|
| Blurs an image using the normalized box filter | |
| Box Filter |
|
| Blurs an image using the box filter | |
| Build Pyramid |
|
| Constructs the Gaussian pyramid for an image. 4 images outputted. | |
| Cam Shift |
|
| Finds the rotated rectangle with the maximum number of points. When the object moves, the movement is reflected in the meanshift algorithm | |
| Canny Edge Detector |
|
| Canny Edge Detection is a popular edge detection algorithm | |
| Convert Depth |
|
| Convert Depth Precision between 8u, 8s, 16u, 16s, and 32f | |
| Bandpass filter |
|
| Band Pass filter to blur and sharpen | |
| Detect Circles |
|
| Detects circles in a grayscale image using the Hough transform. | |
| Detect Lines |
|
| Detects lines in a grayscale image using the Hough transform. | |
| Dilate |
|
| Blur and dilate image with vertical and horizontal blur | |
| Dilate 3x3 |
|
| Blur image based on maximum luminance value of surrounding pixels | |
| Erode |
|
| Blur and erode image with vertical and horizontal blur | |
| Erode 3x3 |
|
| Blur image based on minimum luminance value of surrounding pixels. 3x3 pixels are blurred at a time. | |
| Gauss |
|
| Gauss Filter on Cuda Buffer | |
| High Pass |
|
| High Pass Filter on Cuda Buffer | |
| Iterative Blur |
|
| Blur image using iterative 3x3 blurs | |
| Laplace |
|
| Laplace Filter on Cuda Buffer | |
| Low Pass |
|
| Low Pass Filter on Cuda Buffer | |
| Median Blur |
|
| Blur image using median 3x3 blurs | |
| Morph Gradient Border |
|
| Morphological dilated pixel result minus morphological eroded pixel result with border control. | |
| Prewitt |
|
| Combination of Prewitt Horiz and Prewitt Vert on Cuda Buffer | |
| Roberts |
|
| Combination of Roberts Filter Down and Roberts Filter Up on Cuda Buffer | |
| Separable Blur |
|
| Blur image with vertical and horizontal blur | |
| Sharpen |
|
| Filters the Cuda Buffer using a sharpening filter kernel | |
| Sobel |
|
| Combination of Sobel Horiz and Sobel Vert on Cuda Buffer | |
| Delay |
|
| Shows a Delayed Image | |
| Dilate |
|
| Dilates an image (expands the primary object) by using a specific structuring element that determines the shape of a pixel neighborhood over which the maximum is taken | |
| Erode |
|
| Erodes an image (shrinks the primary object) by using a specific structuring element that determines the shape of a pixel neighborhood over which the minimum is taken | |
| Filter 2D |
|
| Convolves an image with the kernel, applying an arbitrary linear filter to an image | |
| Find Contours |
|
| Finds contours in a binary image | |
| Frequency Bandpass |
|
| Applies a bandpass filter to a 1D or 2D floating-point array | |
| Detect Circles |
|
| Detects circles in a grayscale image using the Hough transform. | |
| Detect Lines |
|
| Detects lines in a grayscale image using the Hough transform. | |
| Laplacian Edge Detector |
|
| Laplacian Edge Detect | |
| Mean Shift |
|
| Finds the rectangle with the maximum number of points. When the object moves, the movement is reflected in the meanshift algorithm | |
| Mean Color |
|
| Calculates an average (mean) value of array elements, independently for each channel | |
| Mean Mask |
|
| Calculates an average (mean) value of array elements for a grayscale image | |
| Median Blur |
|
| Blurs an image using the median filter | |
| Morphological Skeleton |
|
| Create compact representation of image using skeleton. | |
| Morphological Ex |
|
| Performs advanced morphological transformations using an erosion and dilation as basic operations. | |
| Morph Hit or Miss |
|
| Applies kernel onto binary input image to produce 1 channel output image of all pixels that match the kernel's pattern. | |
| Pyr Down |
|
| Blurs an image and downsamples it | |
| Pyr Up |
|
| Upsamples an image and then blurs it | |
| Radon Transform |
|
| Canny Edge Detection is calculates the projection of an image's intensity along lines at specific angles. | |
| Scharr Edge Detector |
|
| Scharr Edge Detect | |
| Sep Filter 2D Gabor |
|
| Applies a separable linear filter to an image | |
| Sep Filter 2D Gaussian |
|
| Applies a separable linear filter to an image | |
| Sobel |
|
| Detects edges by calculating the first, second, third, or mixed image derivatives using an extended Sobel operator | |
| Spatial Gradient |
|
| Calculates the first order image derivative in both x and y using a Sobel operator, which emphasizes regions of high spatial frequency that correspond to edges. | |
| Sqr Box Filter |
|
| Blurs an image using the box filter by calculating the normalized sum of squares of the pixel values overlapping the filter | |
| Stack Blur |
|
| Blurs an image by creating a kind of moving stack of colors whilst scanning through the image | |
| Get Structuring Element |
|
| Returns a structuring element of the specified size and shape for morphological operations. | |
| Sum Color |
|
| Calculates and returns the sum of array elements, independently for each channel | |
| Sum Mask |
|
| Calculates and returns the sum of array elements for a grayscale image | |
| Create Super Pixel |
|
| Initializes a SuperpixelLSC (Linear Spectral Clustering) object for the input image. |
The Grayscale Filters tools are all under the Grayscale category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Adaptive Threshold |
|
| The function is typically used to get a bi-level (binary) image out of a grayscale image | |
| Adaptive Binary Threshold |
|
| The function is typically used to get a bi-level (binary) image out of a grayscale image | |
| Adaptive Binary Inverse Threshold |
|
| The function is typically used to get a bi-level (binary inverse) image out of a grayscale image | |
| Chroma Keyer |
|
| Chroma Key of Cuda Buffer | |
| CIELAB Threshold |
|
| CIELAB Threshold of Cuda Buffer | |
| Grayscale |
|
| Grayscale of Cuda Buffer | |
| Hue Threshold |
|
| Hue Threshold of Cuda Buffer | |
| RGB Threshold |
|
| RGB Threshold of Cuda Buffer | |
| Grayscale |
|
| Convert to grayscale | |
| Color In Range |
|
| Threshold if between min and max | |
| Mask Brightness |
|
| Change the Brightness thorugh a Look Up Table (L.U.T.) for a Mask | |
| Mask Circles |
|
| Draws Circles with Masks | |
| Mask Contrast |
|
| Change the Contrast thorugh a Look Up Table (L.U.T.) for a Mask | |
| Mask Curve |
|
| Create a Curve Mask Thorugh a Look Up Table (L.U.T.) | |
| Mask Gamma |
|
| Change the Gamma thorugh a Look Up Table (L.U.T.) for a Mask | |
| Invert Mask |
|
| Inverts the Mask using Bitwise Not | |
| Mask Lift |
|
| Lifts the Brightness thorugh a Look Up Table (L.U.T.) for a Mask | |
| Mask Paths |
|
| Draws Paths with Masks | |
| Mask Rectangles |
|
| Draws Rectangles with Masks | |
| Mask Shapes |
|
| Draws Lines, Circles, and/or Rectangles with Masks | |
| Threshold |
|
| The function is typically used to get a bi-level (binary) image out of a grayscale image | |
| Threshold Binary |
|
| The function is typically used to get a bi-level (binary) image out of a grayscale image | |
| Threshold Binary Inverse |
|
| The function is typically used to get a bi-level (binary inverse) image out of a grayscale image | |
| Mask In Range |
|
| Mask Threshold if between min and max | |
| Threshold Mask |
|
| The function is typically used to get a bi-level (mask) image out of a grayscale image | |
| Threshold Otsu |
|
| The function is typically used to get a bi-level (binary inverse) image out of a grayscale image | |
| Threshold To Zero |
|
| The function is typically used to get a bi-level (to zero) image out of a grayscale image | |
| Threshold To Zero Inverse |
|
| The function is typically used to get a bi-level (to zero inverse) image out of a grayscale image | |
| Threshold Triangle |
|
| The function is typically used to get a bi-level (triangle) image out of a grayscale image | |
| Threshold Trunc |
|
| The function is typically used to get a bi-level (binary inverse) image out of a grayscale image |
The Source Inputs tools are all under the Inputs category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Folder Reader |
|
| Reads filepaths from a folder | |
| Grayscale Image Reader |
|
| Reads Grayscale Images from a file | |
| Image Reader |
|
| Reads Images from a file | |
| JSON File Reader |
|
| Reads from a JSON file | |
| Movie Reader |
|
| Reads Images from a movie | |
| Solid Color Image |
|
| Output a RGB, RGBA, or Alpha-only image. | |
| Solid Color Image |
|
| Output a RGB, RGBA, or Alpha-only image. | |
| Take Picture |
|
| Takes a picture | |
| Text |
|
| Outputs text as an image | |
| Text File Reader |
|
| Reads from a text file | |
| Webcam |
|
| Reads Images from a webcamera | |
| YouTube Reader |
|
| Streams data from a YouTube video The following package is required: youtube_reader |
The Logic functions tools are all under the Logic category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| And |
|
| Logical AND operator | |
| Conditional Color Operator |
|
| Outputs one of the selected inputs | |
| Conditional Double2 Operator |
|
| Outputs one of the selected inputs | |
| Conditional Double3 Operator |
|
| Outputs one of the selected inputs | |
| Conditional Image2D Operator |
|
| Outputs one of the selected inputs | |
| Conditional Int2 Operator |
|
| Outputs one of the selected inputs | |
| Conditional Int3 Operator |
|
| Outputs one of the selected inputs | |
| Conditional Matrix Operator |
|
| Outputs one of the selected inputs | |
| Conditional Numeric Operator |
|
| Outputs one of the selected inputs | |
| Conditional String Operator |
|
| Outputs one of the selected inputs | |
| False |
| Returns False | ||
| Numeric a == b |
|
| Return if inputs are equal | |
| Numeric a > b |
|
| Return if input a > input b | |
| Numeric a >= b |
|
| Return if input a >= input b | |
| Numeric a < b |
|
| Return if input a < input b | |
| Numeric a <= b |
|
| Return if input a <= input b | |
| Numeric Compare a != b |
|
| Return if inputs are not equal | |
| Or |
|
| Logical OR operator | |
| Range |
|
| Return if number is in range | |
| True |
| Returns True |
The Math functions tools are all under the Math category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Abs |
|
| Return absolute value | |
| Arccos |
|
| Return inverse cosine of input x, result is in degrees | |
| Arccosh |
|
| Return inverse hyperbolic cosine of input x | |
| Arcsin |
|
| Return inverse sine of input x, result is in degrees | |
| Arcsinh |
|
| Return inverse hyperbolic sine of input x | |
| Atan2 |
|
| Return inverse hyperbolic tangent of input x | |
| Arctanh |
|
| Return archtan(a) | |
| Ceil |
|
| Return ceil(x) | |
| Cos |
|
| Return cosine of input x (where x is in degrees) | |
| Cosh |
|
| Return hyperbolic cosine of input x | |
| Counter Double |
|
| Counts numbers | |
| Counter Int |
|
| Counts numbers | |
| Divide |
|
| Return a/b | |
| e |
| Returns eulers number | ||
| Exponential |
|
| Return e^x | |
| Floor |
|
| Return floor(x) | |
| Log |
|
| Return log(x,base) | |
| Minus |
|
| Return a-b | |
| Mod |
|
| Return mod(a,b) | |
| Multiply |
|
| Return a*b | |
| One |
| Return number one | ||
| PI |
| Return PI | ||
| Plus |
|
| Return a+b | |
| Power |
|
| Return a^b | |
| Random Number |
|
| Return random number | |
| Sin |
|
| Return sine of input x (where x is in degrees) | |
| Sinh |
|
| Return hyperbolic sine of input x | |
| Sqrt |
|
| Return square root of x | |
| Square |
|
| Return x^2 | |
| Tan |
|
| Return tangent of input x (where x is in degrees) | |
| Tanh |
|
| Return hyperbolic tangent of input x | |
| Zero |
| Return number zero |
The Matrix operations tools are all under the Matrix category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Abs |
|
| Calculate the absolute value element-wise | |
| Add |
|
| Add arguments element-wise | |
| All |
|
| Test whether all array elements evaluate to True | |
| All Close |
|
| Returns if all elements x1 and x2 are within 1e-5 of one another (not suited for very small-valued matrices) | |
| Any |
|
| Test whether any array element evaluates to True | |
| Arange |
|
| Return values spaced by step within a given interval [start, stop] | |
| Per Element Comparison |
|
| Performs the per-element comparison of two arrays or an array and scalar value. When the comparison result is true, the corresponding element of output array is set to 255 | |
| Matrix Concatenate |
|
| Concatentate matrices | |
| Cross Product |
|
| Returns the cross product of 3-element vectors | |
| Determinant |
|
| Compute the determinant of an array | |
| Divide |
|
| Divide arguments element-wise | |
| Dot Product |
|
| Dot product of two vectors | |
| Eigen |
|
| Calculates eigenvalues and eigenvectors of a matrix | |
| Equal |
|
| Return (x1 == x2) element-wise | |
| Identity |
|
| Return a 2-D array with ones on the diagonal and zeros elsewhere. In other words, an identity matrix of size n | |
| HStack |
|
| Stack arrays in sequence horizontally (column wise). All input arrays have the same shape except for the 2nd axis | |
| Index |
|
| Accesses an array at a given matrix index | |
| Integral |
|
| Calculates the integral of an image | |
| Inverse Matrix |
|
| Finds the inverse or pseudo-inverse of a matrix | |
| Linspace |
|
| Returns num evenly spaced samples, calculated over the interval [start, stop] | |
| Least Squares |
|
| Return the least-squares solution to a linear matrix equation. Computes the vector x that approximately solves ax = b | |
| Matrix Multiply |
|
| Calculates the matrix multiplication of two arrays | |
| Max |
|
| Return the maximum of an array | |
| Mean |
|
| Compute the arithmetic mean | |
| Min |
|
| Return the minimum of an array | |
| Per Element Multiply |
|
| Calculates the per-element scaled product of two arrays | |
| Norm |
|
| Calculates the absolute norm of an array | |
| Eigen |
|
| Compute the eigenvalues and right eigenvectors of a square array | |
| Inverse Matrix |
|
| Compute the inverse of a square matrix | |
| Matrix Multiply |
|
| Matrix dot product of two arrays | |
| Per Element Multiply |
|
| Multiply arguments element-wise | |
| Norm |
|
| Matrix or vector norm. Frobenius norm for matrices, L2 norm for vectors. | |
| Scalar Multiply |
|
| Multiply matrix with scalar value | |
| Trace |
|
| Return the sum along diagonals of the array | |
| Transpose |
|
| Returns an array with axes transposed | |
| Matrix Ones |
|
| Return an array of filled with ones given shape and type | |
| Outer Product |
|
| Compute the outer product of two vectors | |
| Power |
|
| Raise a square matrix to the power n | |
| Pseudo Inverse Matrix |
|
| Compute the (Moore-Penrose) pseudo-inverse of a matrix | |
| QR Factorization |
|
| Compute the qr factorization of a matrix. Factor the matrix a as qr, where q is orthonormal and r is upper-triangular. | |
| Matrix Random |
|
| Random matrices | |
| Matrix Random Normal Distribution |
|
| Random matrices with values chosen from the “standard normal” distribution | |
| Rank |
|
| Return matrix rank of array using SVD method | |
| Relative Norm |
|
| Calculates an absolute difference norm or a relative difference norm of two arrays | |
| Reshape |
|
| Gives a new shape to an array without changing its data | |
| Select |
|
| Sets the output matrix to the value from the first input matrix if corresponding value of mask matrix is 255, or value from the second input matrix (if value of mask matrix set to 0) | |
| Shape |
|
| Return the shape of an array | |
| Matrix Size |
|
| Gives the matrix number of elements | |
| Solve |
|
| Solve a linear matrix equation, or system of linear scalar equations. Computes the exact solution x of ax = b | |
| Split |
|
| Split an array into multiple sub-arrays based on indices. For example, indices 2 and 3 returns array[:2], array[2:3], and array[3:] | |
| Sqrt |
|
| Return the non-negative square-root of an array, element-wise | |
| Standard Deviation |
|
| Returns the standard deviation of the elements | |
| Subtract |
|
| Subtract arguments element-wise | |
| Sum |
|
| Sum of array elements | |
| SVD |
|
| Singular Value Decomposition | |
| Trace |
|
| Returns the trace of a matrix, the sum of its diagonal elements | |
| Transpose |
|
| Transposes a matrix | |
| VStack |
|
| Stack arrays in sequence vertically (row wise). All input arrays have the same shape except for the 1st axis | |
| Where Matrix Filter |
|
| Return elements chosen from x or y depending on condition. If condition is True, return element from x, otherwise return y | |
| Matrix Zeros |
|
| Return an array of filled with zeros given shape and type |
The Machine Learning filters based using scikit-learn tools are all under the ML category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Bernoulli NB Classifier |
|
| Bernoulli Naive Bayes Classifier model | |
| Categorical NB Classifier |
|
| Categorical Naive Bayes Classifier model | |
| Complement NB Classifier |
|
| Complement Naive Bayes Classifier model | |
| Gaussian NB Classifier |
|
| Gaussian Naive Bayes Classifier model | |
| Gaussian Process Classifier |
|
| Gaussian Process Classifier model | |
| Gaussian Process Regressor |
|
| Gaussian Process Regressor model | |
| KNeighbors Classifier |
|
| KNeighbors Classifier model | |
| KNeighbors Regressor |
|
| KNeighbors Regressor model | |
| Lasso Regressor |
|
| Lasso model | |
| Linear Regression |
|
| Linear regression model | |
| Linear SVC Model |
|
| Linear Support Vector Classifier model | |
| Logistic Regression |
|
| Logistic regression model | |
| MSE |
|
| Calculates Mean Square Error | |
| MLP Neural Network |
|
| Neural Network MLP Classifier model | |
| Load ML Model |
|
| Load a ML model from a designated file | |
| Model Predict |
|
| Predicts test data using model | |
| Save ML Model |
| Save a ML model to a designated file | ||
| Multinomial NB Classifier |
|
| The multinomial Naive Bayes classifier is suitable for classification with discrete features (e.g., word counts for text classification). | |
| Nearest Centroid |
|
| Nearest Centroid Classifier model | |
| Optical Character Recognition |
|
| Reads text in an image using EasyOCR The following package is required: ocr |
|
| R2 Score |
|
| Calculates R2 Score | |
| Random Forest Model |
|
| Random Forest Classifier model | |
| Ridge Classifier |
|
| Ridge Classifier model | |
| Ridge Regressor |
|
| Ridge Regressor model | |
| SGD Classifier |
|
| Stochastic Gradient Descent Classifier model | |
| SGD Regressor |
|
| Stochastic Gradient Descent Regressor model | |
| SVC Model |
|
| Support Vector Classifier model | |
| Tensorboard Visualization |
|
| Visualizes machine learning training processes using Tensorboard | |
| Train Test Split |
|
| Returns train test split. |
The Display tools that allow you to visualize directly in the flowgraph tools are all under the Outputs category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Bool Display |
| Show Bool | ||
| Color Display |
| Show Color | ||
| DataFrame Display |
| DataFrame Viewer | ||
| Double2 Display |
| Show Double2 | ||
| Double3 Display |
| Show Double3 | ||
| Double Display |
| Show Double Number | ||
| Full Image Display |
| Show Full image | ||
| Fullscreen |
| Show Image | ||
| Full Image Display |
| Show Full Image | ||
| imshow Display |
| imshow Image Viewer - only displays on the server | ||
| Int2 Display |
| Show Int2 | ||
| Int3 Display |
| Show Int3 | ||
| Int Display |
| Show Int | ||
| Matrix2D Display |
| Show Matrix2D | ||
| String Display |
| Show String | ||
| Tensor Display |
| Tensor Viewer | ||
| Thumbnail Image Display |
| Show Thumbnail of Image | ||
| Thumbnail Image Display |
| Show Thumbnail of Image |
The Photron Filters tools are all under the Photron category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Depth Reader |
|
| Reads Depth Images from a file | |
| Infinicam |
|
| View live Images from a Photron Infinicam | |
| Infinicam Save Movie |
|
| Saves Infinicam Video to Movie format | |
| Infinicam Save Compressed |
|
| Saves Infinicam to mdat Compressed Video format | |
| Photron Camera |
|
| Photron Highspeed camera | |
| Infinicam Movie Reader |
|
| Reads Images from a Photron movie (cih/mdat or cih/mraw) |
The Plot figures tools are all under the Plot category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Area Plot |
|
| Pandas area plot | |
| Bar Plot |
|
| Pandas bar plot | |
| Bar Horizontal Plot |
|
| Pandas line plot | |
| Box Plot |
|
| Pandas box plot | |
| Confusion Matrix Plot |
|
| Plot truth vs prediced | |
| Density Plot |
|
| Pandas density plot | |
| Hexbin Plot |
|
| Pandas hexbin plot | |
| Histogram Plot |
|
| Pandas histogram plot | |
| Line Plot |
|
| Pandas line plot | |
| Metric Plot |
|
| Plot truth vs prediced | |
| Pie Plot |
|
| Pandas scatter pechart | |
| Scatter Plot |
|
| Pandas scatter plot |
The Pytorch functions tools are all under the Pytorch category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Add |
|
| Add Other tensor to Input tensor | |
| Arange |
|
| Returns a 1-D tensor of size ceil((end - start) / step) with values from the interval [start, end) taken with common difference step beginning from start. | |
| BCE Loss |
|
| Creates a criterion that measures the Binary Cross Entropy between the target and the input probabilities. | |
| CIFAR10 Dataset |
|
| Loads the CIFAR10 dataset | |
| Cityscapes Dataset |
|
| Loads the Cityscapes dataset | |
| Concatenate |
|
| Concatenates the given sequence of tensors in tensors in the given dimension. All tensors must either have the same shape (except in the concatenating dimension) or be a 1-D empty tensor with size (0,). | |
| Cross Entropy Loss |
|
| This criterion computes the cross entropy loss between input logits and target. | |
| DataFrame to Tensor |
|
| Converts a Pandas DataFrame to a Pytorch tensor. | |
| Dimensions |
|
| Returns the number of dimensions of tensor. | |
| Divide |
|
| Divides each element of the input input by the corresponding element of other. | |
| Export Torchvision to ONNX |
| Export PRE-MADE Torchvision model to ONNX. | ||
| Export to ONNX |
| Export CUSTOM-MADE PyTorch model to ONNX. | ||
| FashionMNIST Dataset |
|
| Loads the FashionMNIST dataset | |
| Finetune Trained Model |
|
| Finetune or feature train a pre-existing torchvision model. | |
| Flatten Tensor |
|
| Flattens input by reshaping it into a one-dimensional tensor. If start_dim or end_dim are passed, only dimensions starting with start_dim and ending with end_dim are flattened. The order of elements in input is unchanged. | |
| Generic Dataset |
|
| Loads the Generic dataset | |
| HStack |
|
| Stack tensors in sequence horizontally (column wise). | |
| Image Classification |
|
| Perform image classification on pre-trained model. | |
| Image to Tensor |
|
| Converts a Image to a Pytorch tensor. | |
| L1 Loss |
|
| Creates a criterion that measures the mean absolute error (MAE) between each element in the input x and target y. | |
| Linspace |
|
| Creates a one-dimensional tensor of size steps whose values are evenly spaced from start to end, inclusive. | |
| Alexnet Model |
|
| Loads alexnet model from pytorch/vision repo | |
| Convnext Model |
|
| Loads convnext model from pytorch/vision repo | |
| DeeplabV3 Model |
|
| Loads DeeplabV3 model from pytorch/vision repo | |
| Densenet Model |
|
| Loads densenet model from pytorch/vision repo | |
| EfficientNet Model |
|
| Loads EfficientNet model from pytorch/vision repo | |
| FCN Model |
|
| Loads Fully Convolutional Network model from pytorch/vision repo | |
| Load Torchvision Model |
|
| Loads a model from the pytorch/vision GitHub repo | |
| Googlenet Model |
|
| Loads googlenet model from pytorch/vision repo | |
| InceptionV3 Model |
|
| Loads Inception v3 model from pytorch/vision repo | |
| MnasNet Model |
|
| Loads MnasNet model from pytorch/vision repo | |
| MobileNet Model |
|
| Loads MobileNet model from pytorch/vision repo | |
| Load Torch Model |
|
| Load a trained model from a designated file | |
| Regnet Model |
|
| Loads regnet model from pytorch/vision repo | |
| Resnet Model |
|
| Loads resnet model from pytorch/vision repo | |
| Shufflenet Model |
|
| Loads shufflenet model from pytorch/vision repo | |
| Swin Transformer Model |
|
| Loads Swin Transformer model from pytorch/vision repo | |
| Load Tensor |
|
| Load a tensor from a designated file | |
| VGG Model |
|
| Loads VGG model from pytorch/vision repo | |
| Vision Transformer Model |
|
| Loads Vision Transformer (ViT) model from pytorch/vision repo | |
| Max |
|
| Returns the maximum value of all elements in the input tensor. | |
| Mean |
|
| Returns the mean value of all elements in the input tensor. | |
| Min |
|
| Returns the minimum value of all elements in the input tensor. | |
| MNIST Dataset |
|
| Loads the MNIST dataset | |
| MSE Loss |
|
| Creates a criterion that measures the mean squared error (squared L2 norm) between each element in the input x and target y. | |
| Multiply |
|
| Multiply Input tensor by Other tensor | |
| NLL Loss |
|
| The negative log likelihood loss. It is useful to train a classification problem with C classes. | |
| Classifier Test |
|
| Evaluate the performance of a neural network classifier model. | |
| Classifier Train |
|
| Train a neural network classifier model. | |
| Convolution 2D |
|
| Applies a 2D convolution over an input signal composed of several input planes. | |
| Convolutional Neural Net |
|
| Creates a custom convolutoinal neural network (CNN). Follows the common NN structure of feature learning (comprised of multiple layers of convolution, activation, and pooling), then classification (comprised of several linear+ReLU layers). Each input image must be the same dimensions. WARNING: setting input parameters too high may cause CUDA to run out of memory on your GPU. | |
| Dropout |
|
| During training, randomly zeroes some of the elements of the input tensor with probability p. The zeroed elements are chosen independently for each forward call and are sampled from a Bernoulli distribution. | |
| Flatten Module |
|
| Flattens a contiguous range of dims into a tensor. Output is a torch.nn.Module. | |
| Linear |
|
| Applies an affine linear transformation to the incoming data: y = x*A^T + b. | |
| Log Softmax |
|
| Applies the log(Softmax(x)) function to an n-dimensional input Tensor. | |
| Max Pooling 2D |
|
| Applies a 2D max pooling over an input signal composed of several input planes. | |
| Regression Test |
|
| Evaluate the performance of a neural network regression model. | |
| Regression Train |
|
| Train a neural network regression model. | |
| ReLU |
|
| Applies the rectified linear unit function element-wise. | |
| Segmentation Test |
|
| Evaluate the performance of a neural network segmentation model. | |
| Segmentation Train |
|
| Train a neural network segmentation model. | |
| Sequential |
|
| A sequential container that is then passed into a basic neural network model. Modules will be added to it in the order they are passed into the constructor. | |
| Sequential Loader |
|
| A sequential container. Modules will be added to it in the order they are passed into the constructor. | |
| Sigmoid |
| Applies the Sigmoid function element-wise. | ||
| Softmax |
|
| Applies the Softmax(x) function to an n-dimensional input Tensor. | |
| Tanh |
| Applies the Hyperbolic Tangent (Tanh) function element-wise. | ||
| NRandom |
|
| Returns a tensor filled with random numbers from a normal distribution with mean 0 and variance 1 (also called the standard normal distribution). | |
| Numeric to Tensor |
|
| Converts a numeric (int or double) to a Pytorch tensor. | |
| Numpy to Tensor |
|
| Converts a Numpy array to a Pytorch tensor. | |
| Ones |
|
| Returns a tensor filled with the scalar value 1, with the shape defined by the variable argument size. | |
| Adam Optimizer |
|
| Implements Adam algorithm. | |
| Per Parameter Optimizer |
|
| Helper node for optimizer nodes. Allows specific values to be applied per-parameter. If a model's parameter is not specified, it will take on the values passed in the main Optimizer node, not in this helper node. | |
| RMSprop Optimizer |
|
| Implements RMSprop algorithm. | |
| SGD Optimizer |
|
| Implements stochastic gradient descent (optionally with momentum). | |
| Random |
|
| Returns a tensor filled with random numbers from a uniform distribution on the interval [0,1). | |
| Save Torch Model |
| Save a trained model to a designated file | ||
| Save Tensor |
| Save a tensor to a designated file | ||
| Set Default Type |
|
| Set the default float type of all torch tensors in the workflow. | |
| Set Tensor |
|
| Sets Matrix Tensor value | |
| Size |
|
| Returns the size of tensor as a tensor. | |
| Slice |
|
| Slice a Torch | |
| Subtract |
|
| Subtract Other tensor from Input tensor | |
| Sum |
|
| Returns the sum of all elements in the input tensor. | |
| Tensor to DataFrame |
|
| Converts a Pytorch tensor to a Pandas DataFrame. | |
| Tensor to Image |
|
| Converts a Pytorch tensor to an image. | |
| Tensor to Numpy |
|
| Converts a Pytorch tensor to a Numpy array. | |
| Transform Compose |
|
| Composes several transforms together. Transform objects will be added to it in the order they are passed into the constructor. | |
| Transform Compose Loader |
|
| A compose container. Modules will be added to it in the order they are passed into the constructor. | |
| Transform Normalize |
|
| Normalize a tensor image with mean and standard deviation. The mean and standard deviation will be applied to each channel of the image. This transform does not support PIL Image. | |
| Transform Resize |
|
| Resize the input image to the given size. If the image is torch Tensor, it is expected to have […, H, W] shape, where … means a maximum of two leading dimensions. | |
| Transform ToTensor |
| Convert a PIL Image or ndarray to tensor and scale the values accordingly. | ||
| Transpose |
|
| Returns a tensor that is a transposed version of input. The given dimensions dim0 and dim1 are swapped. | |
| VStack |
|
| Stack tensors in sequence vertically (row wise). | |
| Zeros |
|
| Returns a tensor filled with the scalar value 0, with the shape defined by the variable argument size. |
The 3D Rendering functions tools are all under the Rendering category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Create 3DNode |
|
| Create a Pyrender 3D Node The following package is required: pyrender |
|
| Create DirectionalLight |
|
| Create a Pyrender DirectionalLight. The following package is required: pyrender |
|
| Create Intrinsics Camera |
|
| Create a Pyrender Intrinsics Camera. The following package is required: pyrender |
|
| Create Orthographic Camera |
|
| Create a Pyrender Orthographic Camera. The following package is required: pyrender |
|
| Create Perspective Camera |
|
| Create a Pyrender Perspective Camera. The following package is required: pyrender |
|
| Create PointLight |
|
| Create a Pyrender PointLight. The following package is required: pyrender |
|
| Render Scene |
|
| Create a Pyrender Scene with multiple Node inputs. The following package is required: pyrender |
|
| Create SpotLight |
|
| Create a Pyrender SpotLight. The following package is required: pyrender |
|
| Load Mesh |
|
| Create a Mesh 3DNode by loading a Trimesh. The following package is required: pyrender |
|
| LookAt Matrix |
|
| Returns a 4x4 matrix for camera positioning. The following package is required: pyrender |
|
| Matrix to Double3 |
|
| Convert 3x1 Matrix into Double3. The following package is required: pyrender |
|
| Transformation Matrix |
|
| Returns a 4x4 matrix for transformation (translation, rotation, and scale). The following package is required: pyrender |
|
| Trimesh Box |
|
| Create a Trimesh box / cuboid. The following package is required: pyrender |
|
| Trimesh Capsule |
|
| Create a Trimesh capsule. The following package is required: pyrender |
|
| Trimesh Cone |
|
| Create a Trimesh cone along Z centered at the origin. The following package is required: pyrender |
|
| Trimesh Icosphere |
|
| Create a Trimesh isophere. The following package is required: pyrender |
|
| Trimesh Quad |
|
| Create a Gouraud shaded quad. The following package is required: pyrender |
|
| Trimesh Torus |
|
| Create a Trimesh torus around Z centered at the origin. The following package is required: pyrender |
|
| Trimesh Triangle |
|
| Create a Gouraud shaded triangle. The following package is required: pyrender |
The String functions tools are all under the String category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| String Length |
|
| Return string length | |
| String Replace |
|
| String replacement | |
| String Concatenate |
|
| Returns concatenated string | |
| String a == b |
|
| Return if inputs are equal | |
| String Format |
|
| String Format | |
| String a > b |
|
| Return if input a > input b | |
| String a >= b |
|
| Return if input a >= input b | |
| String In |
|
| Returns if string a is in string b | |
| String a < b |
|
| Return if input a < input b | |
| String a <= b |
|
| Return if input a <= input b | |
| String a != b |
|
| Return if inputs are not equal | |
| To String |
|
| Convert to string |
The Tracking functions tools are all under the Tracking category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| AKAZE Feature Detector |
|
| Determines strong corners on an image using the AKAZE detector | |
| Aruco Detector |
|
| Tracks Aruco marker | |
| Aruco Marker Data |
|
| Find specific Aruco Marker based on ID value in a scene. Return Aruco marker translational/rotational data if found. | |
| Barcode Detect |
|
| Detects barcodes The following package is required: barcode |
|
| Corner Harris |
|
| Runs the Harris corner detector on the image | |
| Corner Sub Pixel |
|
| Refines the corner locations | |
| Corner Tracker |
|
| Determines strong corners on an image using the goodFeaturesToTrack() function | |
| Dense Optical Flow |
|
| Computes the pattern of apparent motion of image objects for all points in the frame | |
| FLANN Feature Matcher |
|
| Finds the feature vector correspondent to the keypoints using the FLANN matcher | |
| Match Template |
|
| Matches a template within an image, producing a point of the template's location | |
| Nano Tracker Inference |
|
| Tracks a template within an image using NanoTracker ML algorithm. The Nano tracker is a super lightweight dnn-based general object tracker. The following package is required: dasiamrpn |
|
| Optical Flow |
|
| Computes the pattern of apparent motion for a sparse feature set using the iterative Lucas-Kanade method with pyramids | |
| QR Code Detect |
|
| Detect QR Code | |
| SIFT Detector |
|
| Determines strong corners on an image using the SIFT detector | |
| SURF Feature Detector |
|
| Determines strong corners on an image using the SURF detector | |
| Track Data Plot |
|
| Tracking line plot | |
| DaSiamRPN Tracker Inference |
|
| Tracks a template within an image using dasiamrpn ML algorithm The following package is required: dasiamrpn |
|
| Tracking Template |
|
| Tracks a template within an image, producing a point of the template's location | |
| Export Tracking Data |
| Exports CSV file from Tracking Data |
The Transform filters tools are all under the Transform category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Calibrate Camera |
|
| Returns a camera matrix and distortion coefficients to undistort camera images | |
| Crop |
|
| Crops an image down to the specified size | |
| Resize |
|
| Change Resize of Cuda Buffer | |
| Transform |
|
| Applies an affine transformation to an image | |
| DCT |
|
| Performs a forward discrete Cosine transform of 1D or 2D array | |
| DFT |
|
| Performs a forward Discrete Fourier transform of a 1D or 2D floating-point array | |
| Disparity Map |
|
| Shows the Disparity Map Found Using Stereo Images | |
| Get Affine Transform |
|
| Calculates an affine transform from the source image to the destination image | |
| Get Perspective Transform |
|
| Returns 3x3 perspective transformation for the corresponding 4 point pairs | |
| Get Rotation Matrix 2D |
|
| Calculates an affine matrix of 2D rotation | |
| IDCT |
|
| Performs an inverse discrete Cosine transform of 1D or 2D array | |
| IDFT |
|
| Performs an inverse Discrete Fourier transform of a 1D or 2D floating-point array | |
| Linear Polar |
|
| Remaps an image to polar coordinates space | |
| Log Polar |
|
| Remaps an image to semilog-polar coordinates space | |
| Panorama Stitcher |
|
| High level image stitcher | |
| Resize |
|
| Resizes an image down to or up to the specified size | |
| Scan Stitcher |
|
| High level image stitcher | |
| Transform |
|
| Applies an affine transformation to an image | |
| Undistort |
|
| Transforms an image to compensate for lens distortion | |
| Warp Affine |
|
| Applies an affine transformation to an image | |
| Warp Affine Inverse |
|
| Applies an inverse affine transformation to an image | |
| Warp Perspective |
|
| Applies a perspective transformation to an image | |
| Warp Perspective Inverse |
|
| Applies an inverse perspective transformation to an image | |
| Warp Polar |
|
| Remaps an image to polar or semilog-polar coordinates space | |
| Warp Polar Detailed |
|
| Remaps an image to polar or semilog-polar coordinates space | |
| Warp Polar Inverse |
|
| Remaps an from polar or semilog-polar coordinates space to cartesian coordinates |
The Tools that have been placed in Trash tools are all under the Trash category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|
The Triggers functions tools are all under the Triggers category. You can create triggers to activate certain nodes that require a trigger to execute - review the section Creating Triggers. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Blink1 Fade Color |
| Fades the Blink1 LED to the specified color over a given time (in ms). The following package is required: blink |
||
| Image Writer |
| Saves Image | ||
| Live Stream |
|
| Livestreams to your YouTube channel The following package is required: live_stream |
|
| Live Stream Chat |
|
| Gets chat from livestream The following package is required: livestream_chat |
|
| Loop Trigger |
|
| Implement a loop by triggering an earlier node | |
| Loop Variable |
|
| A loop variable | |
| Microphone |
|
| Listens and streams the microphone | |
| Philips Hue |
| Changes Color/Settings on Philips Hue Device The following package is required: philips_hue |
||
| ROS2 Action Client |
|
| Executes a ROS action The following package is required: ros |
|
| ROS2 Publisher |
|
| Publishes data to a ROS topic The following package is required: ros |
|
| ROS2 Server |
|
| Launches a ROS2 node The following package is required: ros |
|
| ROS2 Service Client |
|
| Calls a ROS service The following package is required: ros |
|
| ROS2 Subscriber |
|
| Subscribes to a ROS topic The following package is required: ros |
|
| RTC Keyboard |
|
| Receive keyboard inputs The following package is required: rtc |
|
| RTC Web |
|
| Talk to Infiniworkflow from your browser The following package is required: rtc |
|
| Save JSON File |
| Save JSON file | ||
| Save Text File |
| Save Text file | ||
| Screenshot |
| Saves Screenshot | ||
| Send Email |
|
| Sends an email from your Gmail email address The following package is required: send_email |
|
| Serial |
|
| Communicate with a device through serial The following package is required: serial |
|
| Sound Trigger |
| Play sound on trigger | ||
| Text to Speech |
| Text to speech | ||
| Upload Video |
|
| Uploads a video to your YouTube channel The following package is required: upload_video |
|
| Video Writer |
| Saves Video | ||
| Wi-Fi Server |
|
| Communicate with a device through Wi-Fi |
The Utility filters tools are all under the Utilities category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Colormap Generator |
|
| Generates a colormap which is 1D LUT image | |
| Cuda Download |
|
| Downloads to CPU System Memory from GPU Buffer Memory | |
| Cuda Upload |
|
| Uploads CPU System Memory to GPU Buffer Memory | |
| Distributed Sink |
| Distributed Sink | ||
| Distributed Source |
| Distributed Source | ||
| Exit |
| Exit application when trigger is true | ||
| Get Color |
|
| Extract Red, Green and Blue Color values | |
| Get Double3 |
|
| Extract x, y and z from Double3 value | |
| Get Int3 |
|
| Extract x, y and z from int3 value | |
| Get Double2 |
|
| Extract x and y from point value | |
| Get Int2 |
|
| Extract x and y from point value | |
| Image Information |
|
| Return the width, height, and number of channels of an image. | |
| In JSON? |
|
| Has Key in JSON | |
| Is Batch |
| Returns true if running in batch (command line) mode - useful to decide if to save models | ||
| Get JSON Bool |
|
| Get JSON Bool | |
| Get JSON Color |
|
| Get JSON Color | |
| Get JSON Double |
|
| Get JSON Double | |
| Get JSON Double2 |
|
| Get JSON Double2 | |
| Get JSON Double3 |
|
| Get JSON Double3 | |
| Get JSON Int |
|
| Get JSON Int | |
| Get JSON Int2 |
|
| Get JSON Int2 | |
| Get JSON Int3 |
|
| Get JSON Int3 | |
| Get JSON String |
|
| Get JSON String | |
| Load Camera Calibration |
|
| Load Camera Calibration file | |
| Pixel Information |
|
| For a given pixel, find its R,G,B, Alpha value, and Luminance. | |
| Print to standard output | |||
| RGB To Color |
|
| From RGB to Color value | |
| Run Script |
|
| Run a python script | |
| Set Animation |
|
| Creates a Animation | |
| Set Bool |
|
| Sets Bool value | |
| Set Circle |
|
| Creates a Circle | |
| Set Color |
|
| Sets color value | |
| Set Double |
|
| Sets double value | |
| Set Double2 |
|
| Sets Double Point value | |
| Set Double3 |
|
| Sets Double 3D value | |
| Set Ellipse |
|
| Creates an Ellipse | |
| Set Image2D |
|
| Sets Image value | |
| Set Int |
|
| Sets Integer value | |
| Set Int2 |
|
| Sets Integer Point value | |
| Set Int3 |
|
| Sets Int 3D value | |
| Set JSON |
|
| Sets JSON dictionary | |
| Set Matrix |
|
| Sets matrix value | |
| Set Path |
|
| Creates a Path | |
| Set Rectangle |
|
| Creates a Rectangle | |
| Set String |
|
| Sets string value | |
| Switch Color |
|
| Outputs one of the selected inputs | |
| Switch Double2 |
|
| Outputs one of the selected inputs | |
| Switch Double3 |
|
| Outputs one of the selected inputs | |
| Switch Image2D |
|
| Outputs one of the selected inputs | |
| Switch Int2 |
|
| Outputs one of the selected inputs | |
| Switch Int3 |
|
| Outputs one of the selected inputs | |
| Switch Matrix |
|
| Outputs one of the selected inputs | |
| Switch Numeric |
|
| Outputs one of the selected inputs | |
| Switch String |
|
| Outputs one of the selected inputs | |
| System Performance |
|
| Informs the current System Performance | |
| XYZ to Double3 |
|
| Set X, Y and Z to create Double3 | |
| XYZ to Int3 |
|
| Set X, Y and Z to create Int3 | |
| XY to Double2 |
|
| Set X and Y to create Double2 | |
| XY to Int2 |
|
| Set X and Y to create Int2 |
The User Interface Widgets tools are all under the Widgets category. The full list of display tools is as follows:
| Name | Icon | Inputs | Outputs | Description |
|---|---|---|---|---|
| Widget Note |
| Pin a note | ||
| Widget Bool Trigger |
|
| A widget to triggers a perodic burst to represents bool types | |
| Widget Checkbox |
|
| A checkbox widget that represents bool types | |
| Widget Color |
|
| A color dialog widget that represents color types | |
| Widget Curve |
|
| A curve widget that represents bezier curve types | |
| Widget Double2 Slider |
|
| Two slider widgets that represents double2 types | |
| Widget Double2 Textfield |
|
| Two textfield widgets that represents double types | |
| Widget Double3 Textfield |
|
| Three textfield widgets that represents double types | |
| Widget Double Slider |
|
| A slider widget that represents double types | |
| Widget Double Textfield |
|
| A textfield widget that represents double types | |
| Widget Filebrowser |
|
| A filebrowser widget that represents string types | |
| Widget Int2 Slider |
|
| Two slider widget that represents int2 types | |
| Widget Int2 Textfield |
|
| Two textfield widgets that represents int types | |
| Widget Int3 Textfield |
|
| Three textfield widgets that represents int types | |
| Widget Int Slider |
|
| A slider widget that represents int types | |
| Widget Int Textfield |
|
| A textfield widget that represents int types | |
| Widget Int Trigger |
|
| A button widget to triggers a step jump | |
| Widget Map |
|
| A widget that represents map types | |
| Widget Output |
| A widget that represent a published output | ||
| Widget Password |
|
| A password widget that represents string types | |
| Widget Path |
|
| A overlay drawing path widget that represents path types | |
| Widget Double2 Point |
|
| A point widget that represents double2 types | |
| Widget Int2 Point |
|
| A point widget that represents int2 types | |
| Widget Select List |
|
| A multi select widget that represents string types | |
| Widget Select Menu |
|
| A select widget that represents int types | |
| Widget String Textfield |
|
| A textfield widget that represents string types | |
| Widget Textarea |
|
| A textarea widget that represents string types |
The "System Performance" tool can be used to report performance metrics of your workflow. You can add it to your workflow and it will output a table of counters that will refresh regularly to show the performance for each node. The output table format is described below:
| Column | Description |
|---|---|
| name | Name of the node |
| Work(ms) | Average time in milliseconds to process one frame |
| #Wait | Number of times since last update the node waited as inputs were not ready or didnt change |
| #Render | Number of times since last update the node executed |
| Host to Host(MB) | Amount of System CPU Host memory copied in megabytes |
| Host to Device(MB) | Amount of System CPU Host memory uploaded to the GPU memory in megabytes |
| Device to Host(MB) | Amount of GPU memory to the System CPU Host memory in megabytes |
| Device to Device(MB) | Amount of GPU memory copied in megabytes |
| Peer to Peer(MB) | Amount of GPU memory in megabytes copied between different GPUs when multiple GPU are available on the system |
For Import or Export, files are shown in a custom file selector dialog. Files icons and Folder icons are selectable. You have restricted access to the files that are located in either the ${assets} or ${demos} folders where INFINIWORKFLOW is installed. To import your own images, copy the files to the ${assets} folder and then they will be available to select in the file selector dialog.
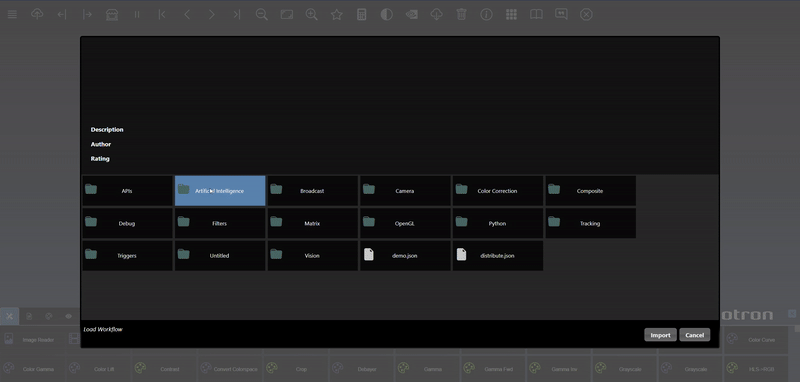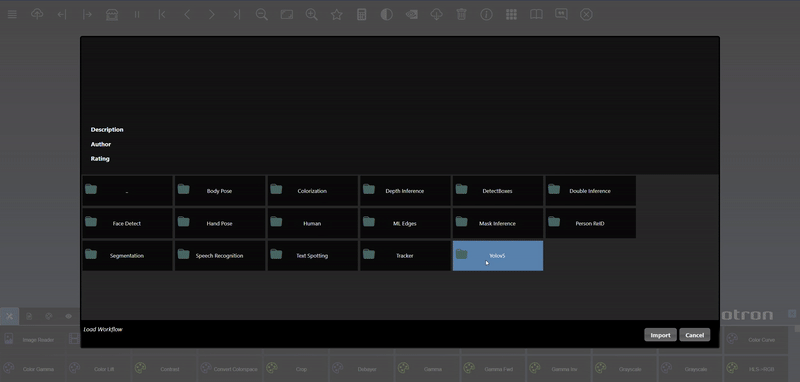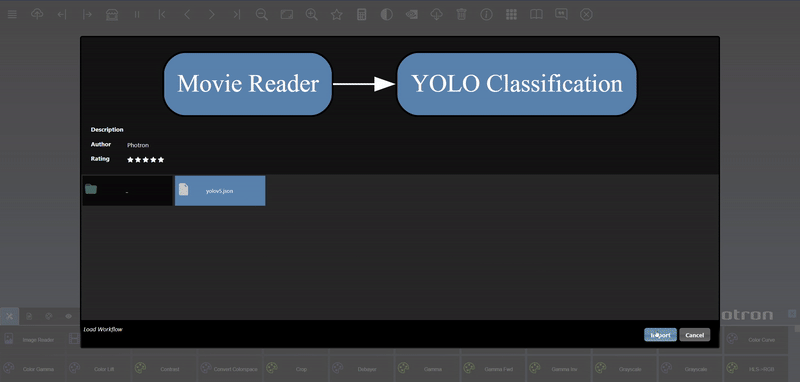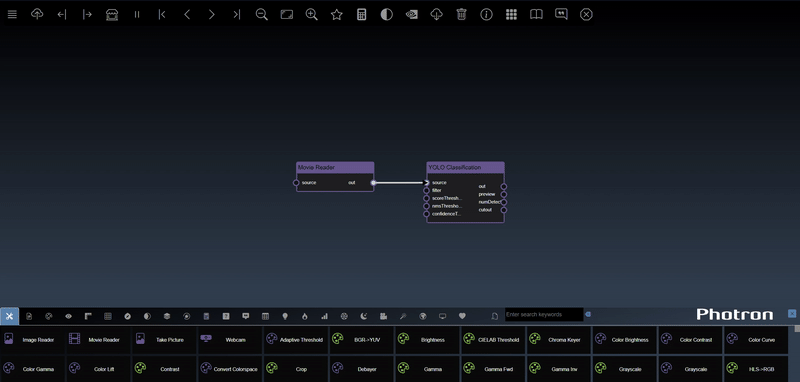
You can set the hyperparameters using the node context menu and selecting 'Hyperparameters'. This brings up a dialog that allows you to select each input parameter and also set the range of values you want to have as part of the Grid Search. The dialog also includes the documentation for the model including the values expected for each hyperparameter argument.
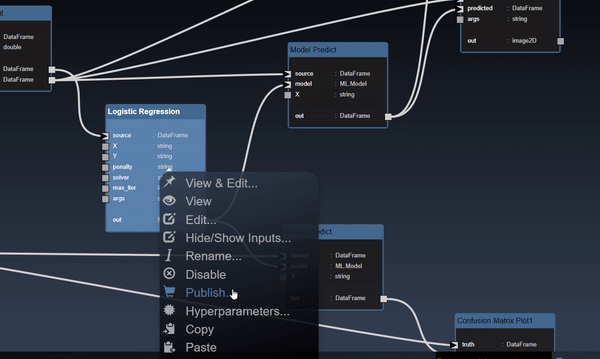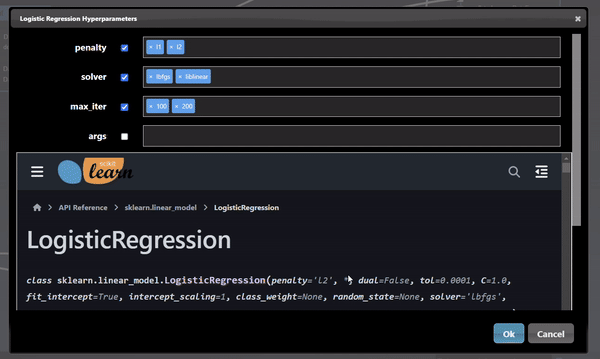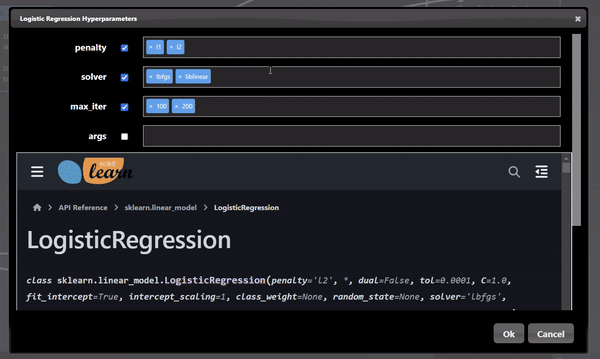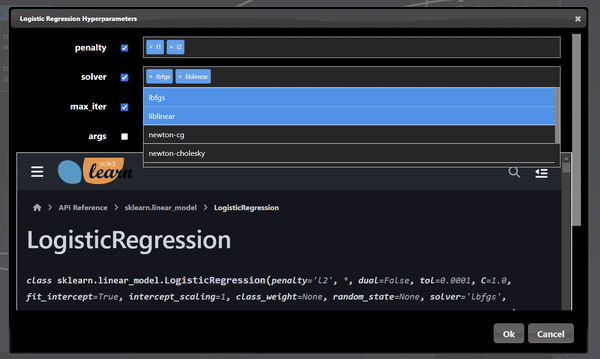
Once you have created a ML model using the ML Toolsyou have refined your 'Hyperparameters' then you can start a Grid Search on a metric node you wish to maximize or minimize such as the "R2 Score" ML tool. Select the metric node and then bring up the context menu and select 'Grid Search':.
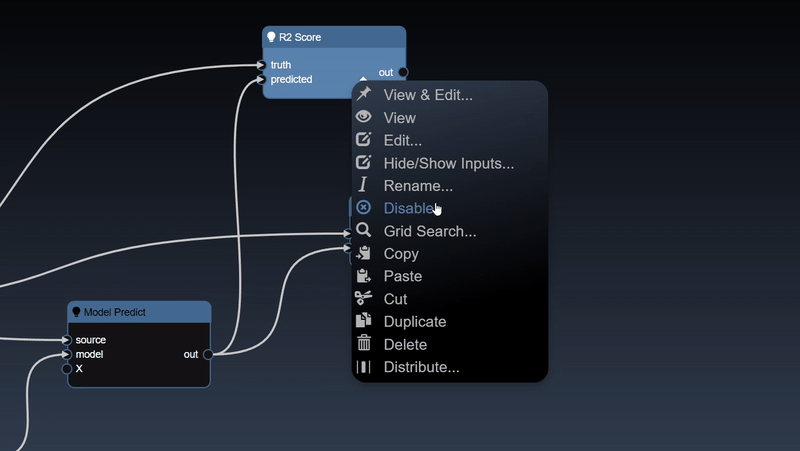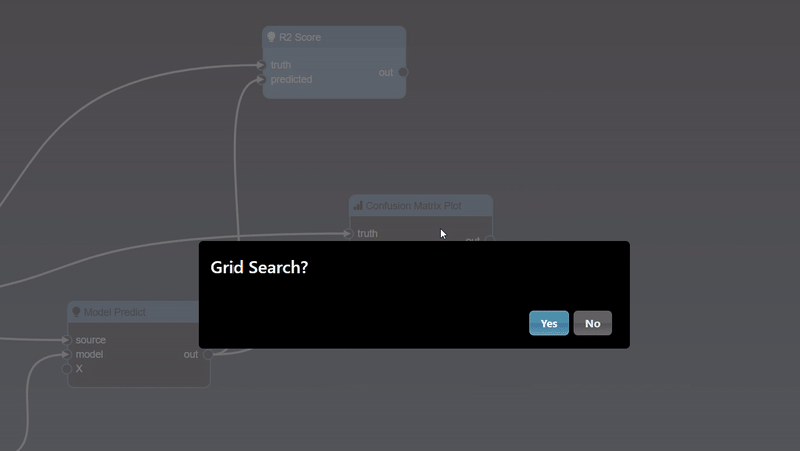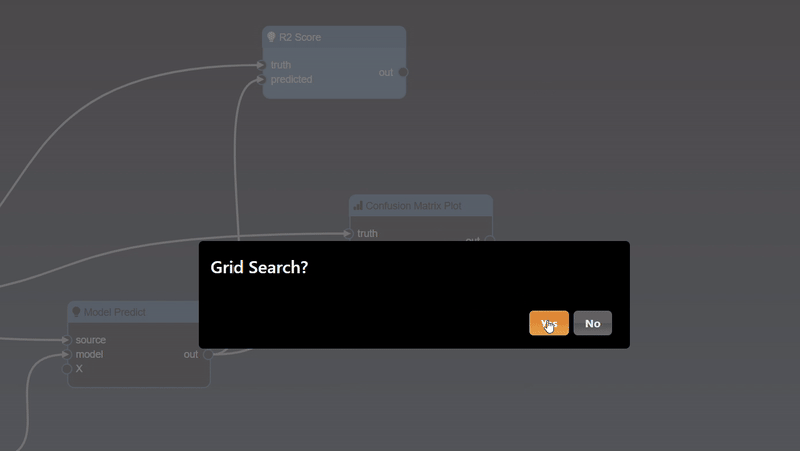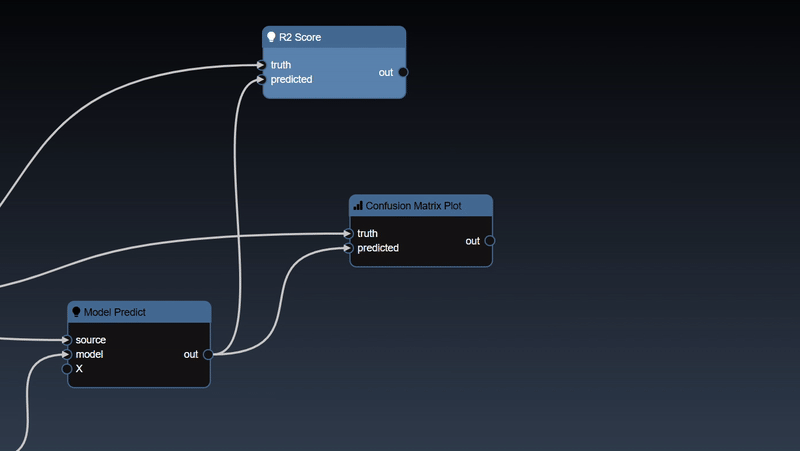
The results of the Grid Search are done in a different process but you can see the results by clicking the icon in the application menu. The dialog will show the latest progress for each combination in the grid search and color indicators to show which is the highest or lowest value so far found.

After the Grid Search has completed you can see the final results by clicking the icon in the application menu. You can click the Selct link in one of the rows to optimize your model which sets the hyperparameters values to the selected row.
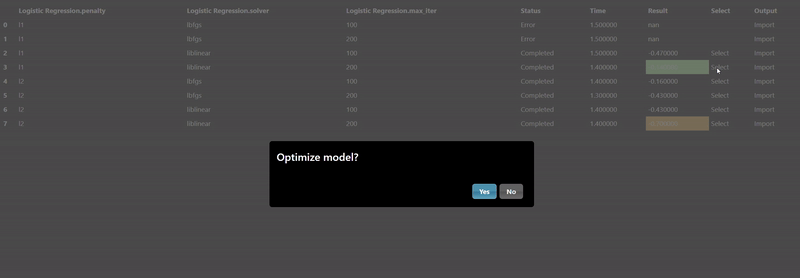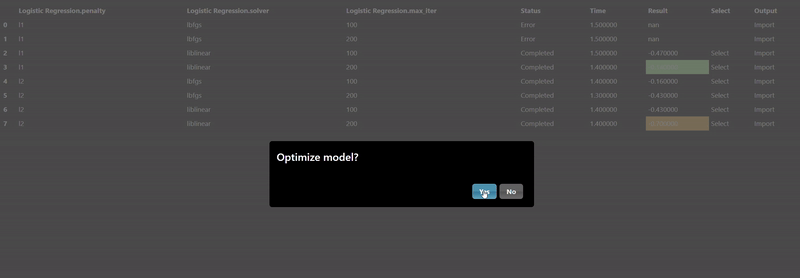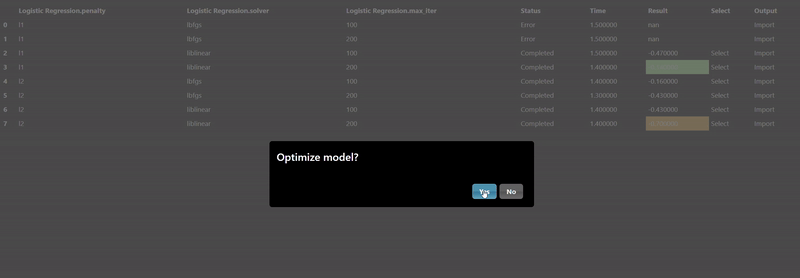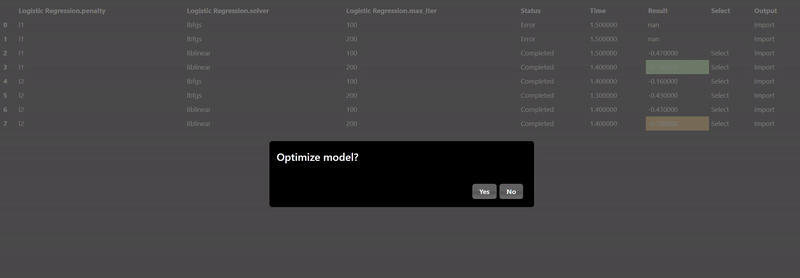
You can also click on the Import link to load the assets created during the Grid Search. Each ML model tool allows you to save the model to a file, by default models will not be saved but it is recommended whenever you have complex models that take time to execute. A common practice when doing a Grid Search is to connect the "Is Batch Tool" to the "save" input parameter of the model - this will always be true when a Grid Search is being done in the background batch process - thus, all the the models will be saved during the Grid Search process. The import will then allow you to copy the model into your workflow folder:
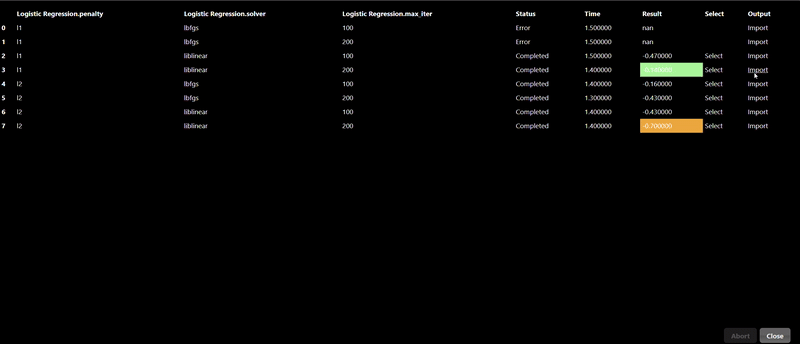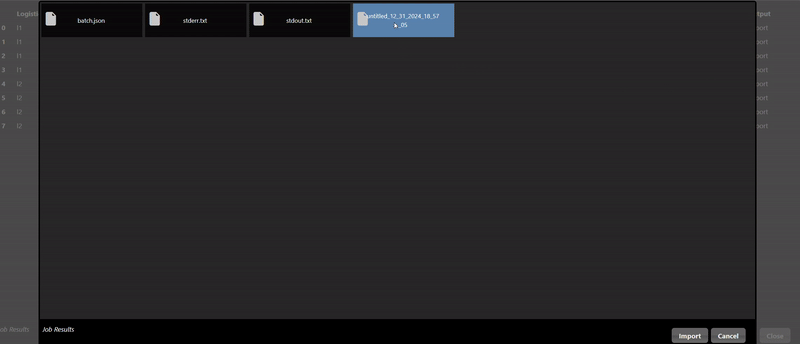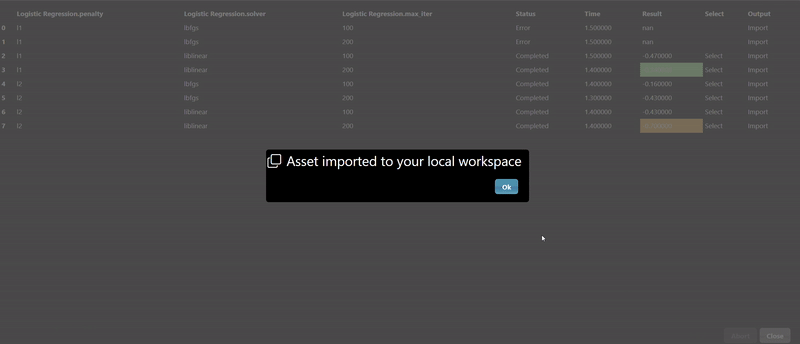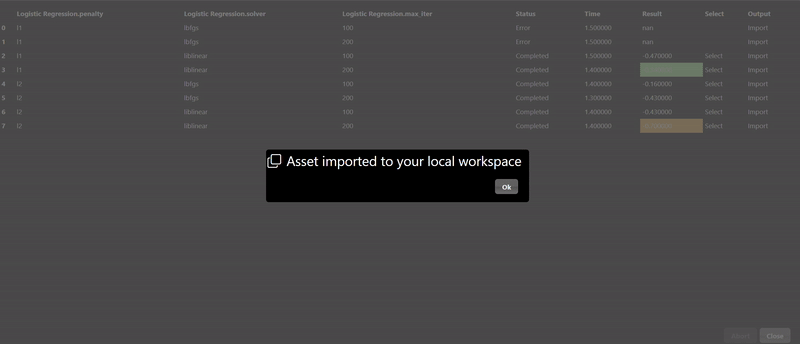
When building models using the Torch nodes, the neural networks can get large with multiple nodes to generate the entire neural network. You can create a macro to create a tool that replaces all the nodes with a new tool which can be further used in the future and promotes sharing of models. To create a macro, select the node in your flowgraph that is a "Sequential" Torch Tool , then show the context menu for the node and select 'Create Macro'. The dialog allows you to name and set optional notes that will be associated with this new tool.
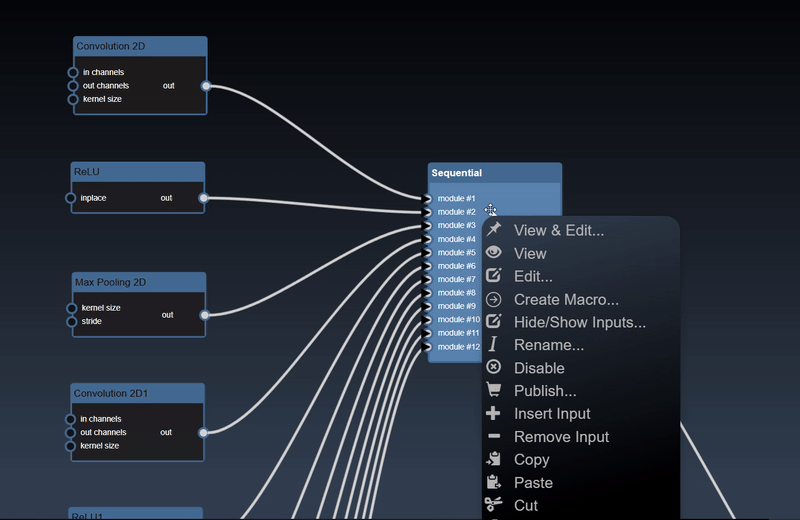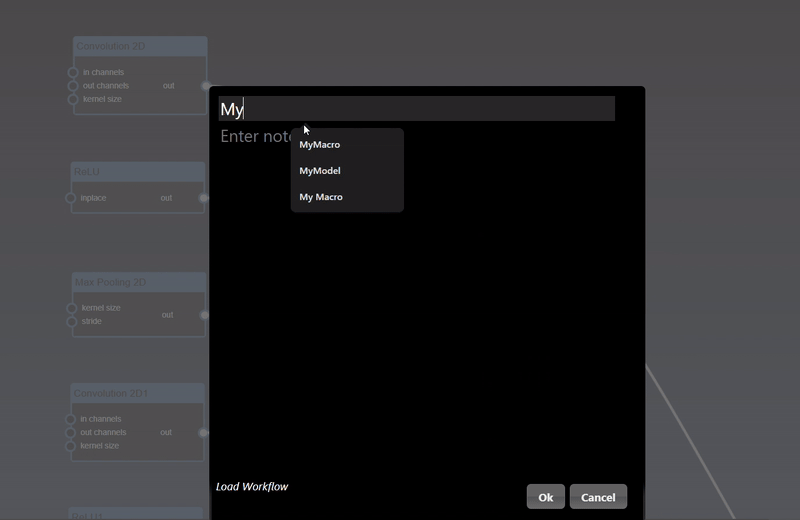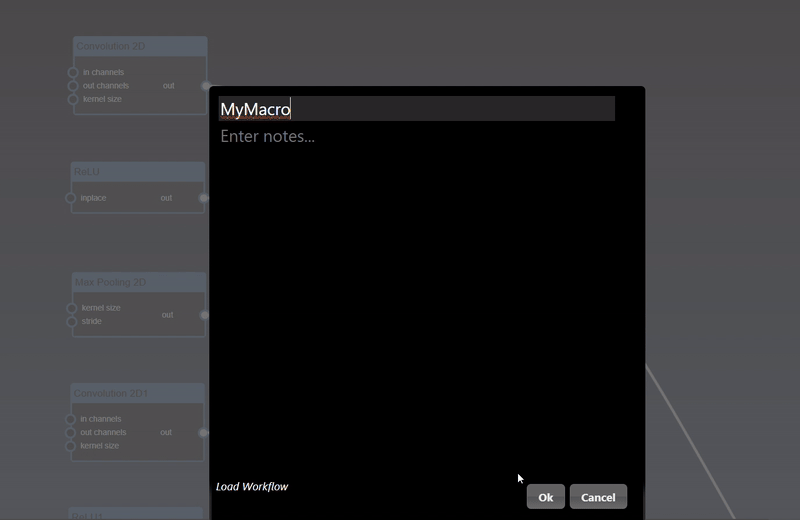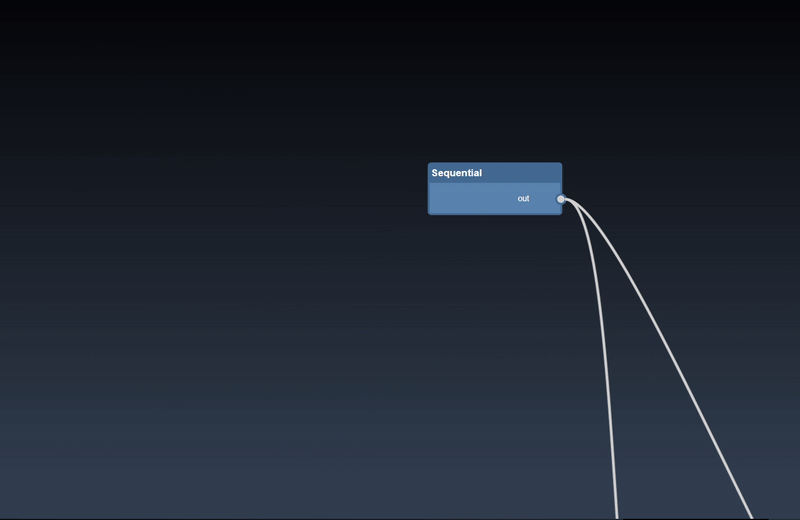
PyTorch is an open source machine learning framework that is excellent in performing Deep Learning.
You can find the properties of a tensor by using nodes such as Size, Dimension, Mean, Sum, Standard Deviation, and more. Further, you can combine two or more tensors together via either basic arithmetic (add, subtract, multiply, divide, etc.) or concatenation (concatenate, horizontal stack, vertical stack, etc.).
Additionally, you can convert tensors to and from DataFrames, NumpyArrays, and Images.
In PyTorch, a tensor can be one of many data types. In Infiniworkflow, all tensors are of data type torch.float32 by default (as this is the standard default within PyTorch as well). However, if you wish to change the data type of a tensor, simply drag in a Set Default Type node into the workflow and select one of 4 data types: torch.float32, torch.float64, torch.float16, and torch.bfloat16. This will change the data type of ALL tensors within the workflow. Note that this node doesn’t need to be connected to any other node to work; simply having it somewhere within the workflow is enough.
Neural Networks in Infiniworkflow can be Trained, Tested, and finally exported to a custom AI Inference node or exported to ONNX. The following sections will break down how to create a neural network, along with bringing in custom datasets and creating your own Inference Macros based on the neural nets you create.
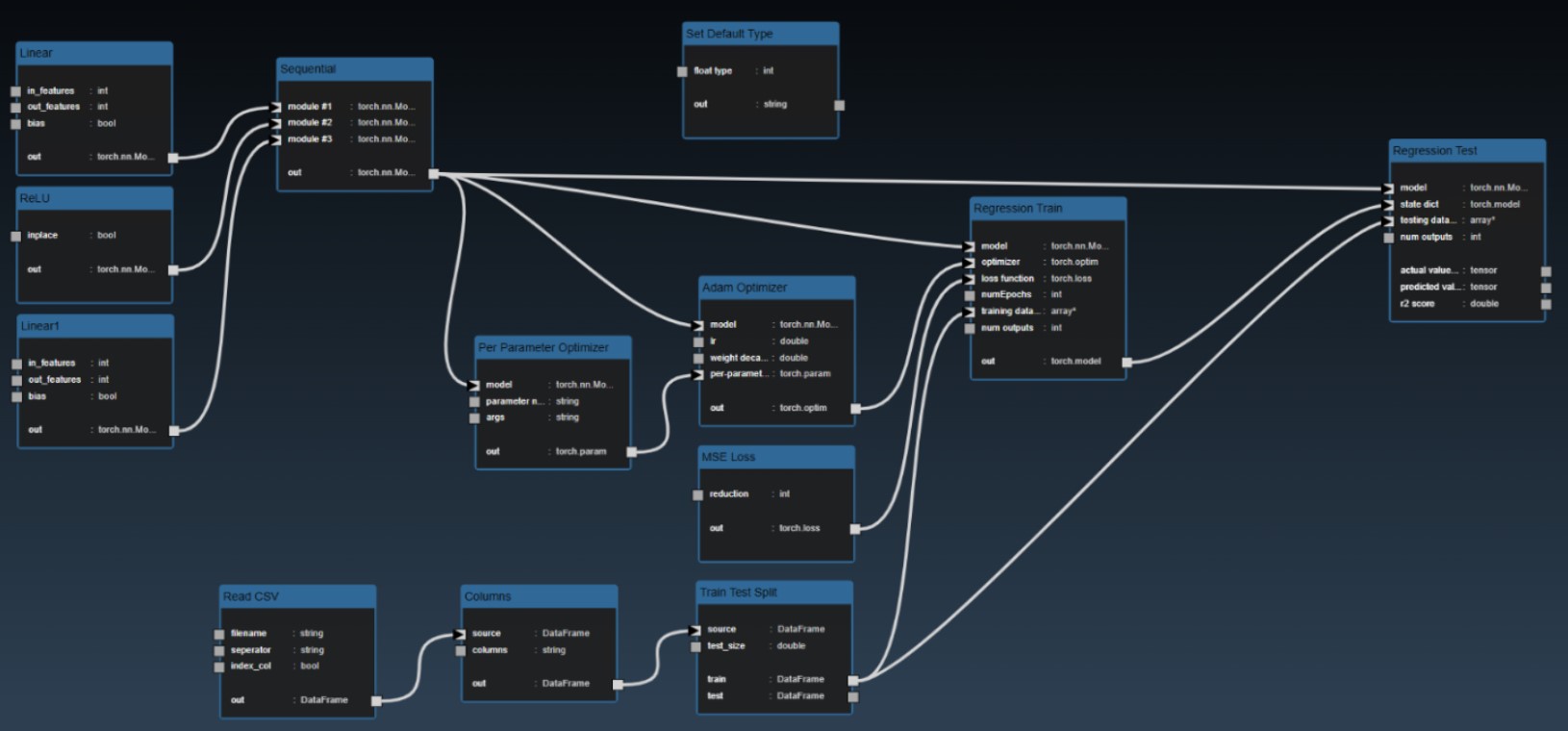
The steps for creating a Neural Network, whether that be for Regression, Classification, or Segmentation, are more or less the same. The following section will describe in detail how to create a Neural Network for Regression, but most all steps can be copied for Classification or Segmentation. Exceptions and differences to note for creating Classification or Segmentation Neural Networks will be detailed at the end of this section.
To begin regression training (or any kind of training for that matter), we need 4 key inputs: a Neural Network Model, an Optimizer function, a Loss/Criterion Function, and the Data that the model will train on.
The Sequential node performs two actions behind the scenes. Firstly, it combines all machine learning modules that are provided as inputs (including nodes such as Linear, ReLU, Conv2D, MaxPooling2D, LogSoftmax, etc.) into a PyTorch Sequential container; to adjust the amount of input modules the Sequential node takes in, simply right-click on the Sequential node and click “Add Input” or “Remove Input”. Then, the Sequential node takes the Sequential Container and creates a neural network model out of it, with a base class of torch.nn.Module. The output of the Sequential node will thus be the “model” input of the Regression Train node.
Several optimizer functions are included in InfiniWorkflow. Most are intuitive (simply set the Neural Network Model as an input, set the Learning Rate and Weight Decay as needed, then set the output of the Optimizer node as an input to Regression Train), but the Per Parameter Optimizer is easy to misunderstand. The Per Parameter Optimizer node only works in tandem with another Optimizer node (such as Adam Optimizer), so make sure to connect the output of Per Parameter Optimizer as an input to the standard Optimizer node.
Using the Per Parameter Optimizer, specify the individual penalization weights you wish to set for specific parameter groups from your model; note that, if you wanted, you could set an individual penalization weight for each of your model’s parameter groups, but you would need to have a Per Parameter Optimizer node for each of these weights (additionally, you would need to Add Inputs to your standard Optimizer like an Adam Optimizer, and then feed each of your Per Parameter Optimizer nodes into your standard Optimizer). Any parameter groups that are not explicitly specified in any Per Parameter Optimizer nodes will take on the weights specified by the standard Optimizer node.
The output of the standard Optimizers is a torch.optim. Connect this as an input to the Regression Train node.
Several loss functions are included in InfiniWorkflow. Simply connect the one you would like to use as input to Regression Train.
In order to perform Regression, you need clean, numerical data. Assuming that your data is viable, set it as the input to the Train Test Split node. This will allow you to split data into Training data and Testing data. Set the Training data as an input to the Regression Train node.
Edit the Regression Train node and hit the Trigger button to initiate training. You can see the status of the training in real-time by hitting the [Render Status] icon in the application menu. If at any point you want to stop training, simply hit the Abort button within the Render Status Console. If you would like to save the output model once training is complete, click the “save state dict” box to enable saving, and specify where on your local machine you would like the output to be saved to.
With training complete, you can now begin testing your data, which you can do in 2 main ways. The first way is to have a Regression Test node in the same workflow as your Training, and connect the nodes appropriately. The second way is to use a Load Torch Model node, which you can only do if you saved the training output model to your local machine. Note that if you do want to use the Load Torch Model, you need to hit the Trigger in order to bring the data in from your local machine into Infiniworkflow. Furthermore, if you use this method you can have your training and testing in different workflows entirely. However, you would need to either recreate your model entirely (i.e. the Sequential node and all modules that feed into it in your Training workflow), or alternatively create a Macro on the Sequential node in the Training workflow such that the Macro can then be instantly brought into your Testing workflow (and any other workflow you want).
Your training and testing is now complete. The same steps can be repeated for performing Classification or Segmentation, with the biggest exception being the way that the datasets for Classification or Segmentation will appear in Infiniworkflow. An example from the CIFAR10 Dataset can be seen below. View and edit the node and set the “train” input to either Train, Test, or Validate (if Validate is an option).
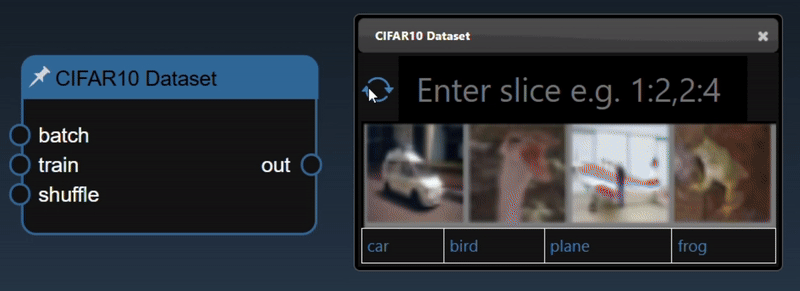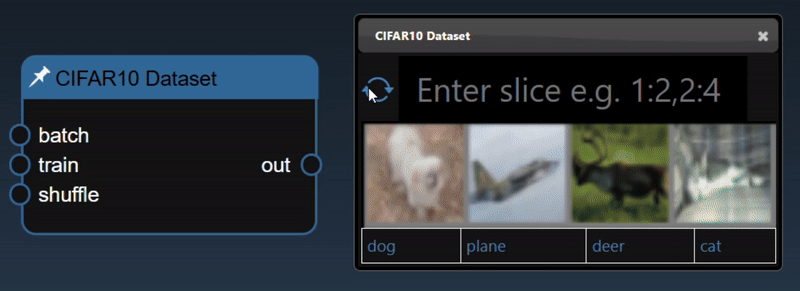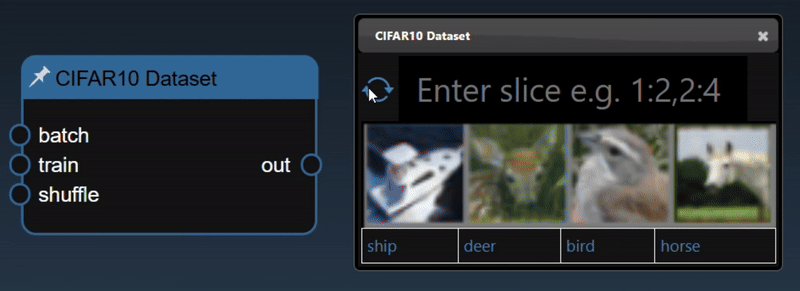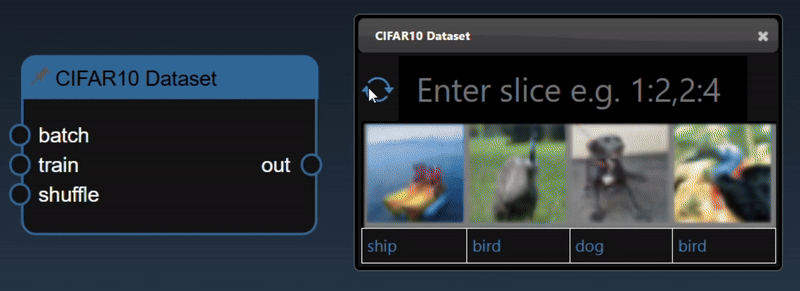
Below is an example of a training workflow for a Convolutional Neural Network that performs Classification on the MNIST Dataset. Note the similarities between this and the Regression example seen above, with the principal exception being the number of layers that are fed into the Sequential node.
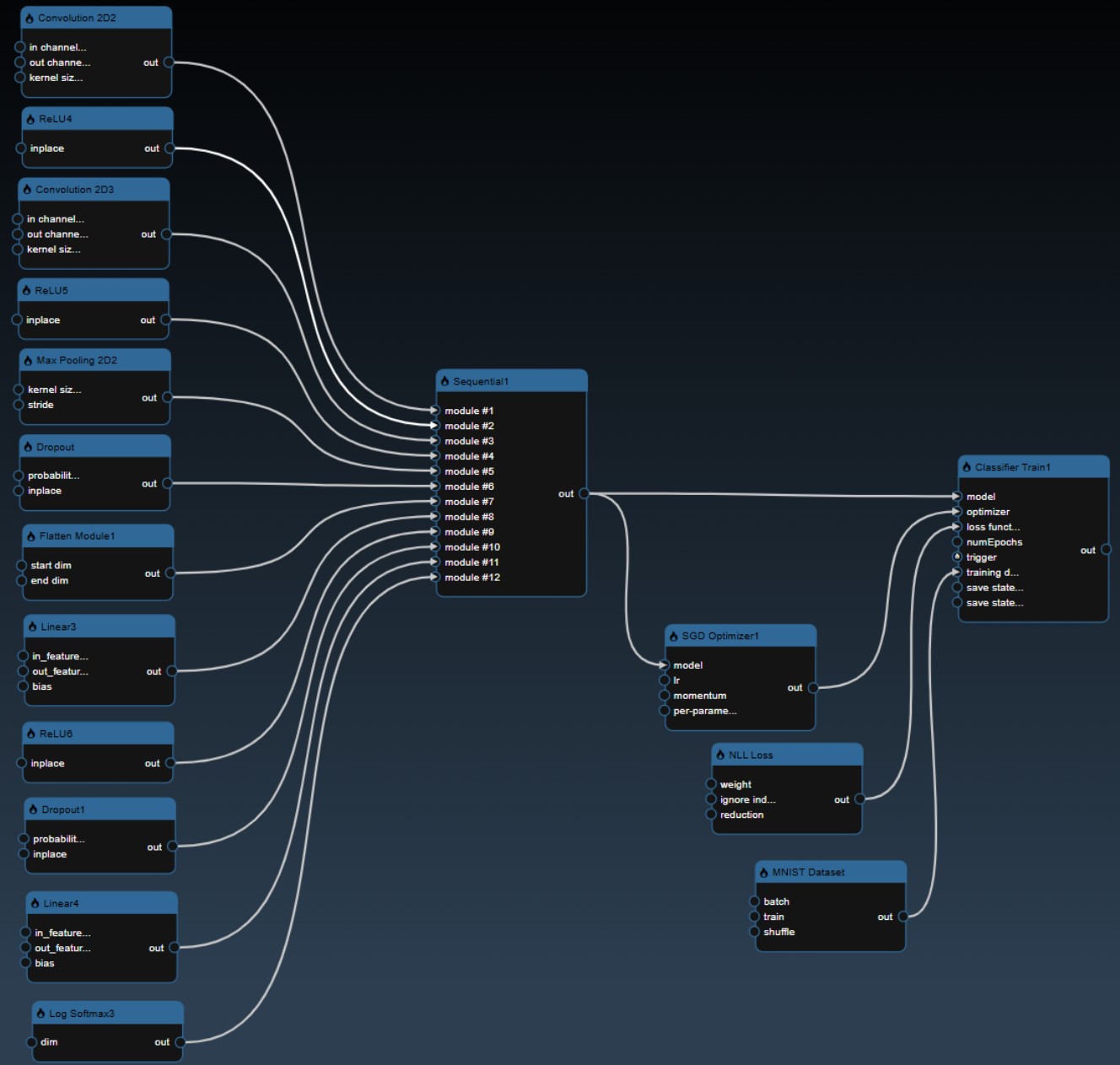
If you wish to create a Convolutional Neural Network (like the one depicted above) but do not want to immediately attempt creating the neural net from scratch, you can use the Convolutional Neural Net node instead to rapidly prototype your desired neural net.
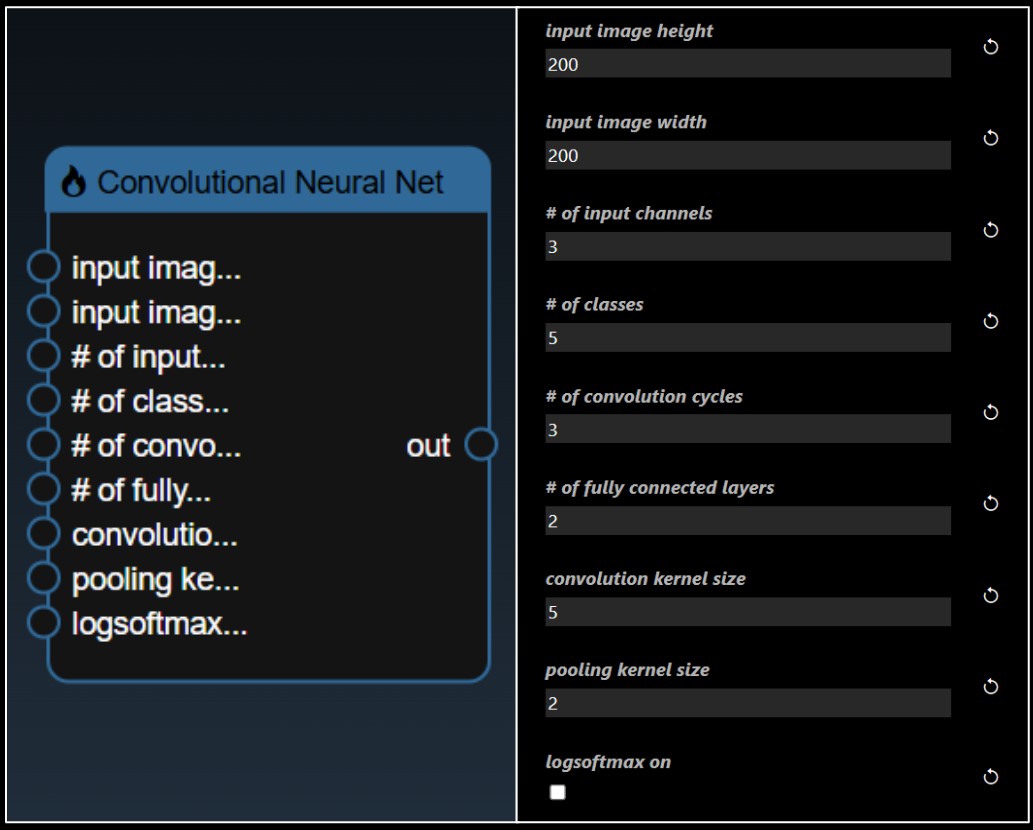
The first three inputs relate to information on the input image data that this CNN will be trained on. The fourth input is how many classes the CNN will be trained to identify. All CNNs are composed of various convolution cycles followed by various fully connected layers. Since this node is meant for rapid prototyping, what is within each of these layers is already set. Each convolution layer is composed of a Convolution 2D, ReLU, and Max Pooling 2D node; each fully connected layer is composed of a Linear and ReLU node, apart from the last fully connected layer, which only has a Linear node. A Flatten node separates the convolution layers from the fully connected layers. Specifications for kernel size can be set in the convolution kernel size and pooling kernel size inputs. The final input is a boolean of whether the CNN ends with a LogSoftmax node at the end. Once again, this node is meant for primitive prototyping, and therefore is not fully robust; each fully connected layer only halves the number of filters until it gets to the desired number of classes the dataset identifies.
A few common datasets are already implemented in Infiniworkflow for classification and segmentation. These include CIFAR10, MNIST, FashionMNIST, and Cityscapes.
Bringing in custom datasets can be done in one of two ways. The first is via the Generic Dataset node; simply specify the naming convention of your inputs and outputs (X and Y), list all the classes, set the directory of where the dataset is coming from on your local machine, and set a colormap if one exists (for the purpose of segmentation).
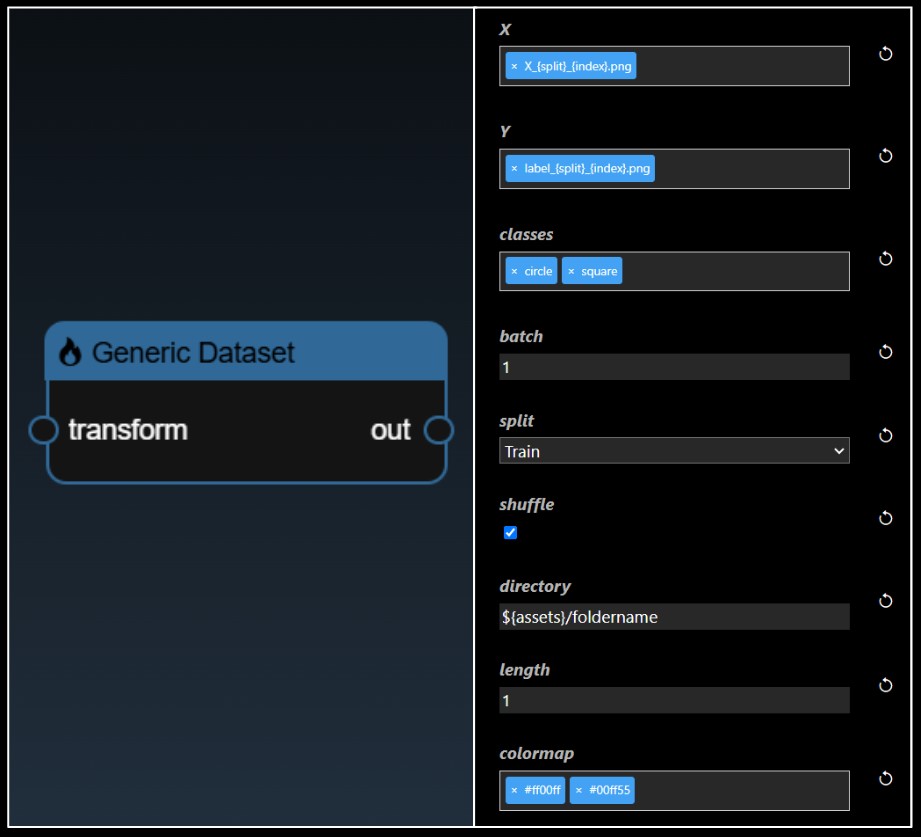
The second (and probably more useful) approach is to create a plugin for your desired dataset. Refer to the Customizing Tools section on how to do so.
Once a model has been trained, users can then take their model and immediately begin using them within Infiniworkflow as a custom node for AI Inference. These nodes are called Inference Tools. (Alternatively, after a model is trained, the model and its weights can be exported to ONNX, a popular machine learning framework, using the Convert To Onnx node.)
To create an Inference Tool, simply right-click and select “Create Inference Tool” after your model has been trained. NOTE: The “Create Inference Tool” option will only appear under a Training Node (i.e. any node that is capable of training a model) after the model has been trained, not before.
Fill in the name of your Tool and any notes associated with it, and hit “Ok”. A prompt should inform you that “New tool has been added”, one which you can find in the toolbox alongside your other nodes. This node will now be able to perform AI Inference using the machine learning model you created and trained.

Pyrender is a Python library for physically-based rendering and visualization.
There are three primary object types to know to render a Scene; these are Meshes, Lights, and Cameras.
A Mesh node is basically a wrapper of any number of primitive types. These primitive types represent the physical geometry that can be drawn to the screen. Infiniworkflow allows users to load meshes from existing Trimesh objects. In the assets folder, ensure all necessary files (including the object file, material file, and UV file) are included in order for the mesh to appear correctly when brought into a Scene, as seen below.
The output of a Mesh node is a 3DNode (in Pyrender, “Node” is the name of one of the most commonly-used classes when creating a Scene; in order to avoid confusion between Pyrender Nodes and Infiniworkflow’s Nodes, we have elected to denote Pyrender Nodes as a “3DNode”).
In addition to Meshes that come from existing Trimesh objects, you can also create your own basic 3D objects from scratch using the Trimesh Creator nodes. These basic objects include boxes, capsules, cones, icospheres, and toruses. The output of each of these Trimesh Creator nodes (such as “Trimesh Box” or “Trimesh Capsule”) is a 3DNode.
Pyrender supports 3 types of Light: PointLight, SpotLight, and DirectionalLight. The output of any of these 3 Light nodes is a 3DNode.
Pyrender supports 3 Camera types: PerspectiveCamera, IntrinsicsCamera, and OrthogonalCamera. The output of any of these 3 Camera nodes is a Camera (NOT a 3D Node).
To begin creating a Scene, bring in a Render Scene node from the Pyrender toolbox (marked with a 3D icon). The camera that you choose to view your scene with is the first input to the Render Scene node. The final input is for any 3DNodes you want to be present in your scene (i.e. Lights, Meshes, etc.); the Render Scene node allows users to add as many 3DNode inputs as they wish. The output of the Render Scene node is a Color (or Default) viewer, Depth viewer, and Segmentation viewer. Each of these viewers will be explained in further detail below.
If you have been following these steps so far, it is likely that your scene does not show anything. This is because you need to position your Camera and your 3DNodes where you want them. To do this, use a Transformation Matrix node or a LookAt Matrix (generally Transformation Matrices are used for nodes that output a 3DNode and LookAt Matrices are used for nodes that output a Camera, but any of these matrix nodes could be used in practice). Your final workflow might look something like this:
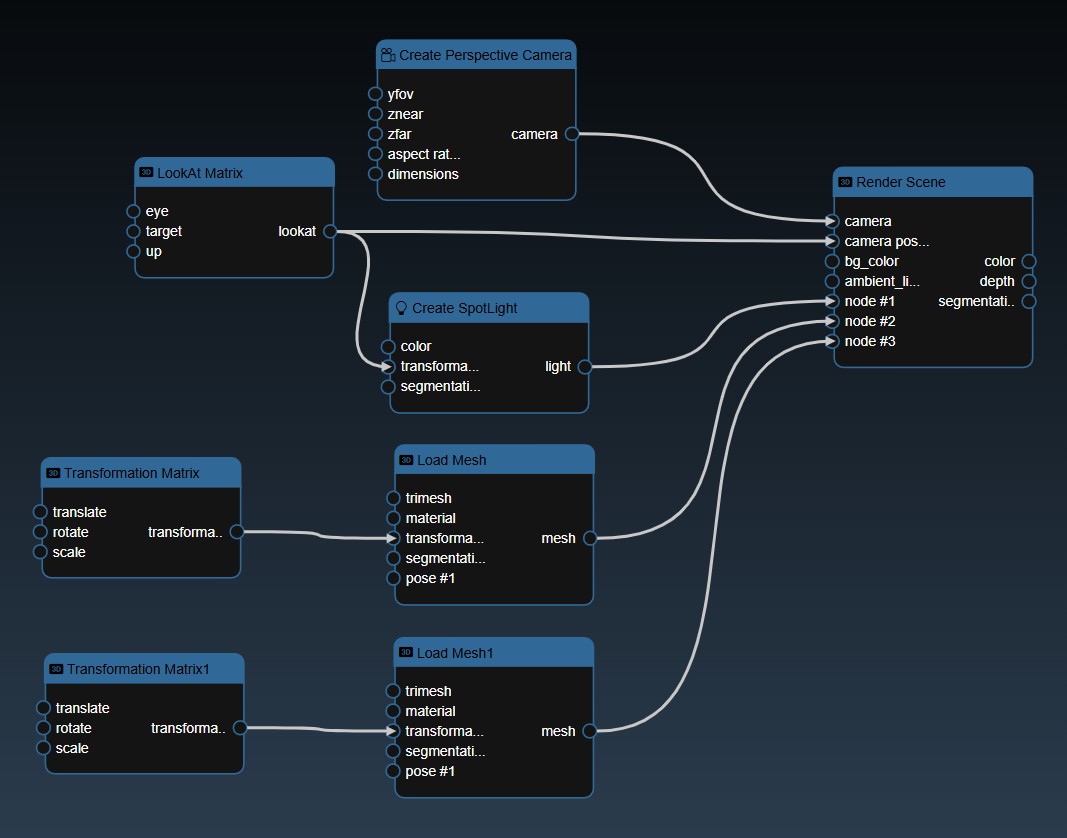
The following is a description of each of the three output views from the Render Scene node. The first output is Color, which presents a Pyrender Scene in full color; this can be considered as the Default view. Behind the scenes the Render Scene node is performing offscreen rendering, which Infiniworkflow then displays.

The second output is Depth, which presents the Pyrender scene as a depth map using Matplotlib.
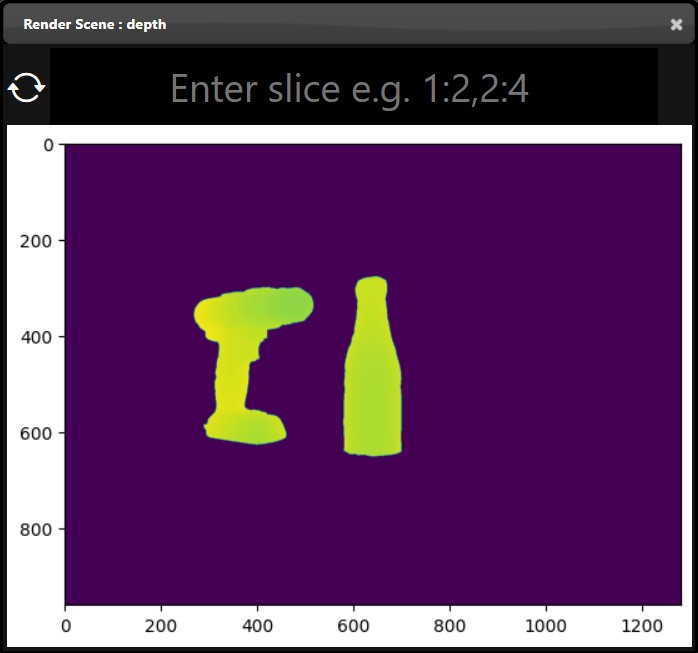
The third output is Segmentation, which presents the scene in a divided view where each object has a single color view. All Pyrender nodes that output a 3DNode have an input field called “Segmentation Color”, so if you wish to change the color a particular object has in the Segmentation view, you may do so there.
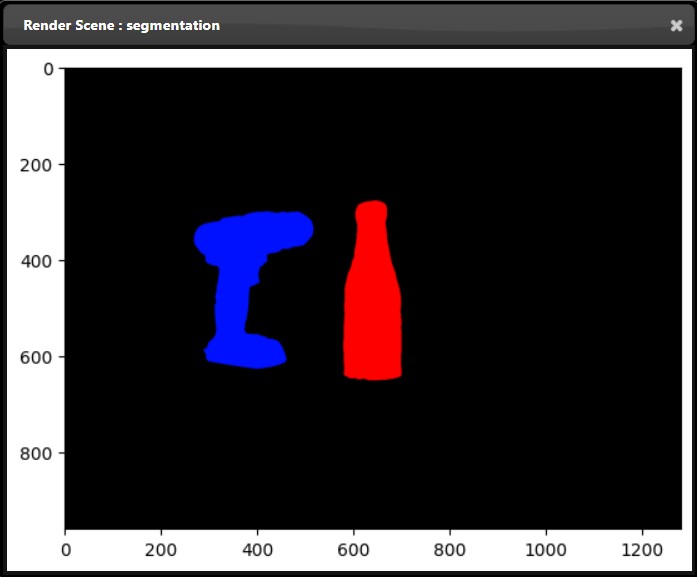
YOLOX is a version of the computer vision object detection model YOLO (You Only Look Once) that is better for fine-tuning.
Training a pretrained YOLOX model on custom data requires a dataset as well as some hyperparameters. YOLOX Train Custom Data
The image dataset must be in COCO or VOC format and labeled using Labelme or CVAT. The YOLOX Train node takes in the COCO/VOC dataset directory, train annotation/labels JSON, and validation annotation/labels JSON.
The hyperparameters include image size (416x416 for YOLOX light models, 640x640 for standard YOLOX models), the number of unique classes in the dataset, and the filepath to the checkpoint or pretrained PyTorch (.pth) model.
The experiment (exp) file contains all the other hyperparameters that can be adjusted, with args exposing a select few for ease of use.
The name and output directory determine the name of the fine-tuned model (.onnx) and the output directory where the log data is written to, as seen below:

The YOLOX Train node outputs a model that is trained on the input dataset, so it can classify things outside of the 80 COCO classes that it is originally trained on, like manholes.
Tensorboard is a web-based visualization tool for tracking machine learning training and validation errors.
It simply takes in the output directory of an ML training process and a localhost port to be hosted on.
If port is 6006, then triggering the node and opening localhost:6006 will show graphs like these updating live as the model trains:


ONNXRuntime is a high-performance engine tool for ONNX models.
INFINIWORKFLOW features an general-purpose ONNXRuntime node as well as a YoloxOnnxRuntime node.
Fortunately, the YOLOX Train node outputs an .onnx model, so the YoloxOnnxRuntime node can be used.
The relevant inputs for running inference on YOLOX are the model input, the list of class labels if they are not the standard COCO classes, and the input size (416x416 for YOLOX light models, 640x640 for standard YOLOX models).

The YoloxOnnxRuntime node outputs a preview of the detected objects as well as an output matrix.
This feature allows you to do processing on a different process on the same machine or a different machine on the network. You can start the distributed rendering by selecting a contiguous set of nodes and then using the node context menu and selecting 'Distributed'. This brings up a dialog that allows you to set the URL for the server as well as the CUDA Device on that system that will be performing the processing. The default URL is for the same system you are running INFINIWORKFLOW. Once you click Ok then the selected nodes are replaced by two nodes, the Distributed Sink and Distributed Source. The Sink node will send data from your system to the distributed server and the Source node will receive data from the distributed server.
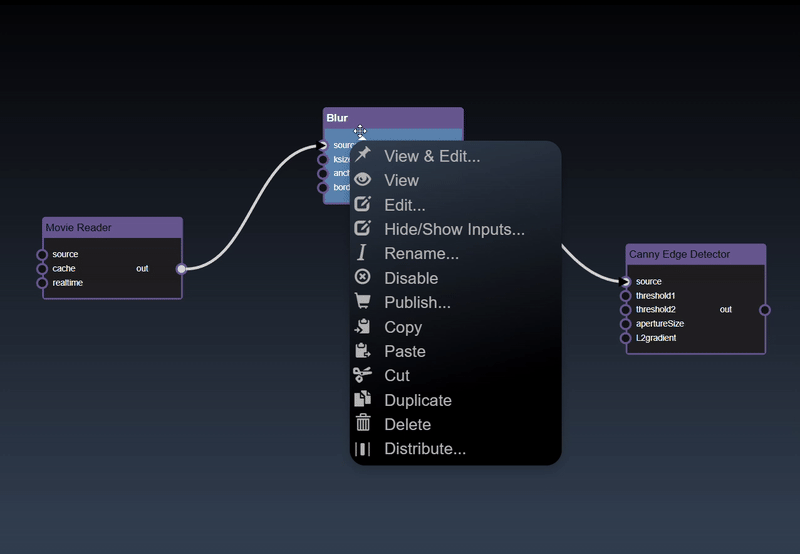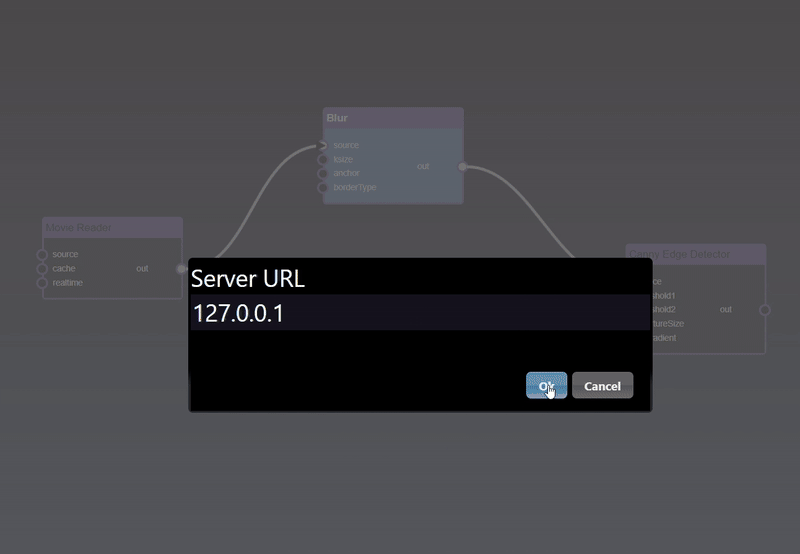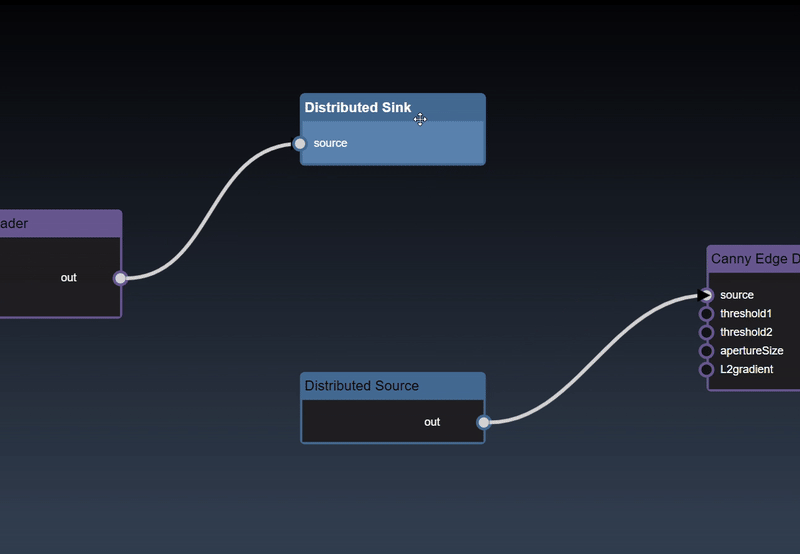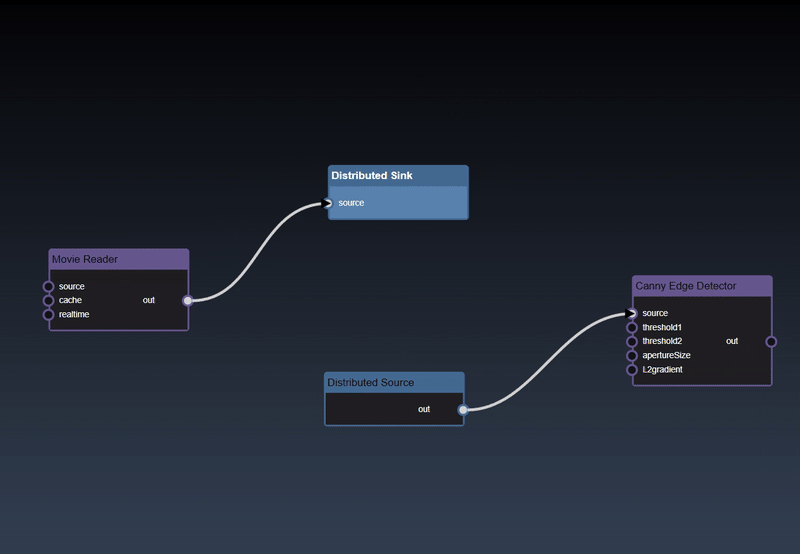
ROS is a set of libraries used to communicate with robotic devices including robotic cars and arms.
Everything in a ROS system is a node, communicating with one another through topics, services, and actions.
Every ROS node in INFINIWORKFLOW corresponds to a ROS node in a ROS system.
Technically, INFINIWORKFLOW only supports ROS2, but they are referred to interchangeably in this manual.
ROS Publishers and Subscribers communicate by streaming data to and from a ROS topic.
The ROS2 Publisher node takes in a ROS topic name and a string message.
On trigger, it broadcasts the string message to the specified ROS topic once a second.
The ROS2 Subscriber node takes in a ROS topic name as input.
On trigger, it outputs received messages from the specified ROS topic.
Devices that support ROS manifest themselves as ROS servers, which typically contain both service servers and action servers.
Instead of getting continual updates like publishers and subscribers, services only provide data or take effect when requested to by a client.
Like services, actions are only executed when called by a client. Unlike services, actions typically involve sending a goal and the action server can provide feedback on its progress towards that goal.
The ROS2 Server node takes in a ROS package name and executable file.
On trigger, this launches a ROS server that includes service and action servers.
By default, the ROS2 Server node launches the turtlesim_node of the turtlesim package, but this can be robotic arms, cars, or any other ROS node.

The ROS2 Service Client node takes in a ROS service name, the input type of the service, and args representing the input.
On trigger, this queries the specified ROS service with the args input for some information or effect.
By default, the node calls the /spawn service of the turtlesim_node, which spawns a turtle at its default position in the bottom left corner.

The ROS2 Action Client node takes in a ROS action name, the input type of the action, args representing the input, and a feedback bool.
On trigger, this uses the args input to set an objective for the specified ROS action and outputs its progression to that goal if feedback is true.
By default, the node calls the /turtle1/rotate_absolute action of the turtlesim_node, which rotates turtle1 to a specified angle; in this case, {theta: 1.57}.
The service can be any supported service on any ROS node, so the ROS2 Service and Action Client nodes can interact with devices like robotic arms and cars.


The Publish feature allows you to simplify your workflow to just a subset of 'Widgets'. The future goal of this feature is to allow you to publish a simple app that has the critical controls that are needed in the deployment of your workflow in production whilst hiding the complexity of the workflow. The first step is to add 'Widgets' on the node inputs you want to publish as well as widget outputs to the node outputs. An example of this is as follows, where a Filebrowser, Selection List and Slider are added to the flowgraph as well as two output view widgets:
You can further refine the widgets by opening the editor and you can set the attributes such as the name which will show in the published view for each widget. Widgets such as Sliders allow you to set their specific attributes such as the minimum, maximum and step value for the Slider widget. All widgets have the common attributes of the name and description (used for tooltips) as well as layouts. The layouts allow you to specify an optional Tab widget the widget will be placed in and also the order in which the control, a lower number will allow the control to be higher up in the layout. An example of the Widget Slider's parameters are as follows:
The widget outputs allow you to specify the name of the output, used in the tooltip, as well as an optional order of the view output and an optional icon. If no icon is present then a standard set of numbers will be shown. The views are shown in the toolbar when the published view is shown, for example for the two widget outputs, you would see the following icons in the toolbar. Hovering over the icons will show the tooltip and clicking on them will view the particular output

Once you have selected the subset of input and outputs then you can click on the publish icon in the application menu and the flowgraph is hidden and a simpler UI only showing the published controls in the Parameter Editor and a fullscreen viewer is shown. You can switch back to the standard flowgraph view by pressing the publish icon again. The Parameter Editor will show the widgets you have defined in your flowgraph using their attributes such as their name and layouts:
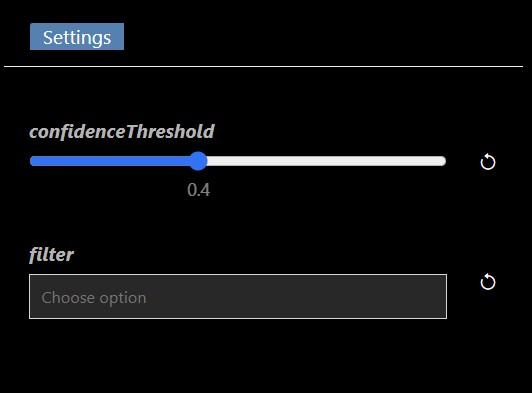
INFINIWORKFLOW runs on a modern PC with Windows 11 or higher or MacOS 12.6.2 or higher. It requires an Intel or AMD processor and ideally a NVIDIA GPU with 12GB+ of disk space. It is highly recommended to have a multicore processor as the execution will be more smoother. On Windows the software will run on machines without a NVIDIA GPU but that will significantly reduce the performance especially for ML workflows. A package with no dependencies on Cuda or PyTorch is also available to download - this will not require a NVIDIA GPU to be present on your system and is substantially smaller in size but does not allow you to build deep learning models and is slower for AI inference. You must also have the latest Google Chrome browser installed : 131.0.6778.140 or higher.
The following are the full set of downloads packages:
| Operating System | CUDA Installation | Non-CUDA Installation |
|---|---|---|
| Windows | infiniworkflow | infiniworkflow_noncuda |
| MacOSX x86_64 | Not applicable | infiniworkflow_osx_x86_64 |
| MacOSX arm64 | Not applicable | infiniworkflow_osx_arm64 |
| Linux x86_64 (Ubuntu22.04.5 LTS) | infiniworkflow_linux | Not available |
| Nvidia Jetson | infiniworkflow_jetson | Not available |
| Operating System | Link |
|---|---|
| INFINIWORKFLOW PATCH - Windows | infiniworkflow_patch |
| INFINIWORKFLOW PATCH - MacOSX x86_64 | infiniworkflow_osx_patch |
| INFINIWORKFLOW PATCH - MacOSX arm64 | infiniworkflow_osx_patch |
| INFINIWORKFLOW PATCH - Linux | infiniworkflow_linux_patch |
| INFINIWORKFLOW PATCH - Jetson | infiniworkflow_jetson_patch |
Make sure you have the latest Google Chrome browser installed : 131.0.6778.140 or higher and it is set to your default browser. Then download the INFINWORKFLOW package from Photron's website. There are multiple packages, the first package to download is infiniworkflow_v1_0.zip. Unzip this file to a location where you want to maintain the INFINIWORKFLOW application, for example in your Documents folder.
python3 -c "import platform; print(platform.processor())"If that returns i386 then install the OSX x86_64 version of INFINIWORKFLOW version of OSX, otherwise if that returns arm then install the OSX arm64 version of INFINIWORKFLOW. Make sure you have a valid Python installation, as additional modules will be installed into the existing Python installation. It is recommended you have Python v3.12. To install, type sudo sh install.sh file in the unzipped folder, then type your password. The installation will install the required Python modules. The installation of Python modules will take around 5 minutes and requires network access, please let it run to completion before you proceed to the next step. After is is completed, to run INFINIWORKFLOW, type sh INFINIWORKFLOW.sh file in the unzipped folder.
A webpage displayed in the Google Chrome browser should appear - if another browser shows up then change your default browser to Chrome and redo this step. The first thing that will be displayed in the browser is the INFINIWORKFLOW EULA which you must agree to. You will also see a Windows dialog that requests "Do you want to allow public and private networks to access the app?" for Python - you must allow access.
When you install INFINIWORKFLOW and run it the first time, you may see a Windows dialog that requests "Do you want to allow public and private networks to access the app?" for Python - you must allow access. If this dialog does not pop up and INFINWORKFLOW does not show images in the viewer then you have to manually grant access to allow INFINIWORKFLOW's Python installation to have access to public and private networks as follows:
If your Firewall is controlled by your anti-virus software then you will need to allow access of INFINIWORKFLOW's python.exe using the anti-virus software.
| Name | OS | Description | Link |
|---|---|---|---|
| INFINIWORKFLOW SDK | SDK to allow you to write your own Python and C++ Plugins for INFINIWORKFLOW | infiniworkflow_sdk | |
| OpenCV Barcode Detection Inference | WeChat QRCode including CNN models for `wechat_qrcode` module, including the detector model and the super scale model | barcode | |
| Cityscapes Segmentation Training & Testing | Semantic Understanding of Urban Street Scenes | cityscapes | |
| Colorization Inference | Colorful Image Colorization | colorization | |
| Tracking Inference, DaSiamRPN | Formulates the task of visual tracking as a task of localization and identification simultaneously using DaSiamRPN algorithm | dasiamrpn | |
| Tracking Inference, Nano | Formulates the task of visual tracking as a task of localization and identification simultaneously using Nano Tracker algorithm | nano | |
| Edge Inference | Code for edge detection using pretrained hed model(caffe) using OpenCV | edge | |
| DexiNed Edge Inference | Code for edge detection using a model(ONNX) using a Convolutional Neural Network (CNN) | dexined | |
| Face Detect Inference using Haarcascades | Face Detect Inference using Haarcascades using OpenCV | haarcascades | |
| Human Face Segmentation | Human Face Segmentation | human | |
| Mask Segmentation Inference | Mask Segmentation | mask_rccn | |
| Person Reidentification Inference | Person REID Inference | personReiD | |
| MiDaS Depth Inference | MiDaS computes relative inverse depth from a single image | midas | |
| Hand and Body Pose Inference | OpenCV Hand and Body Pose Inference | pose | |
| Segmentation Inference | A Deep Neural Network Architecture for Real-Time Semantic Segmentation | segmentation | |
| Human Segmentation Inference | A Deep Neural Network Architecture for Real-Time Segmentation on Humans Specifically | human_seg_pp | |
| OpenCV Text Spotting Detection Inference | An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition | text_spotting | |
| YuNET Face Tracking and Facial Expressions Recognition Inference | A Light-weight, Fast, and Accurate face Detection Model, with Ability to Track Faces and Points on a Face and Perform Facial Expression Recognition | yunet | |
| UTKFace Dataset | UTKFace dataset is a large-scale face dataset with long age span | utkface | |
| YOLO5 Object Detection Inference |
A computer vision model that uses YOLO5 deep learning to detect objects in images and videos
Photron does not distribute YOLO5 as part of INFINIWORKFLOW, if you wish to use YOLO5, you must download it separately and agree to the license terms on your usage: YOLO5 LICENSE Additional steps: After installing the patch 1. Create a new directory in the assets folder: INFINIWORKFLOW_PATH/assets/yolo5 1. Download https://github.com/RsGoksel/Cpp-Object-Detection-Yolov5-OpenCV/releases/download/ONNX/yolov5s.onnx 2. Copy yolov5s.onnx to: INFINIWORKFLOW_PATH/assets/yolo5/yolov5s.onnx 3. Download https://github.com/RsGoksel/Cpp-Object-Detection-Yolov5-OpenCV/blob/main/Yolov5_Image_Object_Detection/Models/classes.txt 4. Copy classes.txt to: INFINIWORKFLOW_PATH/assets/yolo5/classes.txt |
yolo | |
| Custom YOLO3 |
A computer vision model using YOLO3 that allows you to customize and train as well as do inference
on the trained models
Photron does not distribute YOLO3 as part of INFINIWORKFLOW, if you wish to use YOLO3, you must download it separately and agree to the license terms on your usage: YOLO3 LICENSE After installing 1. Create a new directory in the assets folder: INFINIWORKFLOW_PATH/assets/yolov3 1. Download https://github.com/patrick013/Object-Detection---Yolov3/blob/master/model/yolov3.weights 2. Unzip file and copy yolov3.weights to: INFINIWORKFLOW_PATH/assets/yolov3/yolov3.weights 3. Download https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg 4. Copy yolov3.cfg to: INFINIWORKFLOW_PATH/assets/yolov3/yolov3.cfg |
custom_yolo3 | |
| YOLOX Inference | YOLOX is a high-performing object detector based on the YOLO series | yolox_inference | |
| Yahoo Finance API | Realtime Yahoo Finance quotes | yfinance | |
| Philips Hue | Trigger Philips Hue Lights | philips_hue | |
| Geo API | Geo and Geo Reverse | geopy | |
| Send Email | Send Email | send_email | |
| Blink1 | Blink1 LED Light | blink | |
| Upload Video | Upload Video | upload_video | |
| Live Stream | Live Stream | live_stream | |
| PyRender | PyRender - 3D Rendering | pyrender | |
| YouTube Reader | YouTube Reader | youtube_reader | |
| Livestream Chat | Livestream Chat | livestream_chat | |
| OpenNI Depth Sensor | OpenNI Depth Sensor | openni_depth_sensor_windows | |
| Mask 2 Former | A unified framework for panoptic, instance and semantic segmentation | mask2former | |
| ONNX Runtime | Accelrated C++ Inference engine for running ONNX models | onnx_runtime_windows | |
| YOLOX Train | YOLOX Train | yolox_train | |
| Audio |
Audio
Additional steps: After installing the patch 1. Download FFMPEG: https://ffmpeg.org/download.html 2. Place the ffmpeg executable in your path, or in external/bin folder |
audio | |
| Audio Classify | Audio Classify | audio_classify | |
| Database | Database | database | |
| Robot Operating System (ROS) |
A set of libraries that communicates data and actions across sensors and robotic devices.
Photron does not distribute ROS as part of INFINIWORKFLOW, if you wish to use ROS, you must download it separately and agree to the license terms on your usage: ROS2 LICENSE Additional steps: 1. Install ROS2: https://docs.ros.org/en/jazzy/Installation/Ubuntu-Install-Debs.html 2. Make sure you source the ROS environment: source /opt/ros/jazzy/setup.bash 3. Start INFINIWORKFLOW using LD_LIBRARY_PATH=$LD_LIBRARY_PATH:../external/bin/onnxruntime/:../external/bin/opencv2/:../external/bin/ python3 app.py |
ros2 | |
| RTCBot | RTCBot | rtcbot | |
| Serial | Serial | serial | |
| OCR | OCR | ocr |
There are three flavours of patches - one is a patch to the application, one is a SDK patch and the others are feature patches to allow installation of different demos and packages. See the Downloadable Packages for the full list. The application patch is meant to patch your exisiting installation with a smaller set of files and thus has a substantially smaller download size. It is expected that the application patch will be frequently updated when bugs are fixed and small features added. To patch your exisiting installation you should download the patch, and then open a Windows Powershell prompt and then change the directory to your existing INFINIWORKFLOW installation (i.e. where you unzipped your original installation). Then type the following where you should replace /folder/to/ to the actual folder you downloaded the application patch:
.\patch.bat /folder/to/infiniworkflow_patch_v1_0.zip
sh patch.sh /folder/to/infiniworkflow_patch_v1_0.zip
.\patch.bat /folder/to/yolo_v1_0.zip
sh patch.sh /folder/to/yolo_v1_0.zip
To ensure security, INFINIWORKFLOW provides the ability to check User Authentication before users may access the application. This is not enabled by default, but can be enabled easily by your administrator by running the following python script to create a INFINIWORKFLOW superuser:
cd /path/to/INFINIWORKFLOW/app
python3 create_superuser_script.py
With a superuser created, User Authentication is enabled. Now, when starting INFINIWORKFLOW, users will reach the login page (as seen below) and have to enter their login information to continue to INFINIWORKFLOW.
When a user is finished using Infiniworkflow, they may click "Yes" or "Save and Exit" to exit the application, or they may click "Logout", which saves the current workflow and logs out of the session, returning back to the login screen.
As an Admin, you will have extended permissions that regular users won't, which includes making and removing users and groups. To access these controls, click on the Admin link and enter your admin username and password to continue. You will then reach a page like this, with all of the Admin controls available.
You can start INFINIWORKFLOW from the command line. To successfully execute you need to change the current directory to the app folder located under INFINIWORKFLOW and then run the command:
Note, on OSX and Linux instead of using "..\python.exe", you should use "python3"
..\python.exe app.pyc [-help] [-device #] [-test ...] [-noncuda] [-batch] [-final node name or node uuid] [-override json] [-nobrowser] [-source ...] [-path ...] [-port ...] [-resolution ...] [-test ...] [workflow ....]
| Argument name | Description | Default Value | Example |
|---|---|---|---|
| -url | url the server will start on, if not specified starts on localhost | 127.0.0.1 | python app.py -url 192.168.5.52 |
| -device | allows you to set the default GPU device used | 0 | ..\python.exe app.pyc -device 1 |
| -noncuda | will switch to the non cuda based rendering | ..\python.exe app.pyc -noncuda |
|
| -batch | batch mode will not show UI | ..\python.exe app.pyc -batch |
|
| -final | if in batch mode you can set the final node that you wish to execute before you exit. Either pass in node name or node uuid | ..\python.exe app.pyc -final R2Score |
|
| -override | a json string that allows you to override attributes in the workflow you pass | ..\python.exe app.pyc -final "{'Set Int.value' : '5', 'Set Int1.value' : '11' }" |
|
| -help | shows a help message | ..\python.exe app.pyc -help" |
|
| -port | specify which network port to use, if none specified then 5000 is used | 5000 | ..\python.exe app.pyc -port 8888" |
| -nobrowser | does not automatically open a browser | ..\python.exe app.pyc -nobrowser" |
|
| -path | establishes paths that can be used as a prefix | ..\python.exe app.pyc -path "captures=C:\Users\imagi\CapturesFolder;media=C:\media" |
|
| -source | creates a workflow with a movie reader with this media | ..\python.exe app.pyc -path "media=C:\media_folder" -source media:movie.mp4 |
|
| -test | Sets the project resolution | ..\python.exe app.pyc -resolution 1920x1080 |
|
| -test | See Automated Testing | ..\python.exe app.pyc -test yolo |
|
| workflow | The final argument is the workflow json file | ..\python.exe app.pyc ..\demos\Untitled\Untitiled.json" |
Plugins can be implemented in C++ or Python and both will require a JSON file. The JSON Schema specifies the input and output parameters as well as the name and description of the plugin amongst other things.
To start creating your own plugin, it is recommended you base your code on the Canny2 plugin that is provided upon installation. For Windows users, you can immeadiately run the Canny2 plugin via the Visual Studios solution. For Mac and Linux users, the process of creating a plugin will require a few more steps. These steps are detailed below in the section "Creating Plugins for Mac/Linux"
A simple way to make your own tool without writing Python or C++ code is to simply use an existing tool and customize its parameters. You simply create an updated JSON for the tool and place it in the extensions folder. You can get the JSONs for the exisiting tools in the subfolders in the app/catalog folder. For example, say we want to customize the "Lift" Tool to create a new "Red Lift" Tool - this tool would allow the lift color correction but the default value for the red parameter would be higher. The steps are as follows:
"identifier": "red_lift:cv.color_lift",
"category": {
"id": "Color"
},
"icon": "bi-palette",
The category is in the "id" attribute in the app/catalog/toc.json. This will place the "Red Lift" tool in the exisiting Color tab of the
Catalog UI.
Alternatively, you can create a new category "id" and that will show up in the Catalog UI in a new tab.
All plugins must have an accompanying JSON file. The JSON file specifies the input and output parameters as well as the name and description of the plugin amongst other things. The specification of the schema is as follows:
| Attribute name | Mandatory | Default Value | Description | Example |
|---|---|---|---|---|
| title | The UI name of the plugin |
"title" : "Canny Edge Detector"Or you can specify a localized set "title": {
"en_US": "Canny Edge Detector",
"ja-JP": "キャニーエッジ検出器",
"es-ES": "Detector de bordes Canny",
"de_DE": "Canny Kantendetektor",
"zh_CN": "Canny 边缘检测器"
}
|
||
| identifier | The name of the plugin file |
Python:
"identifier": "day_of_week.py"C++: "identifier": "Canny2.plugin" |
||
| description | The description that explains the purpose of this plugin which will be shown in the UI |
"description" : "Canny Edge Detection is a popular edge detection algorithm"Or you can specify a localized set "description": {
"en_US": "Canny Edge Detection is a popular edge detection algorithm",
"ja-JP": "Canny Edge Detectionは人気のエッジ検出アルゴリズムです",
"es-ES": "Canny Edge Detection es un popular algoritmo de detección de bordes",
"de_DE": "Canny Edge Detection ist ein beliebter Kantenerkennungsalgorithmus",
"zh_CN": "Canny 边缘检测是一种流行的边缘检测算法"
}
|
||
| url | www.photron.com | A URL that is shown in the UI to have more information about the plugin |
"url": "https://docs.opencv.org/3.4/dd/d1a/group__imgproc__feature.html#ga04723e007ed888ddf11d9ba04e2232de" |
|
| tags | A list of tags that is associated with the plugin |
"tags": ["opencv", "edges", "canny"]Or you can specify a localized set: "tags": {
"en_US": ["opencv", "edges", "canny"],
"ja-JP": ["オープンCV", "エッジ", "賢い"],
"es-ES": ["abrircv", "bordes", "astuto"],
"de_DE": ["OpenCV", "Kanten", "schlau"],
"zh_CN": ["opencv", "边缘", "精明的" ]
}
|
||
| icon | "icon": "bi-heart-fill" |
A bootstrap icon that represents the plugin in the UI |
"icon": "bi-star" |
|
| category | The category the plugin will be placed in the Tool Catalog |
If you want to specify your own new category
"category": {
"id": "python_scripts",
"description": "User defined python scripts",
"icon": "bi-filetype-py"
}
If you want to place it in an exisiting category
"category": {
"id": "Photron"
}
|
||
| language | Must be either python, c++ or cuda |
"language": "c++" |
||
| gpu | "gpu": false |
Informs if CUDA GPU is recommended for execution |
"gpu": true |
|
| os | "os": ["windows", "osx", "linux"] |
Specifies if the plugin wants to limit which Operating Systems the plugin will be available |
"os": ["osx"] |
|
| supervise | "supervise": false |
Specifies if the plugin wants to handle supervion callbacks to enable/disable or hide/show parameters dynamically Note you must also set one of the input parameters to have a supervise attribute to be true which are the parameters that cause other parameters to change visibility |
"supervise": true |
|
| inputs | "inputs": [] |
An array of input objects that specifies each input of the plugin - see inputs schema |
"inputs": [
{
"name": "source",
"type": "image2D",
"mandatory": true,
"description":"Input image",
"identifier": "source"
},
{
"name": "threshold1",
"type": "double",
"default": "100.0",
"mandatory": true,
"description": "First threshold for the hysteresis procedure",
"identifier": "threshold1"
},
...
]
|
|
| outputs | "outputs": [] |
An array of output objects that specifies each output of the plugin - see outputs schema |
"outputs": [
{
"name": "out",
"type": "image2D",
"description": "Output edge map; single channels 8-bit image, which has the same size as image",
"identifier": "out"
}
]
|
|
| overlay | "overlay": [] |
An array of svg elements that are drawn in the viewer when the node is viewed, the markup has a special inputs attribute to specify the list of input parameters |
"overlay": [
"<polygon stroke='yellow' opacity='0.5' stroke-width='2' fill='none' inputs='src[0],src[1],src[2]' />",
"<polygon stroke='limegreen' opacity='0.5' stroke-width='2' fill='none' inputs='dst[0],dst[1],dst[2]' />"
]
|
| Attribute name | Mandatory | Default Value | Description | Example |
|---|---|---|---|---|
| name | The UI name of the input parameter |
"name" : "out"Or you can specify a localized set "name": {
"en_US": "out",
"ja-JP": "外",
"es-ES": "afuera",
"de_DE": "aus",
"zh_CN": "出去"
|
||
| identifier | The unique identifier for this input parameter |
"identifier": "out" |
||
| description | The description that explains the purpose of this output |
"description" : "Second threshold for the hysteresis procedure"Or you can specify a localized set "description": {
"en_US": "Second threshold for the hysteresis procedure",
"ja-JP": "ヒステリシス手順の2番目の閾値",
"es-ES": "Segundo umbral para el procedimiento de histéresis",
"de_DE": "Zweiter Grenzwert für das Hystereseverfahren",
"zh_CN": "滞后过程的第二个阈值"
}
|
||
| type | The type of the parameter which which include the standard types: int, double, int2, double2, bool, string, numeric, image2D, cuda2D. Or you can define your own type name. |
"type": "double" |
||
| mandatory | "mandatory": false |
Specifies if the input parameter is mandatory and must be set by the user. |
"mandatory": true |
|
| default | The default value of the input parameter which is must be enclosed in a string. No default values should be needed for types that are not set directly by the user e.g. image2D and cuda2D |
"default": "200.0" |
||
| min | Only for numeric types such as int or double. The minimum value the input value can be set to |
"min": 5.0 |
||
| max | Only for numeric types such as int/int2/int3 or double/double2/double3. The maximum value the input value can be set to |
"max": 10.0 |
||
| softmin | "softmin": false |
Only for numeric types such as int/int2/int3 or double/double2/double3 that are not sliders but textfields. If softmin is true then the limit is only via the dragging of the UI, if you enter manually in the textfield the limit does not apply |
"softmin": true |
|
| softmax | "softmax": false |
Only for numeric types such as int/int2/int3 or double/double2/double3 that are not sliders but textfields. If softmax is true then the limit is only via the dragging of the UI, if you enter manually in the textfield the limit does not apply |
"softmax": true |
|
| step | Only for numeric types such as int or double. The step value the increments of the parameter UI will jump up and down |
"step": 1.0 |
||
| permitted | Only for int or string types. An array of strings that will be in the selection UI menu or the tag selection UI | |||
| private | "private": false |
Will not show the parameter in the UI |
"private": true |
|
| editable | "editable": true |
If the parameter can be editable or not, if not editable it will be disabled in the UI |
"editable": false |
|
| multiple | "multiple": false |
Only for string types that will allow multiple values to entered in the tag UI |
"multiple": true |
|
| userOptionAllowed | "userOptionAllowed": false |
Only for string types that allow user defined strings to be entered in the tag UI |
"userOptionAllowed": true |
|
| look |
A hint to indicate how the UI should be represented instead of the default look
int types: button, slider int2, double2, numeric2: point string: map, filebrowser, curve, path, table, html, week, month, time, date, datetime-local |
"look": "button" |
||
| icon | "icon": "bi-fire" |
The icon for parameters that have a button look |
"icon": "bi-robot" |
|
| random | "random": false |
Only for color, int, int2, int3, double, double2, double3 types that ignores the default value and sets a random value instead |
"random": true |
|
| ganged | Only for int2, double2, numeric2 types that allows both the dimensions to be ganged and set to the same value |
"ganged": "button" |
||
| multiline | "multiline": false |
Only for string types that indicate if the UI should have a textarea or a single textfield widget |
"multiline": true |
|
| rows | Only for string types with a multiline set to true, indicates the number of rows of the textarea widget |
"rows": 5 |
||
| cols | Only for string types with a multiline set to true, indicates the number of columns of the textarea widget |
"cols": 10 |
||
| password | Only for string types to make the text now show when you enter text in the widget |
"password": true |
||
| supervise | "supervise": false |
Specifies when this parameter changes if you want to handle supervion callbacks to enable/disable or hide/show parameters dynamically. Note you must also set the supervise attribute of the main JSON object to true as well |
"supervise": true |
| Attribute name | Mandatory | Default Value | Description | Example |
|---|---|---|---|---|
| name | The UI name of the output parameter |
"name" : "threshold2"Or you can specify a localized set "name": "name": {
"en_US": "threshold2",
"ja-JP": "閾値2",
"es-ES": "umbral2",
"de_DE": "Schwelle2",
"zh_CN": "阈值2"
}
|
||
| identifier | The unique identifier for this output parameter |
"identifier": "threshold2" |
||
| description | The description that explains the purpose of this output |
"description" : "Output edge map; single channels 8-bit image, which has the same size as image"Or you can specify a localized set "description": {
"en_US": "Output edge map; single channels 8-bit image, which has the same size as image",
"ja-JP": "出力エッジマップ。画像と同じサイズの単一チャネル8ビット画像。",
"es-ES": "Mapa de borde de salida; imagen de 8 bits de canales individuales, que tiene el mismo tamaño que la imagen",
"de_DE": "Ausgabekantenkarte; Einzelkanal-8-Bit-Bild, das die gleiche Größe wie das Bild hat",
"zh_CN": "输出边缘图;单通道8位图像,与图像大小相同"
}
|
||
| type | The type of the parameter which which include the standard types: int, double, int2, double2, bool, string, map, numeric, image2D, cuda2D. Or you can define your own type name. |
"type": "image2D" |
The Python SDK uses the PythonNode base class and at a minimum you need to define a new instance which you should return in the result variable. The final plugin will be the python script and should be placed in the Extensions folder together with its JSON file. A simple example is the days_of_weeks.py sample plugin provided. The python code is as follows
from python_node import PythonNode
import datetime
class DayOfWeekNode(PythonNode):
def __init__(self):
super().__init__()
self.value = None
def execute(self, host):
if not host.is_enabled():
self.value = False
else:
year = host.get_input_int_value(0)
month = host.get_input_int_value(1)
day = host.get_input_int_value(2)
self.value = datetime.datetime.strptime(str(day) + "/" + str(month+1) + "/" + str(year), "%d/%m/%Y").strftime('%A')
host.set_output_value(0, self.value)
....
def copy(self, host):
return DayOfWeekNode()
result = DayOfWeekNode()
If you wish to instead use an existing Node but with a different JSON, e.g. you want to use the GenericDataset tool but set the parameters and hide them, then no code is needed any instead the result variable should return the identifier of the existing tool:
result = "torch.generic_loader"
However, using the Python API provides you full capability as long as you override the PluginApi class which requires 3 at least methods to be implemented: copy, execute and view_html. The following methods should be overriden by your derived class of PluginApi
| Instance method | Mandatory | Arguments | Return type | Purpose |
|---|---|---|---|---|
| copy | self, host : PluginHost |
instance of this plugin class |
This method will be called when INFINWORKFLOW requests a copy of an instance of this class which should return a deep copy. | |
| execute | self, host : PluginHost |
None |
The method called when the plugin is executed usually when some input parameters have changed. You can call the host to get input values, e.g. host.get_input_int_value(...), and finally set the output value. If the execution was unsuccessful then you can call host.set_error_message with the error message If you want to have the node to be executed you can call host.set_dirty(True) otherwise the node will only get re-executed when input parameters have been modified | |
| view_html | self, host : PluginHost, nth_output : int |
string |
The method is called after the execute method, when the output of node is viewed The view_html should return a html string that represents the output of the nth output. Typically, in the execute method you can compute output values and store them in instance variables of the class and then later in the view_html you can use those values to establish what HTML string you will pass back. | |
| has_dynamic_inputs | self, host : PluginHost |
bool |
Returns if the plugin has dynamic inputs, defaults to False | |
| has_dynamic_outputs | self, host : PluginHost |
bool |
Returns if the plugin has dynamic outputs, defaults to False | |
| allows_inference_macro | self, host : PluginHost |
bool |
Returns if if the node allows inference macros to be created | |
| update_inference_macro_json | self, host : PluginHost, tool_json : dict |
None |
Updated the Tool JSON for the inference macro | |
| get_macro_identifier | self, host : PluginHost |
str |
Gets the base macro for the inference tool generation | |
| reset_trigger_counters | self, host : PluginHost, nth_index : int |
None |
The trigger at the nth index should reset any internal state that you maintain | |
| get_adornment | self, host : PluginHost, output_port_num : int, output_type : str |
None |
Returns the adornment in the UI, returning "1" adds the slicing adornment |
The methods for PluginApi have a instance of PluginHost, the host, which is a helper class that allows you to call INFINIWORKFLOW related functions. The execute method should for example call the methods to get input values (e.g. get_input_int_value) and set the output value (i.e. set_output_value). The following methods should can be called on the PluginHost
| Instance method | Purpose | Example |
|---|---|---|
| get_input_value | During exeuction you can get the value of an input to the plugin, where you pass the order of the parameter E.g. pass 0 for the first input parameter | value = host.get_input_value(3) |
| get_input_bool_value | A helper method that calls get_input_value and returns the value as a bool Python type | value = host.get_input_bool_value(3) |
| get_input_int_value | A helper method that calls get_input_value and returns the value as a int Pythontype | value = host.get_input_int_value(3) |
| get_input_numeric_value | A helper method that calls get_input_value and returns a float, int or bool Python type | value = host.get_input_numeric_value(3) |
| get_input_string_value | A helper method that calls get_input_value and returns a str Python type | value = host.get_input_string_value(3) |
| get_input_filename_value | A helper method that calls get_input_value and returns a str Python type and resolves the path (replacing the ${assets} with the correct path) | value = host.get_input_filename_value(3) |
| get_input_map_value | A helper method that calls get_input_value and returns a dict Python type | value = host.get_input_map_value(3) |
| get_input_bool_list_value | A helper method that calls get_input_value and returns a list of bool Python type | value = host.get_input_bool_list_value(3) |
| get_input_numeric_list_value | A helper method that calls get_input_value and returns a list of float, int or bool Python type | value = host.get_input_numeric_list_value(3) |
| get_input_string_list_value | A helper method that calls get_input_value and returns a list of str Python type | value = host.get_input_string_list_value(3) |
| set_output_value | During exeuction you can set the value of an output to the plugin, where you pass the order of the parameter and the value E.g. pass 0 for the first input parameter This also will set the dirty flag to False (see set_dirty) | host.set_output_value(0, result) |
| set_dirty | During exeuction you can set if the node has been executed by setting dirty flag to False. This is automatically set when you set the outputs but you can set it to True if you want to have the node get executed again | host.set_dirty(True) |
| get_num_inputs | Returns the number of inputs that plugin has | value = host.get_num_inputs() |
| get_num_outputs | Returns the number of outputs that plugin has | value = host.get_num_outputs() |
| set_error_message | Sets an error message that will be shown in the UI | host.error_message("Something bad happened") |
| is_enabled | Returns if the node is enabled | value = host.is_enabled() |
| is_cancel_render | Returns true if the user has pressed cancel during the execution, in which case you should return from execution | value = host.is_cancel_render() |
| convert_filepath_to_relative_path | Returns the argument path from an absolute path to relative path i.e. will prefix the path with ${assets} as appropriate | updated_path = host.convert_filepath_to_relative_path(path) |
| get_source_time | Returns the source time depending on where the source originated from upstream e.g. if the source is from a Movie it will be frame number or if it is a web camera then it will be the epoch time | source_time = host.get_source_time(path) |
| set_source_time | Sets the source time, all further downstream nodes will inherit this time | host.get_source_time(source_time) |
| is_triggered | Returns if the trigger parameter at the nth input has been triggered or not | host.is_triggered(counter, nth_index) |
| get_view_slice | Returns the view slice value in viewer | host.get_view_slice() |
The C++ SDK is based on compiling a DLL using some standard headers and libraries provided in the INFINIWORFLOW SDK patch package. You can use the exisiting Canny2 example as a starting point and rename all the files to your plugin name. The final plugin will be a DLL but prefixed with the .plugin extension and should be placed in the Extensions folder together with its JSON file. The SDK is based on Microsoft Visual Studio 2022 and only supports x86_64 builds.
The following methods should be overriden by your derived class of PluginApi
| Instance method | signature | Purpose |
|---|---|---|
| setup | bool setup(PluginHost * host); |
Setup a Plugin and will be called anytime the thread to run the plugin is started |
| update | bool update(PluginHost * host, BlobHandle blob, int inputIndex); |
Update the Plugin instance based on a change of the input blob This will be called anytime the user changes a property, the inputIndex is the index into the "inputs" array in the JSON representing the parameters Typically you can copy the value of the contents of the Blob instance (using the host API such as getAsDouble) and then copy this into your plugin instance |
| superviseInputs | bool superviseInputs(PluginHost * host, int* inputsFlags); |
Called if the plugin sets "supervise" in the JSON and will allow you to enable/disable and/or hide or show parameters The inputsFlags is an array that is the size of the number of inputs and you are responsible to set the values You can set the flags SUPERVISE_FLAG_NORMAL (0) to have it shown regularly Or set it to the flag SUPERVISE_FLAG_HIDDEN (1) to have it hidden Or set it to the flag SUPERVISE_FLAG_DISABLED (2) to have it disabled |
| execute | bool execute(PluginHost * host); |
Execute a Plugin - you can call the pluginGetOutputBlob to get the output blob Return true if success or false otherwise |
| isCached | bool isCached(PluginHost * host); |
Asks node if it has cached any blob values inits instance variables If so then the host may call flushCache |
| flushCache | bool flushCache(PluginHost * host); |
Asks node to flush its cache - anything it has stored must be released For example, if you have cached the image as a Mat then release it |
| teardown | bool teardown(PluginHost * host); |
Teardown called anytime the thread to run the plugin is stopped |
| destroy | bool destroy(PluginHost * host); |
Destroy a Plugin which is you can destroy your plugin instance data |
The following methods should can be called on the PluginHost that is passed into the API methods of PluginApi
| Signiture | Purpose |
|---|---|
| BlobHandle getOutputBlob(int outputNum) | Get the Output Blob handle which can be callied during the executePlugin call, the outputNum is the index into the "outputs" array in the JSON representing the output |
| void setNumOutputs(int numOutputs) | Sets the number of outputs the blob supports and can be called during makePlugin |
| void setErrorMessage(const char *message) | Notifies an error has occurred which will be shown in the UI |
| void isEnabled() | Checks if the node is enabled, if not then the plugin should usually just copy source to output |
| bool hasOutputObservers(int outputIndex) | Returns if the output is currently connected - only render the output if it has observers |
| cv::Mat& getAsImage2D(BlobHandle blob) | From the blob handle get the reference to a two dimensional image represented by OpenCV matrix |
| cv::Mat& getAsMatrix2D(BlobHandle blob) | From the blob handle get the reference to a two dimensional matrix represented by OpenCV matrix |
| double &getAsDouble(BlobHandle blob) | From the blob handle get the double value it represents |
| int &getAsInt(BlobHandle blob) | From the blob handle get the int value it represents |
| bool &getAsBool(BlobHandle blob) | From the blob handle get the bool value it represents |
| std::string &getAsString(BlobHandle blob) | From the blob handle get the string value it represents |
| std::string &getAsFilename(BlobHandle blob) | From the blob handle get the filename value it represents, resolving the prefix ${assets} |
| double *getAsDouble2(BlobHandle blob) | From the blob handle get the 2D double point value it represents |
| int *getAsInt2(BlobHandle blob) | From the blob handle get the 2D integer point value it represents |
| float *getAsColor3f(BlobHandle blob) | From the blob handle get the color RGB value it represents |
| void cloneFromImage(BlobHandle blob, cv::Mat& dest) | From the blob handle gets a cloned copy (which may be opencv mat or cuda memory) |
As with the C++ SDK instructions, you can use the exisiting Canny2 example as a starting point and rename all the files to your plugin name. See the section above for instructions on how to do this.
With your JSON now set up, you will need to construct the CMakeLists.txt file for your plugin. Open Canny2's CMakeLists.txt for reference. In your plugin's CMakeLists.txt file, rename any instance of "canny2" to the name of your plugin. Everything else should be kept the same.
In your console, "cd" into the folder containing your plugin. For Canny2, this is in "infini-workflow/sdk/examples/Canny2". Once you are in this folder in your console, enter the following command to build x86_64 architecture:
cmake -B build . -G "Unix Makefiles"For arm64 architecture enter the following command to build x86_64 architecture:
cmake -DCMAKE_VS_PLATFORM_NAME="arm64" -B build . -G "Unix Makefiles"This will create a folder called "build" within the directory you are currently in. Then enter the following commands:
cd build makeThis should output a few lines of text, with the last one being "[100%] Built target {NAME_OF_PLUGIN}". Now when you run INFINIWORKFLOW on a Mac or Linux device, the plugin will be available and usable.
To perform automated testing you will need to create a directory "tests" and in this directory place a json test script called "tasks.json". For example, if your test was called "assembly_line", then create a folder "tests/assembly_line" under INFINIWORKFLOW main installation folder. Then place any expected results in the folder "tests/assembly_line/expected_results" that will be used in the "assertEquals" task (see JSON testing schema below for details) To start testing, open a terminal/powershell and change the current directory to the app folder located under INFINIWORKFLOW and then run the command:
..\python.exe app.pyc -test assembly_line
Note, on OSX and Linux instead of using "..\python.exe", you should use "python3"
The terminal will show the results of the test. For example:
assert: YOLO5 Classification:numDetects expected 11 but got 10 assert: YOLO5 Classification:preview expected rmse 0.1 bit got 0.16262965760694073 exit_tests... test summary: 0 out of 2 pass
Each assert you do in your test will result in saving a file to a subfolder "actual_results", for example, in the assembly_line example described above, the actual result files will be in the subfolder "tests/assembly_line/actual_results"
The format of the JSON schema will is as an array of tasks, for example:
{
"tasks": [
{
"name": "showMessage",
"message": {
"en_US": "First, start with the Yolo demo"
},
"delay": 1000
},
{
"name": "assertEquals",
"node_name": "YOLO5 Classification",
"output_port": "numDetects",
"expected_value": 10
},
{
"name": "assertEquals",
"node_name": "YOLO5 Classification",
"output_port": "preview",
"expected_rmse": 0.1
},
{
"name": "exitTests",
"delay": 0
}
],
"workflow": "${demos}/Artificial Intelligence/Inference/Yolov5/yolov5.json",
"on_error": "exit",
"verbose": true
}
If you want to start the test by loading a workflow then include the "workflow" attribute that should be set to the workflow that will be loaded at the start of testing
If you want to exit testing if an assertion error occurs, then set the "on_error" attribute to "exit", otherwise set it to "continue" and it will continue further processing of the test even after an error has occurred.
Set the verbose attribute to true to see the results of the outputs of the testing in the terminal.
All testing should end with the task "exitTasks". The tasks allow you to do all the functionality you as the user can do with your mouse and keyboard - instead it is driven by your tasks in your script. The tasks are described as follows
| Name | Description | Other Attributes | Example | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| showMessage | Shows a message in the bottom tooltip window |
|
{
"name": "showMessage",
"message": "First, start with the Yolo demo",
"delay": 1000
}
|
||||||||||||||||||
| hideMessage | Hides a message in the bottom tooltip window |
|
{
"name": "hideMessage",
"delay": 1000
}
|
||||||||||||||||||
| printOutput | Prints the value of a node's output to the info dialog |
|
{
"name": "printOutput",
"node_name": "Yolo",
"output_port" : "out",
"delay": 1000
}
|
||||||||||||||||||
| assertEquals | Asserts a node output value will be expected to be some value The actual result will be saved in the actual_results folder and compared against the file in the expected_results |
|
{
"name": "assertEquals",
"node_name": "Classification",
"output_port" : "numDetects",
"delay": 1000
}
In this case the file comparison will be "Classification_numDetects.png" For matrix2D output types, the file is saved in csv format otherwise all other cases it is saved in a text (.txt) file" If you specify the "prefix" attribute, then the file name is prefixed with this value |
||||||||||||||||||
| saveOutputImage | Saves the output image for a node's output |
|
{
"name": "saveOutputImage",
"node_name": "Yolo",
"output_port" : "preview",
"path" : "output.png",
"delay": 1000
}
|
||||||||||||||||||
| saveOutputMatrix | Saves the output matrix for a node's output |
|
{
"name": "saveOutputMatrix",
"node_name": "Yolo",
"output_port" : "out",
"path" : "output.png",
"delay": 1000
}
|
||||||||||||||||||
| exitTests | Exits INFINIWORKFLOW and prints the test summary in the console |
|
{
"name": "exitTests"
}
|
||||||||||||||||||
| addNode | Adds a node from the catalog to the workflow |
|
{
"name": "addNode",
"tool_id": "cv.movie_reader",
"mandatory_params": [
"$\{assets\}/city.mp4"
],
"node_name": "Movie Reader",
"duration": 180,
"delay": 1000
}
|
||||||||||||||||||
| delay | Wait a delay before proceeding to next task |
|
{
"name": "delay",
"amount": 180,
"delay": 1000
}
|
||||||||||||||||||
| addLink | Adds a link from the output of one node to the input of another node |
|
{
"name": "addLink",
"from_name": "Movie Reader",
"from_port": "out",
"to_name": "Yolo Classifier",
"to_port": "source",
"duration": 300,
"delay": 1000
}
|
||||||||||||||||||
| removeLink | Remove a link from the output of one node to the input of another node |
|
{
"name": "removeLink",
"from_name": "Movie Reader",
"from_port": "out",
"to_name": "Yolo Classifier",
"to_port": "source",
"duration": 300,
"delay": 1000
}
|
||||||||||||||||||
| openViewer | Displays the node's output in the viewer |
|
{
"name": "openViewer",
"node_name": "Movie Reader",
"output_name": "out",
"duration": 300,
"delay": 1000
}
|
||||||||||||||||||
| closeViewer | Closes the viewer |
|
{
"name": "closeViewer",
"delay": 1000
}
|
||||||||||||||||||
| insertInput | Inserts an input to a node |
|
{
"name": "insertInput",
"node_name": "And",
"duration": 300,
"delay": 1000
}
|
||||||||||||||||||
| removeInput | Removes an input to a node |
|
{
"name": "removeInput",
"node_name": "And",
"duration": 300,
"delay": 1000
}
|
||||||||||||||||||
| openEditor | Displays the node's output in the editor |
|
{
"name": "openEditor",
"node_name": "Movie Reader",
"duration": 300,
"delay": 1000
}
|
||||||||||||||||||
| closeEditor | Closes the editor |
|
{
"name": "closeEditor",
"delay": 1000
}
|
||||||||||||||||||
| editParameter | Changes the value of the input of an edited node |
|
{
"name": "editParameter",
"node_name": "Yolo Classifier",
"input_name": "filter",
"value": "car",
"duration": 300,
"delay": 5000
}
|
||||||||||||||||||
| openPointOverlay | Opens the edited input parameter point in the overlay |
|
{
"name": "openPointOverlay",
"node_name": "Tracker Inference",
"input_name": "center",
"duration": 300,
"delay": 1000
}
|
||||||||||||||||||
| clickTrigger | Clicks the trigger button of the edited input parameter |
|
{
"name": "clickTrigger",
"node_name": "Tracker Inference",
"input_name": "start_stop",
"duration": 200,
"delay": 1000
}
|
||||||||||||||||||
| openRenderStatus | Opens the render status window |
|
{
"name": "openRenderStatus",
"duration": 200,
"delay": 1000
}
|
||||||||||||||||||
| closeRenderStatus | Closes the render status window |
|
{
"name": "closeRenderStatus",
"duration": 200,
"delay": 1000
}
|
||||||||||||||||||
| abortRenderStatus | Aborts the render in the render status window |
|
{
"name": "abortRenderStatus",
"duration": 200,
"delay": 1000
}
|
||||||||||||||||||
| nextVisualization | Goes to the next visualization of the matrix in the viewer |
|
{
"name": "nextVisualization",
"duration": 200,
"delay": 1000
}
|
||||||||||||||||||
| importWorkflow | Goes to the next visualization of the matrix in the viewer |
|
{
"name": "importWorkflow",
"workflow": "${demos}/Artificial Intelligence/PyTorch/CIFAR Classification/CIFAR Test/cifar test.json",
"delay": 1000
}
|
||||||||||||||||||
| clearWorkflow | Clears the workflow |
|
{
"name": "clearWorkflow",
"delay": 1000
}
|
||||||||||||||||||
| zoomFit | Zooms the workflow viewport around the selected nodes |
|
{
"name": "zoomFit",
"delay": 1000
}
|
||||||||||||||||||
| selectNode | Selects a node in the workflow |
|
{
"name": "selectNode",
"node_name" : "Add",
"delay": 1000
}
|
||||||||||||||||||
| togglePlay | Toggles the playback between paused and playing |
|
{
"name": "togglePlay",
"duration": 1000,
"delay": 2000
}
|
||||||||||||||||||
| firstFrame | Goes to the first frame |
|
{
"name": "firstFrame",
"duration": 1000,
"delay": 2000
}
|
||||||||||||||||||
| previousFrame | Goes to the prior frame |
|
{
"name": "previousFrame",
"duration": 1000,
"delay": 2000
}
|
||||||||||||||||||
| nextFrame | Goes to the next frame |
|
{
"name": "previousFrame",
"duration": 1000,
"delay": 2000
}
|
||||||||||||||||||
| lastFrame | Goes to the last frame |
|
{
"name": "lastFrame",
"duration": 1000,
"delay": 2000
}
|
||||||||||||||||||
| setCurrentFrame | Sets the current frame |
|
{
"name": "setCurrentFrame",
"frame": 10",
"duration": 1000,
"delay": 2000
}
|
||||||||||||||||||
| click | Clicks on a HTML element |
|
{
"name": "click",
"id": "#publish-workflow",
"duration": 1000,
"delay": 2000
}
|
||||||||||||||||||
| pan | Pans the viewport of the workflow |
|
{
"name": "pan",
"dx": 0,
"dy": 200,
"delay": 100
}
|
||||||||||||||||||
| openHyperparameters | Opens the Hyperparameter dialog for a node |
|
{
"name": "openHyperparameters",
"node_name" : "Logistic Regression",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| closeHyperparameters | Closes the Hyperparameter dialog |
|
{
"name": "closeHyperparameters",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| startGridSearch | Starts a grid search for a node |
|
{
"name": "startGridSearch",
"node_name" : "R2 Score",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| openGridSearch | Opens the Grid Search dialog |
|
{
"name": "openGridSearch",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| closeGridSearch | Closes the Grid Search dialog |
|
{
"name": "closeGridSearch",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| optimizeGridSearch | Selects to optimize in the Grid Search dialog |
|
{
"name": "optimizeGridSearch",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| openCreateMacro | Opens the Create Macro Dialog |
|
{
"name": "openCreateMacro",
"node_name" : "Sequential",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| setMacroName | Sets the Macro name in the Create Macro Dialog |
|
{
"name": "macroName",
"macroName" : "MY CIFAR",
"delay": 100
}
|
||||||||||||||||||
| closeCreateMacro | Closes the Create Macro Dialog and creates the macro |
|
{
"name": "closeCreateMacro",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| mergeCpuThreads | Merges the nodes into same CPU thread |
|
{
"name": "mergeCpuThreads",
"node_name" : "Canny",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| splitCpuThreads | Splits the nodes into into different CPU threads |
|
{
"name": "splitCpuThreads",
"node_name" : "Canny",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| setCudaDevice | Sets the CUDA device for a node |
|
{
"name": "setCudaDevice",
"node_name" : "Brightness",
"duration": 200,
"delay": 100
}
|
||||||||||||||||||
| escapeToClose | Press the escape key to close any open dialog |
|
{
"name": "escapeToClose",
"delay": 100
}
|
||||||||||||||||||
| showImageUrl | Shows an image in a popup window |
|
{
"name": "showImageUrl",
"url": "https://www.mdpi.com/sensors/sensors-19-04933/article_deploy/html/images/sensors-19-04933-g001.png",
"duration": 4000,
"width": 800,
"height": 800,
"delay": 1000
}
|
||||||||||||||||||
| showWebpage | Shows an webpage in a popup iframe |
|
{
"name": "showWebpage",
"url": "https://docs.opencv.org/4.x/da/d22/tutorial_py_canny.html",
"duration": 4000,
"width": 800,
"height": 800,
"delay": 1000
}
|